炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

新智元報道
編輯:桃子
【新智元導讀】強化學習,或許並不能通往AGI終點。Karpathy最新發文提出另一種Scaling範式,像人類一樣反思回顧,通過覆盤學習取得突破,更多的S形進步曲線等待發現。
Grok 4能站在大模型之巔,全是Scaling強化學習立了大功。

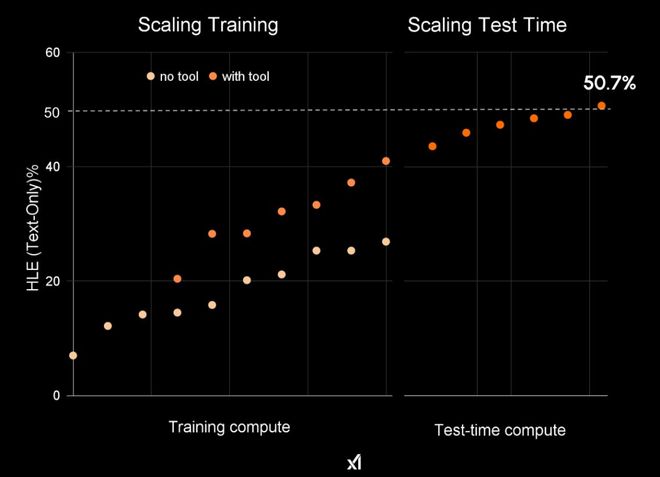
如今,AI大神Karpathy站出來急潑一盆冷水:
RL只是把最終成敗的單一數值回傳,效率隨任務時長急劇下降。
而且,RL與人類「反思-提煉-再應用」迭代機制存在巨大差異。
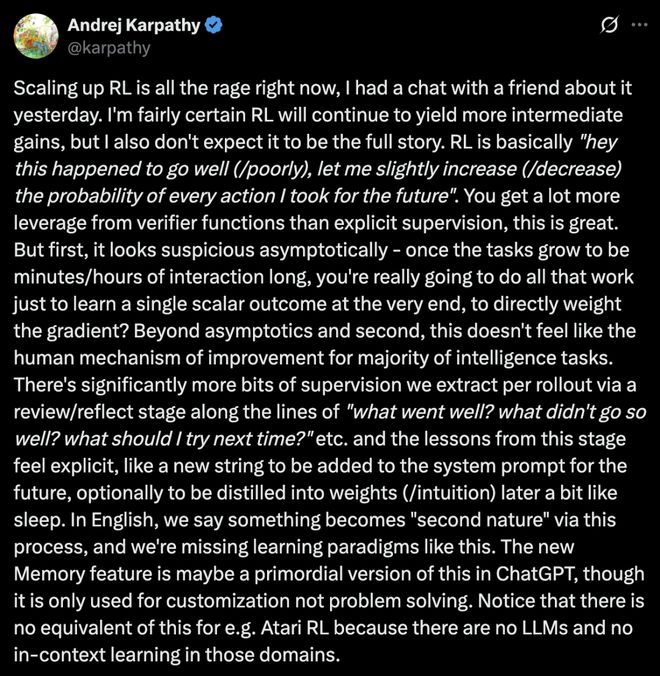
RL短期有效
真正突破在於「覆盤學習」
強化學習的本質是,某次行動表現良好(糟糕),就略微提升(降低)未來類似行動的概率。
這種方法通過驗證函數,比顯示監督取得了更大的槓桿效應,無疑是其強大之處。
然而, 在Karpathy看來,從長遠角度來講,強化學習或許並不是最優策略。
長時程任務,RL侷限顯現
首先,一旦任務交互時間增加到幾分鐘乃至幾小時,RL就遇到了挑戰。
想象一下,一個數小時交互的任務,最終卻只得到一個單一的標量獎勵,來調整整個過程的梯度。
這樣的反饋,能否足以支撐高效學習?

RL機制與人類差異顯著
其次,對於大多數智能任務而言,這感覺並不像人類的進步機制。
簡言之,RL的機制與人類智能提升方式,存在着顯著的差異。
人類會通過一個覆盤/反思階段,從每一次推演中能提取到多得多的監督信息,比如「哪裏做得好?哪裏不太行?下次該試試什麼?」等等。
從這個階段得到的教訓感覺是明確的,就像一個新字符串,可以直接添加到未來的系統提示詞裏,也可以選擇性地在之後被「蒸餾」成權重/直覺,有點像睡眠的作用。
在英語裏,我們說通過這個過程,某件事會成為人的「第二天性」,而我們目前正缺少這樣的學習範式。
這裏,Karpathy提到了ChatGPT「記憶」功能,或許就是這種機制概念的一個雛形,儘管它目前只用於個性化,而非解決問題。
值得注意的是,在Atari遊戲這類RL場景中也不存在類似的機制,因為那些領域裏沒有大語言模型,也沒有上下文學習。
算法新設想:回顧-反思範式
為此,Karpathy提出了一個算法框架——
給定一個任務,先跑幾次推演,然後把所有推演過程(包括每次的獎勵)都塞進一個上下文,再用一個元提示詞來複盤/反思哪些地方做得好或不好,從而提煉出一個字符串形式的「教訓」,並將其添加到系統提示詞中(或者更通用地,更新當前的教訓數據庫)。
不過,他表示,這裏面有很多細節要填充,有很多地方可以調整,具體怎麼做並不簡單。
舉個栗子,大模型計數問題。
我們知道,由於分詞(tokenization)的原因,大模型不太容易識別單個字母,也不太容易在殘差流裏計數。
所以,衆所周知,模型很難識別出「strawberry」裏的「r」字母。
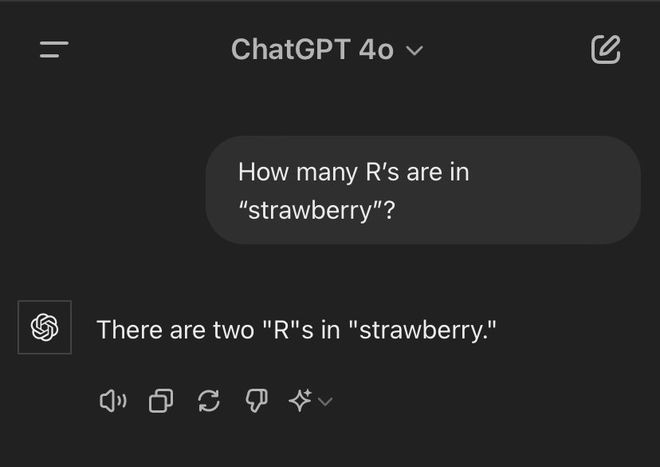
Claude的系統提示詞裏就加入了一個「快速修復」patch——添加了一段話,大意是:「如果用戶讓你數字母,你得先用逗號把字母隔開,每隔一個就給一個顯式計數器加一,照這樣做完任務」。
這段話就是「教訓」,它明確地指導模型如何完成計數任務。
但問題在於,這種教訓要如何從智能體的實踐中自發產生,而不是由工程師硬編碼進去?它該如何被泛化?
以及,這些教訓如何隨着時間推移被蒸餾,從而避免讓上下文窗口無限膨脹?
最後,他總結道,RL會帶來更多收益,如果應用得當,它的槓桿效應巨大。
並且,深受「慘痛教訓」(bitter lesson)理論的啓發,RL優於監督微調(SFT)。
但它並不是完整的答案,尤其是隨着推演的流程越來越長。
在這之後,還有更多的S型增長曲線等待發現,這些曲線可能專屬於大語言模型,在遊戲/機器人這類環境中沒有先例,而這,正是我覺得激動人心的地方。
OpenAI研究科學家Noam Brown對此深表讚同,「確實,未來仍有許多研究工作有待完成」。

AI初創公司聯創Yuchen Jin提出了一個有趣的觀點,全新訓練範式——課程學習,是一個自監督記憶+檢索+反思的反饋循環,無需任何外部獎勵信號。

一位網友很有見地稱,強化學習實際上是暴力試錯的一種方法,並非是明智的策略。

放棄無效RL研究
最近,關於強化學習的討論,成為了AI圈的一大熱點。
除了Karpathy本人下場,上周前OpenAI研究員Kevin Lu髮長文稱,Transformer只是配角,放棄無效RL研究!

他直言,真正推動AI規模躍遷的技術是互聯網,而非Transformer,這也是你應該停止RL研究,轉投產品開發的原因。
衆所周知數據纔是AI最重要的要素,但研究者們卻往往選擇迴避這個領域...
究竟什麼纔是規模化地做數據?
互聯網提供了天然的數據寶庫:海量且多樣化的數據源、自然形成的學習路徑、反映人類真實需求的能力維度,以及可經濟高效規模化部署的技術特性——
它成為下一個token預測的完美搭檔,構成了AI爆發的原始湯池。

沒有Transformer,我們本可以用CNN或狀態空間模型達到GPT-4.5的水平。
但自GPT-4之後,基礎模型再未出現突破性進展。
專用推理模型在垂直領域表現優異,卻遠不及2023年3月GPT-4帶來的震撼級跨越(距今已兩年多...)。
RL確實成就斐然,但Kevin Lu對此深切擔憂,研究者會重蹈2015-2020年間RL研究的覆轍——沉迷於無關緊要的學術遊戲。
如果說互聯網是監督預訓練的時代搭檔,那麼什麼才能成為強化學習的「共生體」,催生出GPT-1到GPT-4量級的飛躍?
Kevin Lu認為答案在於:研究-產品協同設計。
參考資料:
https://x.com/karpathy/status/1944435412489171119
(轉自:網易科技)