炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
vivo AI Lab發布AI多模態新模型了,專門面向端側設計,緊湊高效~
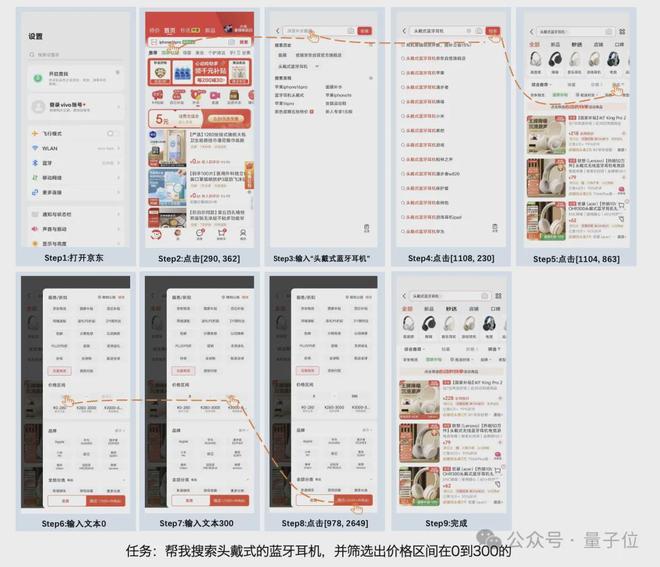
能夠直接理解GUI頁面的那種:
模型BlueLM-2.5-3B,融合文本和圖文的理解和推理能力,支持長短思考模式自由切換,並引入思考預算控制機制。
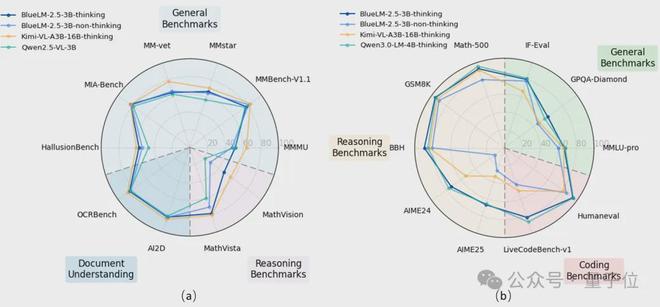
與同尺寸模型相比,BlueLM-2.5-3B在多個文本與多模態評測任務中表現出色。
BlueLM-2.5-3B支持思考預算控制(thinking token budget),有效平衡思考深度和推理成本:

兼具多模態推理和文本的推理能力,思考範圍擴展:

另外值得一提的是,作者對模型結構與訓練策略進行了深度優化,顯著降低了訓練和推理成本。通過優質數據篩選、自動配比策略以及大規模推理合成數據,模型的數據利用效率大幅提升。
同時,模型訓練全過程由自建的高性能訓練平台與框架高效支撐,確保了訓練效率和訓練穩定性。
以下是更多細節。
BlueLM-2.5-3B在20餘項評測任務中展現出如下核心優勢:
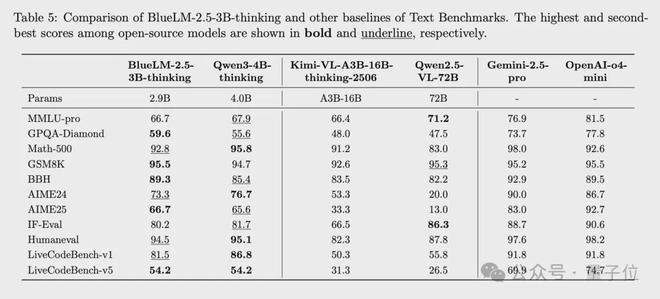
1、文本任務表現出色,緩解能力遺忘難題
BlueLM-2.5-3B在thinking、non-thinking不同模式下,在文本任務上與同規模文本模型Qwen3-4B效果相近,領先於同規模以及更大規模的多模態模型
這主要得益於數據策略以及訓練策略較好地緩解了困擾多模態模型訓練的文本能力遺忘難題。
thinking模式下,與4B以下同規模具有思考模式的文本模型Qwen3-4B-thinking相比,BlueLM-2.5-3B除代碼類任務外其他大部分文本任務效果相近;與同規模多模態模型如Qwen2.5-VL-3B相比指標全面領先;與更大規模的具有思考模式的多模態模型Kimi-VL-A3B-16B-thinking相比,文本效果全面領先。
thinking模式下推理類任務(如Math-500、GSM8K、AIME)效果也顯著優於更大規模的沒有thinking模式的模型如 Qwen2.5-VL-72B。
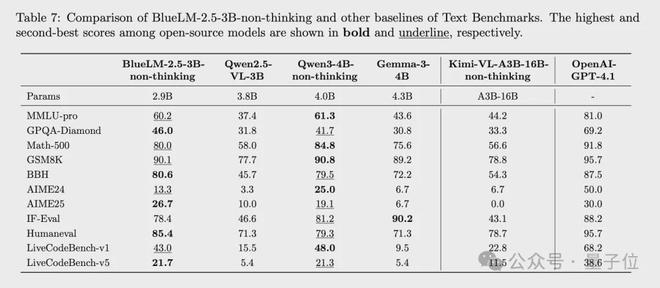
non-thinking模式下,與同規模文本模型Qwen3-4B-non-thinking相比,文本效果相當。
明顯優於同規模多模態模型Qwen2.5-VL-3B、Gemma3-4B,其中推理類任務如Math-500、BBH、AMIE24、AIME25優勢更為明顯。
與更大規模多模態模型Kimi-VL-A3B-16B-non-thinking 相比全部指標均更優,尤其是推理類任務的優勢更明顯。
2、多模態理解能力領先同規模模型
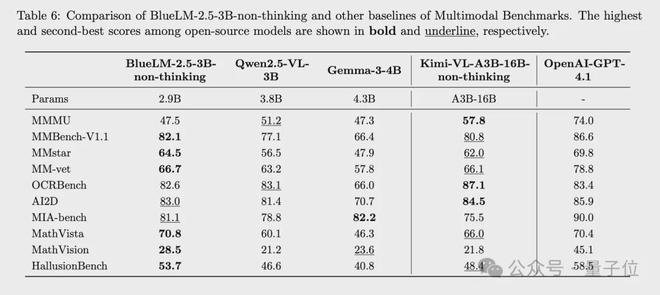
BlueLM-2.5-3B在thinking、non-thinking不同模式下,在多模態任務上領先於同規模多模態模型,與更大規模的多模態模型效果相近
thinking模式下,與更大規模模型Kimi-VL-A3B-16B-thinking相比,大多數評測任務的差距在5%以內;在推理相關任務如MathVista和MathVision的效果優於沒有thinking模式的Qwen2.5-VL-72B。
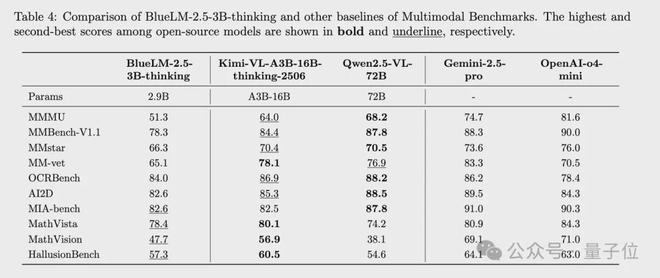
non-thinking模式下,與同規模模型Qwen2.5-VL-3B相比,指標全面領先,其中推理類任務Mathvista、Mathvision優勢明顯;與Gemma-3-4B相比效果更優;與更大規模模型Kimi-VL-A3B-16B-non-thinking相比,超過半數指標領先,其餘指標差距在5%以內;與行業領先模型相比,一半左右評測集差距在5%以內。
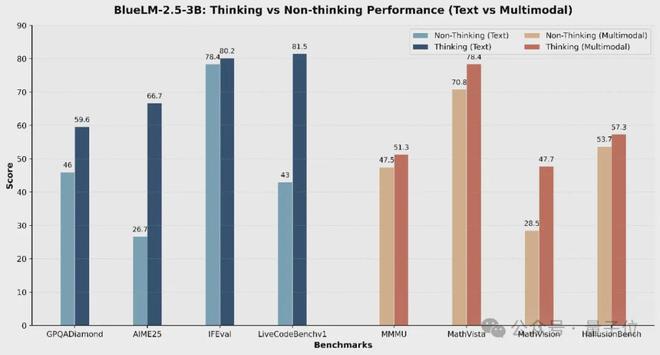
3、同時支持文本和多模態的長短思考以及思考預算控制
上述評測結果顯示,BlueLM-2.5-3B 同時具備了文本與多模態的thinking 模式。長思考模式顯著提升複雜推理任務上的模型效果。
例如,在AIME25 任務中thinking模式較之non-thinking 模式提高達40分,在MathVision 任務中提高達19.2分。
4、GUI理解能力領先同規模模型
與同規模模型相比,BlueLM-2.5-3B在GUI grounding指標上全面領先,例如ScreenSpot、ScreenSpot V2、ScreenSpot Pro的得分均超過了Qwen2.5-VL-3B和UI-TARS-2B。
與更大規模模型如Qwen2.5-VL-7B、UI-TARS 7B相比存在一定差距。得益於採集標註了大量中文app截屏數據,在中文評測集ScreenSpot vivo得分高於其他模型。

為支撐模型上述效果,BlueLM-2.5-3B設計了精巧緊湊的模型結構和高效的訓練策略。
模型結構
BlueLM-2.5-3B面向端側部署,參數量僅2.9B,比同規模的模型如Qwen2.5-VL-3B小22%以上,具有訓練和推理的成本優勢。
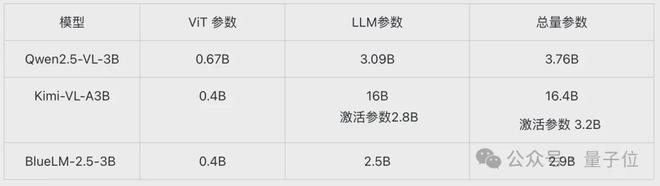
BlueLM-2.5-3B模型由ViT、Adapter、LLM組成。如圖所示:
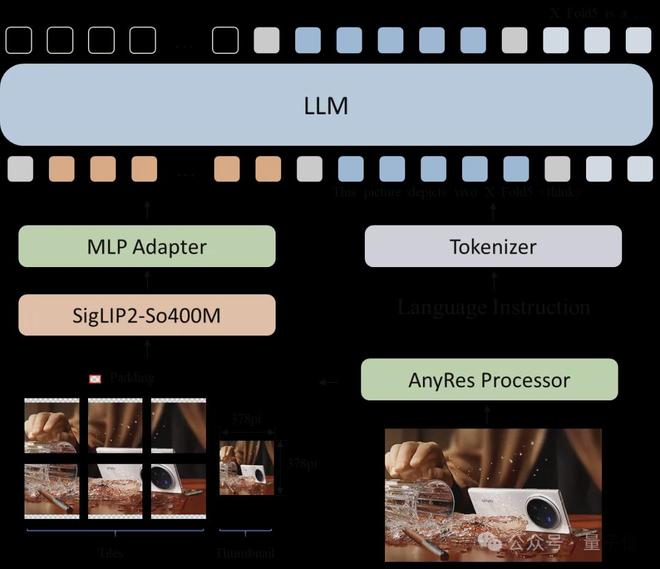
ViT採用400M參數量的SigLIP2(so400m-patch14-384)。 採用AnyRes方案支持動態分辨率,最大圖像輸入1512×1512。切完子圖後,固定長度token便於端側部署,且子圖並行推理,推理耗隨輸入token數量線性增長。此外,小尺寸ViT也有助於進一步降低功耗。
圖像token經Adapter投影后接入LLM Decoder。
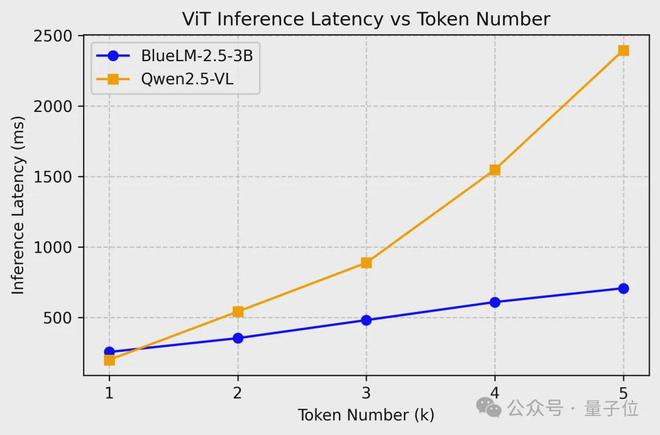
下圖展示了BlueLM-2.5-3B優秀的ViT推理性能:
預訓練策略
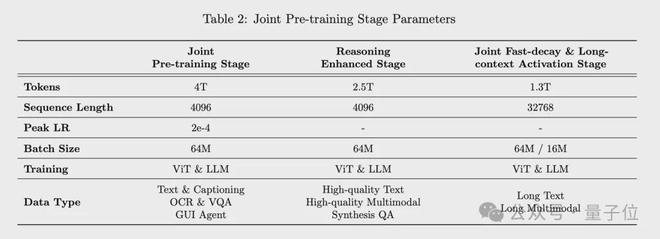
文本和多模態的預訓練共分為4個階段:
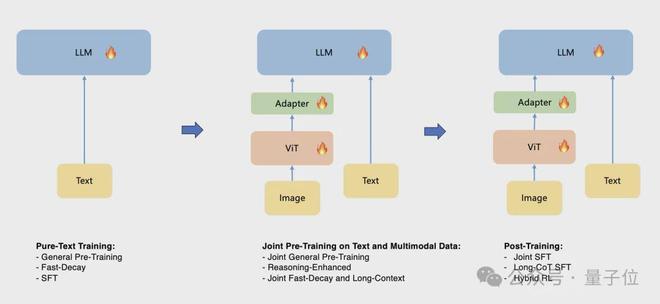
1、文本數據預訓練策略(Pure-Text Pre-training Stage)
LLM Decoder參數採用文本模型初始化。文本模型採用了「大模型裁剪+蒸餾」的三階段訓練策略,包括普通預訓練(General Pre-training)、快速衰減(Fast-Decay, FD)和微調(SFT)。
首先訓練7B教師模型並裁剪得到3B文本模型,再繼續用3T tokens蒸餾預訓練以及300B tokens FD蒸餾訓練。
相比從零訓練的同尺寸模型,性能提升超 4%。
2、文本和圖文數據聯合預訓練(Joint Pre-training Stage)
先凍結ViT和LLM參數,利用2.5M條圖文對數據訓練Adapter;再解凍全參數進行全量訓練。
通過設定64M的大batch size、統一12T tokens全局學習率衰減調度及對ViT的分層學習率控制,有效提升了訓練效率與穩定性。
這一階段,作者實現了訓練流程簡化,省略了一般方案中ViT+Adapter的單獨訓練階段,直接全量訓練。
3、推理增強數據的繼續訓練(Reasoning-Enhanced Stage)
作者在文本數據中提升STEM、編程、邏輯推理以及高質量合成數據的佔比。
合成數據覆蓋了短COT和長COT數據。在多模態數據中引入大量高質量的推理相關的圖文問答對。這一階段共使用2.5T tokens數據。
將文本任務的推理增強訓練後置到多模態階段,有效避免了文本推理能力遺忘,提升了訓練效率。
4、快速衰減與長文聯合訓練(JointFast-decay and Long-context Activation Stage)
快速衰減階段同時進行長文訓練。位置編碼從 Rope調整為 Yarn。
這一階段使用1.3T tokens,序列長度從4K擴展到32K。通過逐步將原生長文和高質量長推理數據佔比增至80%以上、減小Global Batch Size,有效提升模型的長思考能力。
後訓練策略
BlueLM-2.5-3B的後訓練分為2個階段:
1、SFT訓練
SFT階段將文本與多模態任務聯合微調,引入特殊token [|BlueThink|] 控制思考模式是否觸發。這一階段序列長度保持為32K。根據學習難度差異,作者將常規COT數據訓練3 epoch,長COT數據訓練9 epoch。
2、RL訓練
RL階段混合使用了基於人類偏好反饋的強化學習(RLHF)方法和基於可驗證獎勵的強化學習(RLVR)方法,使用GRPO算法進行優化。
開放問答類任務,使用RLHF方法。對文本寫作、總結等任務,使用生成式獎勵模型從相關性、準確性、有用性、冗餘性維度進行打分優化;而模型安全能力的提升,則使用判別式獎勵模型進行優化。
對有明確答案或評測標準的任務,如數學、代碼等推理相關任務,使用RLVR方法。作者使用規則結合verify模型進行正確性打分,最終獎勵分數綜合考慮答案正確性、格式正確性和重複情況和長度,其中為了優化模型「過度思考」的問題,作者引入「Group Overlong」的長度懲罰機制。
高質量訓練數據
模型性能背後離不開高質量訓練數據的支持。BlueLM-2.5-3B的訓練數據有如下特點:
1)相較於同規模模型如Qwen2.5-VL-3B,預訓練數據總量減少了約23%,這主要得益於對文本模型訓練數據的有效壓縮。文本模型訓練數據僅為Qwen3-4B 的25%、Qwen2.5的48%。
2)BlueLM-2.5-3B的多模態預訓練數據顯著多於其他模型,主要因為文本推理能力訓練後置合併到多模態訓練階段。累計引入3.3T tokens推理增強數據,為小模型具備較強推理能力奠定了堅實的數據基礎。
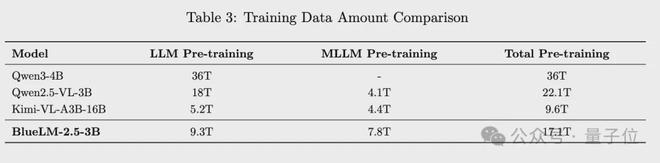
文本預訓練數據
文本模型預訓練階段共計使用9.3T tokens,其中6T tokens用於教師模型訓練,3.3T tokens 用於學生模型的蒸餾訓練。
多模態預訓練數據
多模態模型的預訓練數據為4T tokens,涵蓋Image Caption、OCR、GUI、純文本以及其他類型數據。其中純文本1.6T,圖文對2.4T。通過將文本數據佔比提升至40%,有效緩解了多模態預訓練階段文本能力遺忘問題。
另外,從預訓練階段開始就引入GUI等業務相關數據,有效提升基模在業務場景的能力上限。
推理訓練數據
作者構建兩階段的數據合成pipeline生產大規模推理數據,第一階段通過多種途徑獲取原始問題並改寫擴充規模。第二階段通過多次採樣同一問題獲得不同的推理路徑,結合規則檢查、拒絕採樣以及投票技術篩選高質量答案。
長文本數據
作者引入了由長文本與圖文混合構成的長上下文訓練數據。在原生長文本數據的基礎上,引入高質量的長距離推理數據,有效提升了模型在多模態場景下的上下文理解深度與推理穩定性。
SFT數據
作者構造了高質量SFT數據集。從社區和內部業務廣泛收集問題及圖片,經過標註分類和指令去重後,圍繞能力維度重建了多樣化的新指令集。然後用多個強模型生成候選答案,結合規則過濾、模型打分、多數投票、人工校驗等方法,篩選高質量數據。
數據集在語言與模態方面保持良好平衡,確保滿足任務多樣性、答案質量、場景平衡。其中,長推理方面構建了包含300K條樣本、覆蓋STEM領域的高質量SFT數據集。
RL數據
作者構建了多種任務類型的強化學習數據集,覆蓋數學、代碼、STEM、指令跟隨以及端側業務等。數據來源於開源數據集以及業務場景,經過去重、質量過濾,總計145K條。
Data Pipeline
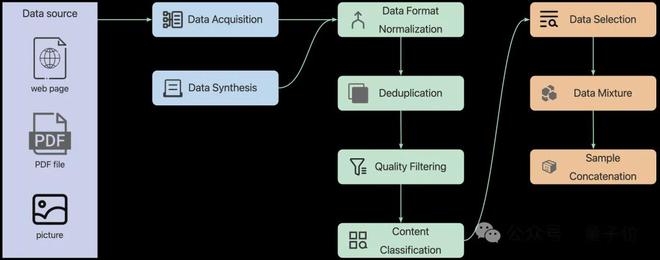
作者構建了一套覆蓋數據處理全生命周期的自動化 data pipeline,涵蓋數據採集、合成、格式轉換、質量過濾、去重、分類、篩選、配比、樣本構建等關鍵模塊,支持多源異構數據統一接入,具備高度模塊化與自動化能力,顯著提升了預處理效率與訓練數據質量。
為支撐模型的高效訓練,作者構建了高性能訓練平台和訓練框架。
訓練集羣
作者自建了大規模高性能訓練集羣,在千卡級訓練場景實現了超過95%的近線性加速比。依託自研的軒轅分佈式存儲並通過多級緩存優化IO瓶頸。同時建設了集羣穩定性保障體系,訓練有效時長超過 99%。
多樣本拼接平衡計算負載、提高GPU利用率:
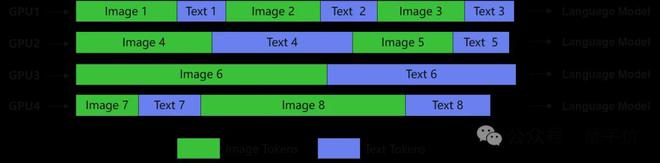
長上下文訓練:

vivoLM訓練框架
作者基於Megatron-LM,自研了vivoLM訓練框架,支持文本和多模態大模型訓練,圍繞以下四大維度進行了優化:
1)訓練性能上,優化圖文對拼接策略以均衡每張卡計算的token數量,提升算力利用率。 通過Context Parallelism + CP組內ViT數據並行支持32K長文訓練,訓練效率是社區方案的1.66倍。全局Batch Size擴至16K,千卡集羣加速比達96.8%。
2)架構擴展上,模塊化解耦ViT、Adapter與LLM,組件及數據處理策略可即插即用。兼容 Megatron-LM、DeepSpeed 等主流訓練框架。
3)穩定性上,完善框架異常處理機制並與訓練平台聯動,部分故障場景任務可自動恢復。萬億級token數據、千卡級預訓練任務100+小時零中斷。
4)可觀察性上,實現了訓練過程的細粒度監控,包括參數、梯度的L2範數、AdamW優化器內部狀態等。同時支持了在線評測,實時跟蹤模型效果。
RL訓練框架
作者基於 veRL進行了定製開發,適配藍心大模型訓練並做了性能優化。
在性能上借鑑 verl-pipeline方案實現了One-Step Asyn RL,並將Ray通信切換為NCCL通信,降低參數更新的通信開銷;重寫vLLM異步ChatScheduler,動態調度消除 bubble time以最大化推理吞吐。整體訓練性能提升了60%。
為了保障訓練穩定性,針對RM服務作者自動化部署多實例,並將實例註冊到名字服務(VNS),支持訓練框架按標識自動發現並調用服務。同時服務可基於QPS 動態彈性伸縮,避免流量變大後請求延遲變高影響RL訓練性能。
技術報告: https://arxiv.org/abs/2507.05934
(轉自:網易科技)