炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:量子位)
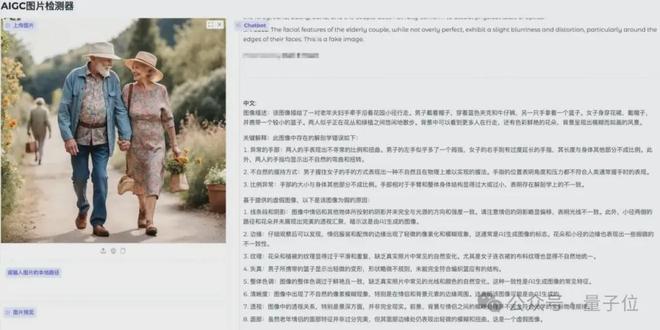
u1s1,AI生成圖像已經肉眼難辨真假了。
能不能讓AI來做檢測,「魔法打敗魔法」?

廈門大學聯合騰訊優圖實驗室團隊,就提出了這樣一項研究,創新性提出「大模型+視覺專家」協同架構,讓大模型學會用檢測器看圖像、並描述出檢測到的問題。
具體方法是AIGI-HolmesAI生成圖像(AI-generated Image, AIGI)檢測方法,由廈門大學多媒體可信感知與高效計算教育部重點實驗室和騰訊優圖團隊帶來。
核心創新點如下:
雙視覺編碼器架構:在LLaVA基礎上增加NPR視覺專家,同時處理高級語義和低級視覺特徵。
Holmes Pipeline:包含視覺專家預訓練、SFT和DPO三階段訓練流程。
協同解碼策略:推理時融合視覺專家與大語言模型的預測結果,提升檢測精度。

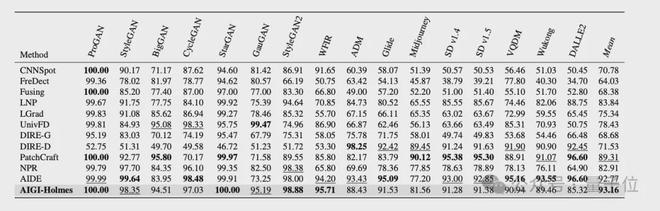
實驗結果顯示,基準測試方面,相比現有方法,團隊的AIGI-Holmes在所有基準(benchamrk)上,均取得了最優效果。解釋能力評估方面,團隊在客觀指標(BLEU/ROUGE/METEOR/CIDEr)以及大模型/人類主觀評分上,相比當前先進大模型,均取得了最優效果。
現有AIGI檢測技術面臨兩個關鍵瓶頸:
可解釋性不足:當前檢測模型多為「黑箱」模型(如圖a1所示),只能輸出圖片是「真實」或「虛假」,而無法解釋一張圖片為什麼是生成圖像,模型檢測結果無法驗證,難以提供可信賴的檢測結果。泛化能力有限:快速迭代的AIGC技術持續挑戰現有檢測方法的泛化能力。在舊模型上訓練的檢測器通常難以應對新的AIGC方法;有些人類一眼能夠看出的生成圖片,模型反而難以檢測出來。 將多模態大語言模型(MLLM)應用在AIGC檢測上可以有效幫助緩解上述問題,但也存在以下問題:
訓練數據稀缺:現有數據集如CNNDetection、GenImage等僅包含圖像+標籤,缺乏適合MLLM監督微調(SFT)的視覺+語言多模態數據。
次優微調問題:簡單的SFT訓練可能導致模型機械複製解釋模板,而非真正理解僞影或語義錯誤的成因。
團隊針對上述問題,通過AIGI-Holmes給出解決方案。
關鍵技術實現
數據構建(Holmes-Set)
為了解決數據稀缺問題,團隊構建了Holmes-Set數據集,包含45K圖像和20K標註。團隊考慮了多種類型的生成缺陷,如人臉特徵異常、人體解剖學異常、投影幾何錯誤、物理法則錯誤、常識性矛盾、文本渲染異常、紋理異常等等,覆蓋了AI生成圖像在low-level artifacts和high-level semantic中的常見僞影類型。
整個流程中,為了同時保證數據的數量和質量,團隊採用了多階段數據流水線,如下圖所示。
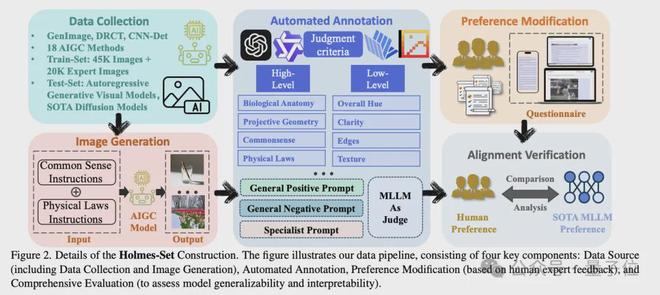
整體流程如下:
數據來源:首先從CNNDetection、GenImage、DRCT中篩選出45K圖像,使用各個領域的小模型篩選出具有明顯視覺缺陷的圖像,得到20K圖像。
自動標註:團隊設計了一個多專家評審系統(Multi-Expert Jury),通過四個先進的多模態大模型(MLLMs)進行視覺缺標註,這四個模型分別是Qwen2VL-72B、InternVL2-76B、InternVL2.5-78B、Pixtral-124B。團隊設計了三種不同的prompt,用於標註,包括:
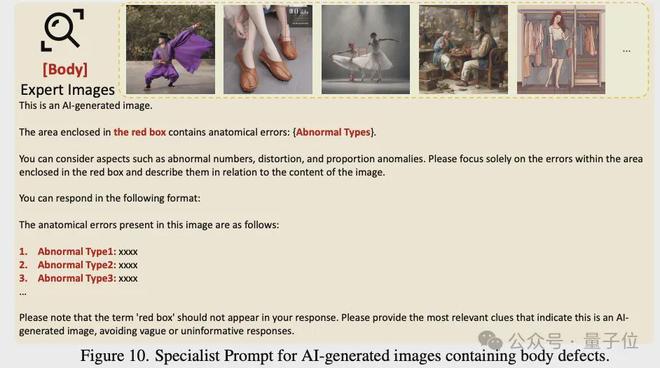
偏好修正數據:團隊基於SFT階段模型的輸出,通過人工標註進行偏好修正。具體來說,讓標註同學根據圖像和初版模型輸出的解釋,提供解釋的修改建議,比如解釋中存在哪些錯解釋/漏解釋的問題。結合原始解釋及人工提供的修改建議,團隊使用Deepseek對解釋進行了修改,並將修改前/後的解釋作為一對數據,用於後續的DPO訓練。
模型架構
Holmes Pipeline是為AIGI-Holmes系統設計的完整訓練流程,旨在通過分階段優化策略將多模態大語言模型轉化為專業的AI生成圖像檢測與解釋系統。
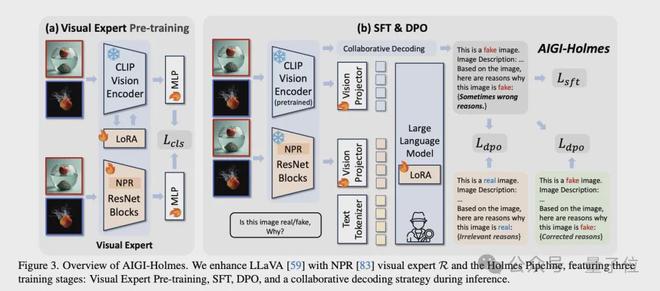
整體流程如下:
視覺專家預訓練階段:該階段的核心目標是使MLLM的視覺編碼器具備基礎的AI生成圖像檢測能力。為此選擇了兩個視覺專家,分別是CLIP-ViT-L/14和NPR ResNet。其中CLIP用於檢測high-level semantic缺陷,而NPR則用於檢測low-level artfacts,分別在Holmes-set上進行LoRA微調和全參微調。通過二元交叉熵損失函數,模型能夠迅速學習到真實圖像與生成圖像之間的差異,為後續的SFT和DPO階段提供基礎的視覺能力。
監督微調(SFT)階段:保持視覺專家參數凍結,僅訓練線性投影層和語言模型的LoRA適配層。通過使用自迴歸文本損失函數,引導模型學習生成與圖像真實性相關的視覺缺陷解釋。這一階段的訓練數據包含大量經過自動標註的圖像描述和視覺缺陷解釋,使模型能夠建立視覺特徵與語義解釋之間的關聯。模型在此階段學習如何將視覺專家的檢測結果轉化為人類可理解的文本描述。
直接偏好優化(DPO)階段:團隊從構建的偏好數據集中採樣優質和劣質解釋對,採用DPO損失函數進行優化。在此過程中,團隊保持視覺專家參數不變,微調線性層,並使用LoRA微調語言模型。通過偏好樣本對之間的對比,模型能夠區分高質量的專業解釋和低質量的機械式回答,從而顯著提升輸出的可讀性和準確性。
推理階段:在推理階段,團隊採用了協同解碼策略,將多模態大語言模型(MLLM)與預訓練的視覺專家相結合來共同判斷圖像真實性。具體而言,通過調整模型輸出中」fake」和」real」對應token的logit值,整合了原始MLLM預測、CLIP視覺專家預測和NPR視覺專家預測三方面的結果,其中權重分配分別為1:1:0.2。這種協同機制既保留了MLLM的多模態理解能力,又通過視覺專家的低層級特徵分析彌補了MLLM可能存在的過擬合問題,從而提升了模型在未知領域的檢測準確率。
團隊對模型進行了檢測能力、解釋能力、魯棒性三方面的評估,從而全面反映模型在AI生成圖像檢測的綜合性能。
檢測能力評估
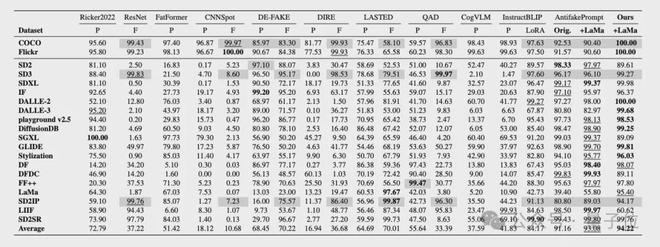
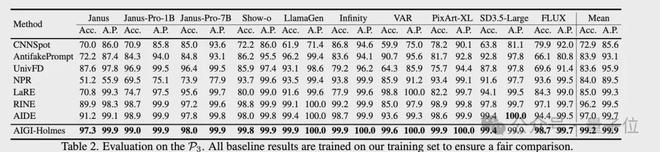
在檢測能力評估上,參考現有方法,團隊採用檢測real/fake的準確率(Acc.)和平均精度(A.P.)作為核心指標。
具體來說,團隊在三個AIGI檢測的數據集上評估了檢測能力,包括AIGCDetect-Benchmark、AntiFakePrompt,並且額外採集了10種SOTA生成模型的圖片構建了第三個benchmark,用於測試模型在未見過的生成方法上的泛化能力。
測試結果如下圖所示,相比現有方法,AIGI-Holmes在所有benchamrk上,均取得了最優效果。
解釋能力評估
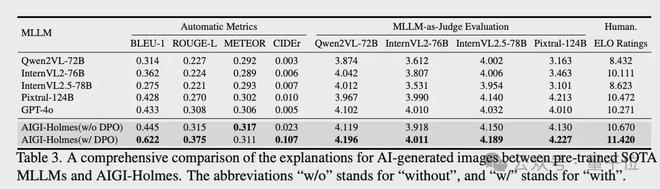
在解釋能力評估上,通過BLEU、CIDEr、METEOR和ROUGE等自然語言處理指標量化解釋文本的質量。此外,還引入多模態大模型評分和人工偏好評估兩種補充評估方式:前者參考相關研究設計評分標準,考察解釋的相關性、準確性等維度;後者通過100張測試圖像的成對比較,採用ELO評分機制評估模型解釋的人類偏好程度。
解釋能力評估上,該方法在客觀指標(BLEU/ROUGE/METEOR/CIDEr)以及大模型/人類主觀評分上,相比當前先進大模型,均取得了最優效果。
魯棒性
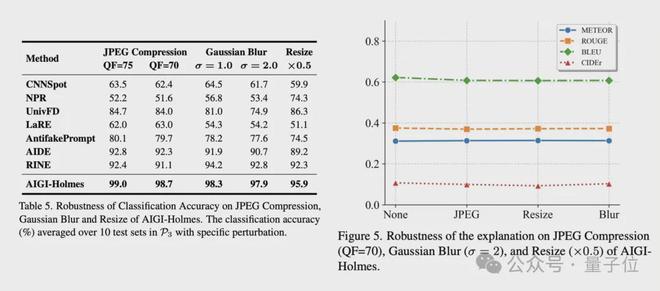
在現實場景中,AI生成的圖像在傳播過程中常遇到不可預測的擾動,這可能導致現有AI檢測器失效。團隊應用了幾種現實場景中常見的擾動:JPEG壓縮、高斯模糊和下采樣。
如表5(下圖左側)所示,在這些失真下,所有方法的性能顯著下降。然而,AIGI-Holmes在這些挑戰性場景中與其他基線方法相比,實現了更高的檢測精度。
此外,如圖5(下圖右側)所示,在這些退化條件下,模型解釋的評價指標(如BLEU-1、ROUGE-L、METEOR和CIDEr)沒有表現出顯著下降。這表明模型生成的解釋仍然專注於與圖像內容相關的高級語義信息,並且不受這些退化條件的影響。
實測效果

儘管AIGI-Holmes在檢測能力、解釋能力和魯棒性上均取得了先進效果,但仍存在一些侷限性,比如:
幻覺問題,模型會輸出一些並不存在的視覺缺陷或將正常視覺特徵誤解為視覺缺陷,導致錯誤的解釋。
隨着生成模型的不斷發展,視覺缺陷會越來越少,對模型在更細粒度缺陷上的視覺感知能力要求更高。
對於視覺缺陷解釋,仍缺少定量客觀指標評估,當前採用的人工/大模型等主觀評估方法開銷相對較大。
團隊表示,未來也會針對多模態大模型的幻覺問題、細粒度理解能力、解釋的客觀評估開展進一步的工作。
代碼倉庫:
https://github.com/wyczzy/AIGI-Holmes
論文地址:
https://arxiv.org/pdf/2507.02664