炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
近年來,多模態大模型(MLLMs)發展迅猛,從看圖說話到視頻理解,似乎無所不能。
但你是否想過:它們真的「看懂」並「想通」了嗎?
模型在面對複雜的、多步驟的視覺推理任務時,能否像人類一樣推理和決策?
為評估多模態大模型在視覺環境中,完成複雜任務推理的能力。清華大學團隊受密室逃脫遊戲啓發,提出EscapeCraft:一個3D密室逃脫環境,讓大模型在3D密室中通過自由探索尋找道具,解鎖出口。
該論文目前已入選ICCV 2025。

EscapeCraft 環境
沉浸式互動環境,靈感源自密室逃脫
研究團隊打造了可自動生成、靈活配置的 3D 場景 EscapeCraft,模型在裏面自由行動:找鑰匙、開箱子、解密碼、逃出房間……其中每一步都需整合視覺、空間、邏輯等多模態信息。
任務可擴展,應用無限可能
EscapeCraft以逃出房間為最終目的,重點評測逃脫過程中的探索和決策行為、推理路徑等。支持不同房間風格、道具鏈長度與難度組合,還可擴展到問答、邏輯推理、敘述重建等任務。它是一個高度靈活、可持續迭代的通用評測平台,也可以為未來的智能體、多模態推理、強化學習等方向研究提供基礎環境、數據和獎勵設定方面的支持。
EscapeCraft支持自由定製和擴展想要的難度等級。不同難度等級下所需的逃脫步驟有所不同。
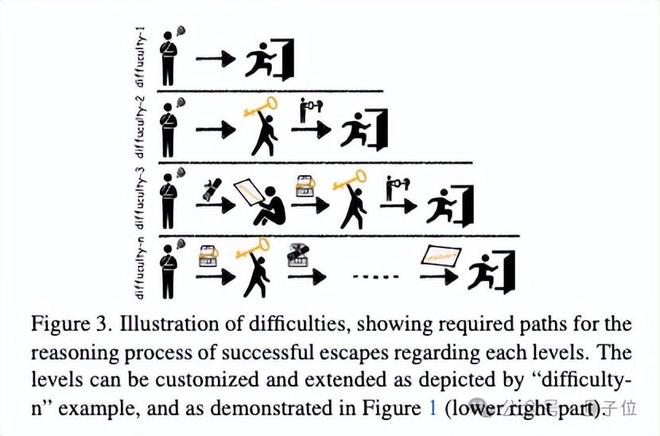
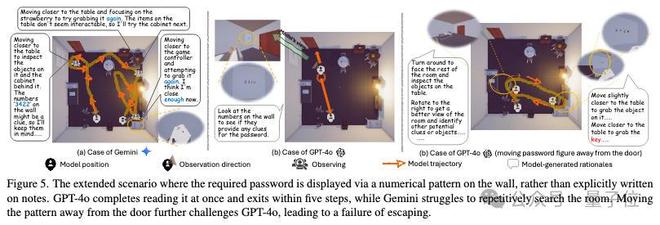
為了提高任務的難度,我們將線索放置在了牆上而不是箱子中,考驗模型對於環境信息的接收和處理能力,除此之外線索在房間的擺放位置也可自由選擇。
在第一個場景中,線索位於靠近出口的牆上,此時GPT-4o的表現更加出色,可以對線索進行正確利用。
不過,當我們把線索移動到距離出口較遠的牆上,GPT-4o開始不斷重複歷史路徑,無法對正確理解和利用線索,導致逃脫失敗。
模型推理和過程評測
Gemini-1.5-Pro 密室逃脫第一視角
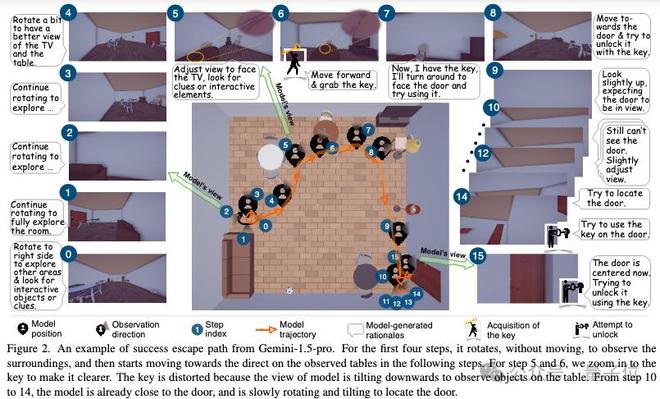
這張圖展示了 Gemini-1.5-pro 模型成功逃脫一個房間的全過程。
開始的0到4步,模型原地不動,通過旋轉視角來觀察房間的環境。
它先從右側開始旋轉,一步步查看房間的不同區域,試圖找到可交互的物體或線索,比如電視、桌子和椅子。
到了第五步,模型將視角對準電視方向,繼續尋找可操作的元素,這時我們可以看到桌上有一把鑰匙。
第六步時,模型前進並拾取了這把鑰匙。拿到鑰匙後,模型表示自己準備轉身面對門,嘗試使用鑰匙。
接下來的步驟中,模型開始朝門的方向移動,意圖解鎖房門。在移動過程中,他多次調整視角,尤其是向上看,試圖確認門的位置。
由於視角偏低,模型一開始沒能看到門,於是不斷微調視角方向來定位門的位置。
從「答對」到「會想」
與傳統只看最終任務結果的評測不同,EscapeCraft 關注整個任務完成過程:模型是否自主探索?有沒有重複犯錯?道具用得對不對?從而真正測試模型的「類人推理過程」。
論文重點彌補以結果為導向的評估缺陷,強調中間推理過程。為此設計了多個衡量視覺感知、多模態推理、環境探索和工具獲取和利用的過程的創新指標:
Intent-Outcome Consistency(意圖與結果一致性):衡量模型與環境的交互結果是否和的模型的交互意圖一致,即模型是否「在正確的位置做正確的事」。
Prop Gain / Grab Ratio / GSR:刻畫模型在探索和推理過程中的行為模式,反映模型的交互質量、推理效率、和智能程度。
評測結果顯示:GPT-4o 在 Difficulty-3 中僅有 26.5% 的子目標達成是「真正理解後完成的」,其餘大多為偶然成功(比如想拿電視卻誤抓到關鍵道具)。
研究還發現大量有趣失敗案例。例如:
模型面對不可交互的沙發,仍試圖抓取,並在「理由」中解釋「沙發下可能藏着鑰匙」;
模型原本已經看見了關鍵道具,卻在移動過程中將其「逐步移出視野」,隨後繼續提及該道具卻操作失敗……
團隊據此將錯誤拆分為兩類:
視覺感知錯誤:誤判目標是否可交互,視角控制失敗;
推理邏輯錯誤:目標設定錯誤,或動作與意圖不符。
其中 Claude 3.5 的錯誤中,61.1% 屬於推理問題,38.9% 屬於視覺問題。這說明即便模型「看到了」,不代表它「想清楚了」。
誰能逃離「密室」?模型表現結果對比
單房間逃脫結果統計,包括3個不同難度級別(數值越大越難)。
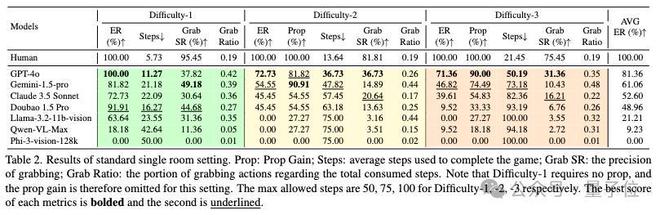
研究評測了包括 GPT-4o、Gemini-1.5 Pro、Claude 3.5、LLaMA-3.2、Qwen、Phi-3 等熱門模型,發現:
在任務評價指標方面:
GPT-4o 逃脫成功率(ER)最佳,但在任務複雜度提升後仍頻頻出錯;
國產大模型Doubao 1.5 Pro在最簡單的關卡中,逃脫成功率超越Gemini 1.5 Pro和Claude 3.5 Sonnet;並且其交互成功率(Grab SR)超越GPT-4o和Claude 3.5 Sonnet;
即使模型逃脫成功率相同,EscapeCraft依然能利用道具獲取率(Prop)、使用步數(Step),交互成功率(Grab SR)和交互率(Grab Ratio)對模型進行比較。
比如,在「Difficult-2」中,Gemini 1.5 Pro和Claude 3.5 Sonnet有相同的逃脫成功率和道具獲取率,但是Gemini 1.5 Pro憑藉較高的交互率,即使它的交互成功率較低,也能通過相對較少的步數成功逃脫;而Claude 3.5 Sonnet雖然交互率低,但每一步交互的成功率較高,體現出該模型完成任務時的「深思熟慮」。
在推理和探索行為方面:
Gemini 和 Claude 常在房間角落「卡住」,空間方向等判斷失誤,空轉失敗;
多數模型容易「反覆抓錯」或「認錯道具」,他們的失敗方式也各有特色:有的不會動、有的亂動、有的只移動不採取交互行動、有的動作對了但「目的不清」……;
子目標達成率雖高,但意圖-結果一致性普遍低下,即「想要和沙發交互,但是意外地拿到鑰匙」;
在多房間設定下,模型能從第一個房間學習到的逃脫經驗有限,僅在兩個房間關卡設定相似的條件下有輔助作用。
項目主頁:
https://thunlp-mt.github.io/EscapeCraft
GitHub 地址:
https://github.com/THUNLP-MT/EscapeCraft
論文原文:
https://arxiv.org/abs/2503.10042v4
(轉自:網易科技)