炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

機器之心發布
機器之心編輯部
在大語言模型後訓練階段,強化學習已成為提升模型能力、對齊人類偏好,並有望邁向 AGI 的核心方法。然而,獎勵模型的設計與訓練始終是制約後訓練效果的關鍵瓶頸。
目前,主流的獎勵建模方法包括 「基於偏好的獎勵建模」(Preference-based Reward Modeling)和 「基於規則的驗證」(Rule-based Verifier)兩種方法。
其中,「基於偏好的獎勵建模」 一般利用標註的偏好對數據來訓練獎勵模型,這種方法存在着諸多侷限。首先,高質量偏好數據的獲取成本極高,難以大規模擴展;其次,這種基於 「主觀絕對偏好」 的獎勵建模面對新任務時表現不佳,泛化能力有限,極易受到 「獎勵黑客」(Reward Hacking)的影響。這些問題嚴重製約了獎勵模型在大模型後訓練階段的實際落地。
隨着 Deepseek R1 等推理模型的成功,「基於規則的驗證」 強化學習方法(RLVR)迎來了廣泛應用。RLVR 會依賴給定問題的標準答案或預期行為給出獎勵,從而保證了獎勵信號的準確性。因此,RLVR 尤其適用於數學推理、代碼生成等具有明確評價標準的 「可驗證」 任務。然而,在真實世界中,大量任務難以用規則簡單驗證,如開放域對話、寫作、複雜交互等。這導致基於規則的驗證方法難以擴展到更通用的場景。
基於偏好的獎勵建模難以擴展和泛化,基於規則的驗證難以滿足通用場景的需求。那麼,究竟什麼纔是擴展方便、泛化性強、場景通喫的獎勵建模方案呢
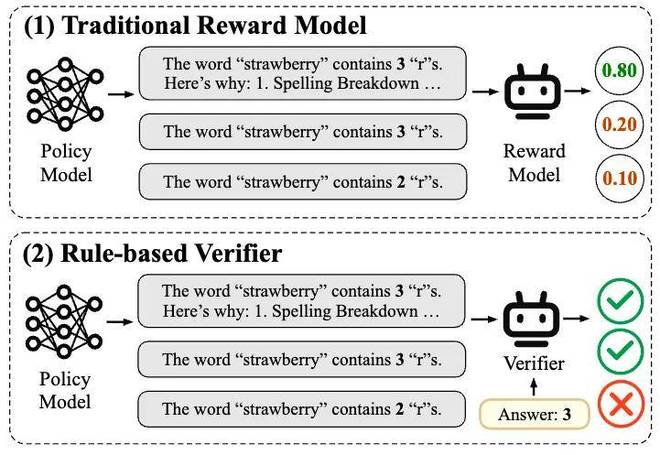
圖一:傳統的獎勵模型和基於規則的驗證器
回顧大模型(LLM)的成功之路,是利用 Next Token Prediction 的形式統一了所有任務,解決了任務形式不同導致無法泛化的難題。而獎勵模型(RM)的設計仍然在重蹈傳統方案的老路,即為特定場景標註偏好數據,訓特定場景的 RM。因此,是否可以仿照 LLM 的成功之路,重新設計 RM 的訓練範式呢?消除 RM 的 「打分標準」,就像消除 LLM 的 「任務形式」 一樣,找到一個脫離於 「打分標準」 之外的更本質的優化目標函數來進行預訓練,從而達到真正的通用性。
近期,上海人工智能實驗室鄒易澄團隊聯合復旦大學桂韜團隊推出了預訓練獎勵模型 POLAR,找到了一種與絕對偏好解耦的、可以真正高效擴展的獎勵建模新範式:策略判別學習(Policy Discriminative Learning, POLAR),使獎勵模型能夠像大語言模型一樣,具備可擴展性和強泛化能力。POLAR 為大模型後訓練帶來突破性進展,有望打通 RL 鏈路擴展的最後一環。

POLAR 是什麼?—— 與絕對偏好解耦的策略判別學習
在強化學習中,策略優化實際上是一個不斷調整策略分佈、使其逐步接近最優策略分佈的過程。因此,當前的候選策略與最優策略之間的 「距離」 可以被視為一種潛在的獎勵信號:當候選策略越接近最優策略時,獎勵函數應當給予越高的獎勵,從而引導策略進一步向最優方向收斂。
通過衡量候選策略與目標最優策略之間的 「距離」,我們可以建立一種不依賴於人類絕對偏好的獎勵建模方式,使獎勵模型擺脫 「絕對的好壞」,而是為更接近目標策略的候選策略賦予更高的獎勵分數。由於 「距離」 是一種相對性的概念,因此目標策略可任意指定,從而擺脫了對偏好數據人工標註的依賴,具有極強的可擴展潛力。具體而言,POLAR 利用從候選策略採樣的軌跡(trajectories)來近似候選策略的分佈;同時,以參考軌跡(demonstrations)來近似最優策略分佈。通過衡量軌跡之間的差異來近似衡量策略分佈之間的距離。
對於 「距離度量」,經典的方案有 「對比學習」(Contrastive Learning),通過構造正負樣本來訓練模型(如 CLIP)。POLAR 就是一種利用對比學習來建模策略分佈之間 「距離」 的訓練方案。至此,還剩下一個最關鍵的問題:正負例如何定義?
不論是候選策略的採樣軌跡,還是代表最優策略的參考軌跡,直接用來近似策略分佈都會造成一定的偏差,因此我們不能單純基於單個軌跡來衡量兩者的樣本相似性。例如,在數學場景中,如果候選策略輸出的答案與參考相同,可以說明此策略質量較高;但是,在寫作等多樣性較高的場景中,如果候選策略每次輸出的都與標準答案相同,反而說明此策略質量不好。因此,「軌跡是否相似」 無法成為無偏的判斷標準。
對此,POLAR 採用了另一種方案:同一個策略生成的軌跡作為正例,不同策略生成的軌跡作為負例。這一判斷標準雖然有一些反直覺,但它是一種真正無偏的信號,和對抗生成網絡(GAN)中判斷是否是真實樣本類似。我們可以把策略模型看作是某個分佈的無偏採樣器,雖然單次採樣可能會產生正負例相反的噪聲,但是當採樣規模增大,大規模擴展數據時,分佈間的差異和距離會被刻畫得越來越精確。
如圖二所示,POLAR 的預訓練階段採用上述對比學習方案進行大規模擴展。由同一個模型輸出的一對樣本作為正例,由不同模型輸出的樣本作為負例,從而讓獎勵模型學會區分策略分佈,而非建模人類的絕對偏好。這一階段無需任何的人類偏好數據。在第二階段的 SFT 微調中,才引入少量的偏好數據對齊到人類偏好。

圖二:策略判別學習(Policy Discriminative Learning)
POLAR 如何訓練?—— 預訓練和偏好微調
POLAR 的預訓練語料完全通過自動化合成數據構建。具體而言,從 LLM 預訓練語料中採樣出大量的文本前綴,並從策略模型池(由開源的131個 Base LLM 和53個 Chat LLM 組成)中隨機取模型進行軌跡採樣。預訓練目標使用 Bradley-Terry Loss:

其中,A1 和 A2 代表相同策略模型生成的軌跡(正樣本對);B1 代表不同策略模型生成的軌跡(負樣本)。通過這種方式,POLAR 使 RM 學會為相近策略產生的軌跡賦予更高獎勵,從而隱式建模策略分佈的差異和距離。在這一階段,POLAR-1.8B 共使用了0.94T Token的預訓練數據,POLAR-7B 共使用了3.6TToken 的預訓練數據。
在微調階段,POLAR 使用少量的偏好數據對齊人類偏好。對於同一個 Prompt,採樣三條軌跡,由人工標註偏好順序。同樣使用 Bradley-Terry Loss 進行微調:

其中,A > B > C,分別代表偏好最優、次優、最差的軌跡。這種偏好排序隱式定義了一種 「策略差異」,例如 A 可以視為從最佳策略分佈中採樣得到,而 C 可以視為從一個與最佳策略相差較遠的策略分佈中採樣得到。

圖三:POLAR 的兩階段訓練(預訓練和偏好微調)以及在 RFT 中的使用方法
POLAR 如何使用?—— 對強化微調的完美適配
強化微調(Reinforcement Fine-tuning,RFT)是 POLAR 的最佳使用場景。
傳統的獎勵模型建模的是絕對偏好,無法根據參考來打分,難以應用於領域外(Out-of-Domain)場景。RLVR 雖然可以根據參考答案和規則對模型輸出進行正確與否的判斷,但難以擴展到通用任務。
POLAR 完美適配 RFT 強化學習框架,基於問題的參考答案對模型輸出進行打分。如果模型輸出與參考答案更為接近,則會獲得更高的獎勵值。通過這一訓練過程,可以使得候選策略逐步向最優策略偏移。
POLAR 效果如何?—— 性能和泛化的雙重保證
1. 樣例展示:閉式問題和開放問題全搞定
以下分別展示了在閉式問題和開放問題下,POLAR-7B 的打分效果,以分數從高到低呈現。測試例充分考慮了各種陷阱,以及軌跡之間的細微差別,考驗其在邊界情況下的打分準確性。
問題:單詞 「strawberry」 中有幾個 「r」?
參考答案:單詞 「strawberry」 中包含 3 個字母 「r」。我們可以逐字母數一下:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。因此,答案是 3。
軌跡一(與參考完全一致):單詞 「strawberry」 中包含 3 個字母 「r」。我們可以逐字母數一下:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。因此,答案是 3。
分數:-1.5380859375
軌跡二(答案正確,思路正確):我們來數一數單詞 「strawberry」 中有幾個 「r」:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。這裏一共有三個 「r」,因此答案是三。
分數:-2.767578125
軌跡三(答案正確,無思路):單詞 「strawberry」 中有 3 個 「r」
分數:-7.45703125
軌跡四(答案錯誤,思路正確):我們來數一數單詞 「strawberry」 中有幾個 「r」:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。這裏一共有三個 「r」,因此答案是二。
分數:-7.6328125
軌跡五(答案正確,思路錯誤):我們來數一數單詞 「strawberry」 中有幾個 「r」:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。這裏一共有兩個 「r」,因此答案是三。
分數:-8.65625
軌跡六(答案錯誤,思路錯誤):我們來數一數單詞 「strawberry」 中有幾個 「r」:「s」、「t」、「r」、「a」、「w」、「b」、「e」、「r」、「r」、「y」。這裏一共有兩個 「r」,因此答案是二。
分數:-9.2890625
軌跡七(答案錯誤,無思路):單詞 「strawberry」 中有 2 個 「r」
分數:-11.921875
問題:幫我想 3 個形容雨很大的成語,要求不能重複。
參考答案:1. 傾盆大雨 2. 暴雨如注 3. 瓢潑大雨
軌跡一(與參考完全一致):1. 傾盆大雨 2. 暴雨如注 3. 瓢潑大雨
分數:-1.4267578125
軌跡二(正確回答):1. 大雨滂沱 2. 狂風驟雨 3. 大雨如注
分數:-5.234375
軌跡三(與參考相似,多一個):1. 傾盆大雨 2. 暴雨如注 3. 瓢潑大雨 4. 大雨滂沱
分數:-5.6328125
軌跡四(非成語):1. 急雨如瀑 2. 豪雨傾天 3. 雨勢磅礴
分數:-5.70703125
軌跡五(與參考相似,少一個):1. 傾盆大雨 2. 暴雨如注
分數:-6.609375
軌跡六(與參考相似,重複一個):1. 傾盆大雨 2. 暴雨如注 3. 暴雨如注
分數:-6.65625
軌跡七(成語正確,少一個):1. 大雨滂沱 2. 狂風驟雨
分數:-6.83203125
軌跡八(成語正確,多一個):1. 大雨滂沱 2. 狂風驟雨 3. 大雨如注 4. 傾盆大雨
分數:-7.0234375
軌跡九(成語正確,重複一個):1. 大雨滂沱 2. 狂風驟雨 3. 狂風驟雨
分數:-7.234375
軌跡十(帶雨字成語,一個含義不符):1. 大雨滂沱 2. 狂風驟雨 3. 雨後春筍
分數:-7.26953125
軌跡十一(帶雨字成語,兩個含義不符):1. 大雨滂沱 2. 雨過天晴 3. 雨後春筍
分數:-8.578125
2. 偏好評估:準確率躍升

圖四:偏好評估實驗結果
在偏好評估方面,POLAR 展現出優越的性能和全面性,在大多數任務維度上優於 SOTA 獎勵模型。例如,在 STEM 任務中,POLAR-1.8B 和 POLAR-7B 分別超越了最佳基線 24.9 和 26.2 個百分點,並且能夠準確識別推理、聊天、創意寫作等通用任務中軌跡的細微區別,準確預測人類偏好。值得注意的是,POLAR-1.8B 僅有 1.8B 參數,就可取得與 Skywork-Reward-27B 和 WorldPM-72B-UltraFeedback(參數量分別為其 15 倍和 40 倍)相當的結果,凸顯了 POLAR 的強大潛力。
3. RFT 應用:全面增強 LLM 能力
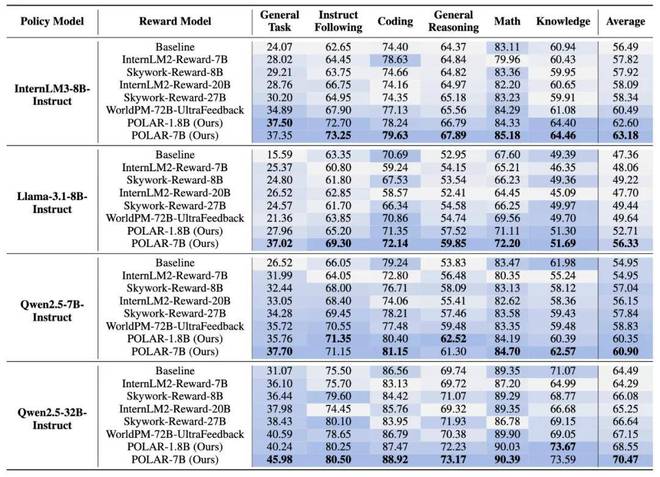
圖五:強化微調實驗結果
在 RFT 實驗中,POLAR 持續優於 SOTA 的開源獎勵模型。例如,使用 POLAR-7B 微調的 Llama-3.1-8B 在所有基準測試中,相對於初始結果平均提升了 9.0%,相對於 WorldPM-72B-UltraFeedback 優化的結果提升了 6.7%。POLAR 能夠從預訓練階段學習策略模型之間的細微區別,而不僅僅依賴於標註的偏好對,從而顯著增強了實際 RL 應用時的獎勵信號泛化性。實驗結果表明,儘管 POLAR-1.8B 和 POLAR-7B 在偏好評估中表現相似,但在下游 RL 實驗中,POLAR-7B 展現出了顯著優勢。從 1.8B 到 7B 的效果提升,進一步說明了 POLAR 所具有的 Scaling 效應。這也側面說明了當前傳統 Reward Bench 可能存在的侷限性,即與真實強化學習場景存在較大的差別。
4. Scaling 效應

圖六:POLAR 的 Scaling Laws
POLAR 展現出了與 LLM Next Token Prediction 目標類似的 Scaling Laws。這進一步體現了 POLAR 無監督預訓練方法的巨大潛力。驗證集損失隨模型參數 N 的增加呈冪律關係下降,擬合的冪律函數為 L=0.9⋅N^−0.0425, R2 值為 0.9886。驗證集損失也隨最優訓練計算量 C 的增加呈冪律關係下降,擬合的冪律函數為 L=2.4⋅C^−0.0342, R2 值為 0.9912。這些結果表明,分配更多的計算資源將持續帶來更好的 RM 性能。POLAR 的極佳 Scaling 效應,體現了其用於構建更通用和更強大的獎勵模型的巨大潛力。
結語
POLAR 在預訓練階段通過對比學習建模策略間的距離,僅需少量偏好樣本就可對齊人類偏好。在使用階段,POLAR 利用 RFT 範式對 LLM 進行強化學習,展現出了極佳的泛化性。POLAR 作為一種全新的、可擴展的獎勵模型預訓練方法,為 LLM 後訓練帶來了新的可能,讓通用 RFT 多了一種有效實踐方案。有望打通 RL 鏈路 Scaling 的最後一環。
(轉自:網易科技)