(來源:機器之心)

GTA 工作由中國科學院自動化研究所、倫敦大學學院及香港科技大學(廣州)聯合研發,提出了一種高效的大模型框架,顯著提升模型性能與計算效率。一作為自動化所的孫羅洋博士生,研究方向為:大模型高效計算與優化,通訊作者為香港科技大學(廣州)的鄧程博士、自動化所張海峯教授及倫敦大學學院汪軍教授。該成果為大模型的優化部署提供了創新解決方案。
Grouped-head latent Attention (GTA) 震撼登場!這項創新機制通過共享注意力矩陣和壓縮潛在值表示,將計算量削減 62.5%,KV 緩存縮減 70%,prefill 和 decode 速度提升 2 倍。無論是處理海量數據(維權)構成的長序列任務,還是在計算資源極為有限的邊緣設備上運行,GTA 都展現出無與倫比的效率和卓越的性能,無疑將成為大型語言模型優化領域的新標杆。
大型語言模型面臨的效率困局
近年來,Transformer 架構的橫空出世極大地推動了自然語言處理領域的飛速發展,使得大型語言模型在對話生成、文本摘要、機器翻譯以及複雜推理等多個前沿領域屢創佳績,展現出令人驚歎的能力。然而,隨着模型參數量從數十億激增至上千億,傳統多頭注意力機制 (Multi-Head Attention, MHA) 所固有的弊端也日益凸顯,成為制約其廣泛應用和進一步發展的瓶頸。
首當其衝的是計算冗餘問題。在 MHA (多頭注意力) 架構中,每個注意力頭都像一個獨立的 「工作單元」,各自獨立地計算查詢 (Query)、鍵 (Key) 和值 (Value) 向量,這導致了大量的重複計算。特別是在處理長序列任務時,浮點運算次數 (FLOPs) 會呈平方級增長,嚴重拖慢了模型的處理效率,使得原本複雜的任務變得更加耗時。
其次是內存瓶頸。每個注意力頭都需要完整存儲其對應的鍵值對 (KV) 緩存,這使得內存需求隨序列長度和注意力頭數量的增加而快速膨脹。例如,在處理長序列時,KV 緩存的規模可以輕鬆突破數 GB,如此龐大的內存佔用極大地限制了大型模型在智能手機、物聯網設備等邊緣設備上的部署能力,使其難以真正走進千家萬戶。
最後是推理延遲問題。高昂的計算和內存需求直接導致了推理速度的顯著下降,使得像語音助手實時響應、在線翻譯無縫切換等對延遲敏感的實時應用難以提供流暢的用戶體驗。儘管業界的研究者們曾嘗試通過 Multi-Query Attention (MQA) 和 Grouped-Query Attention (GQA) 等方法來優化效率,但這些方案往往需要在性能和資源消耗之間做出艱難的權衡,難以找到理想的平衡點。面對這一系列嚴峻的挑戰,研究團隊經過不懈努力,最終推出了 Grouped-head latent Attention (GTA),以其顛覆性的設計,重新定義了注意力機制的效率極限,為大型語言模型的未來發展開闢了全新的道路。

論文標題: GTA: Grouped-head latenT Attention
論文鏈接: https://arxiv.org/abs/2506.17286
項目鏈接: https://github.com/plm-team/GTA
GTA 的核心創新機制
GTA 的卓越成功源於其兩大核心技術突破,它們精妙地協同作用,使得大型語言模型即使在嚴苛的資源受限場景下,也能展現出前所未有的高效運行能力。
分組共享注意力矩陣機制
在傳統的 MHA 架構中,每個注意力頭都被視為一個獨立的 「獨行俠」,各自計算並維護自己的注意力分數。這種分散式的計算模式雖然賦予了模型捕捉多種複雜依賴關係的能力,但同時也帶來了顯著的計算冗餘。以一個包含 16 個注意力頭的 MHA 為例,當每個頭獨立處理輸入時,會生成 16 組獨立的注意力矩陣,這使得總體的計算開銷隨注意力頭數量的增加而呈線性增長,效率低下。
與此形成鮮明對比的是,GTA 採用了全新的 「團隊協作」 策略。該機制將注意力頭巧妙地劃分為若干個邏輯組,例如,每 4 個注意力頭可以組成一個小組,而這個小組內部的成員將共享一張統一的注意力矩陣。這種創新的共享設計意味着,我們僅需對注意力分數進行一次計算,然後便可將其高效地分配給組內所有注意力頭使用,從而大幅度減少了浮點運算次數 (FLOPs)。
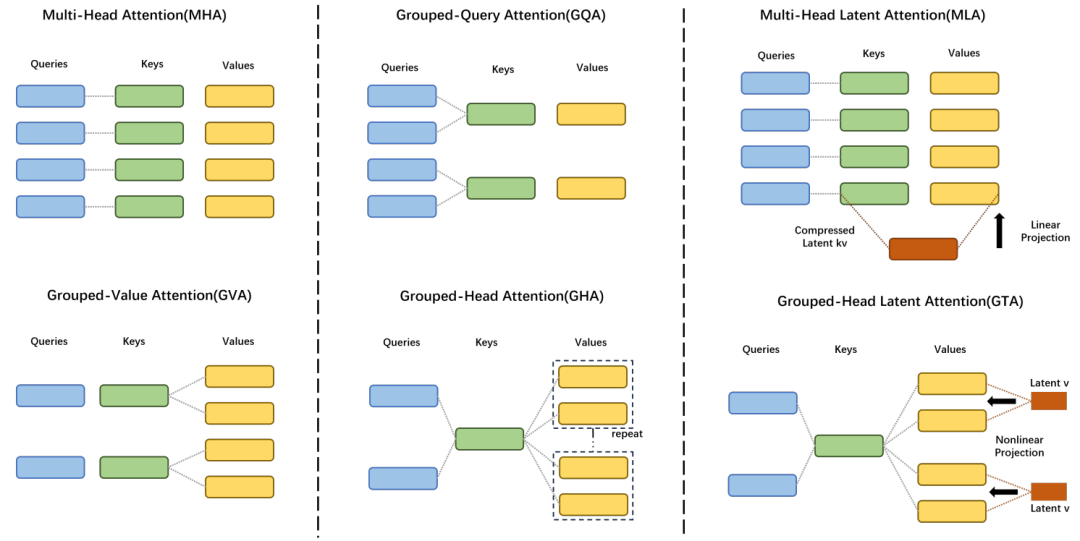
實驗數據有力地證明,這一精巧的設計能夠將總計算量削減,為處理超長序列任務帶來了顯著的推理加速效果。這恰如一位經驗豐富的主廚,統一備齊所有食材,再分發給不同的助手進行精細加工,既極大地節省了寶貴的時間,又確保了最終產出的高質量和一致性。
壓縮潛在值表示技術
MHA 架構的另一個關鍵痛點在於其 KV 緩存對內存的巨大佔用。由於每個注意力頭的值 (Value) 向量都需要被完整地存儲下來,導致模型的內存需求會隨着輸入序列長度和注意力頭數量的增加而快速膨脹,成為部署大型模型的嚴重障礙。GTA 通過其獨創的 「壓縮 + 解碼」 巧妙設計,徹底解決了這一難題。
這項技術首先將所有注意力頭的值向量高效地壓縮為一個低維度的潛在表示 (Latent Representation),從而極大地減少了所需的存儲空間。隨後,通過一個輕量級且高效的 WaLU (Weighted additive Linear Unit) 非線性解碼器,模型能夠根據每一組注意力頭的具體需求,從這個緊湊的潛在表示中動態地、定製化地生成所需的完整值向量。
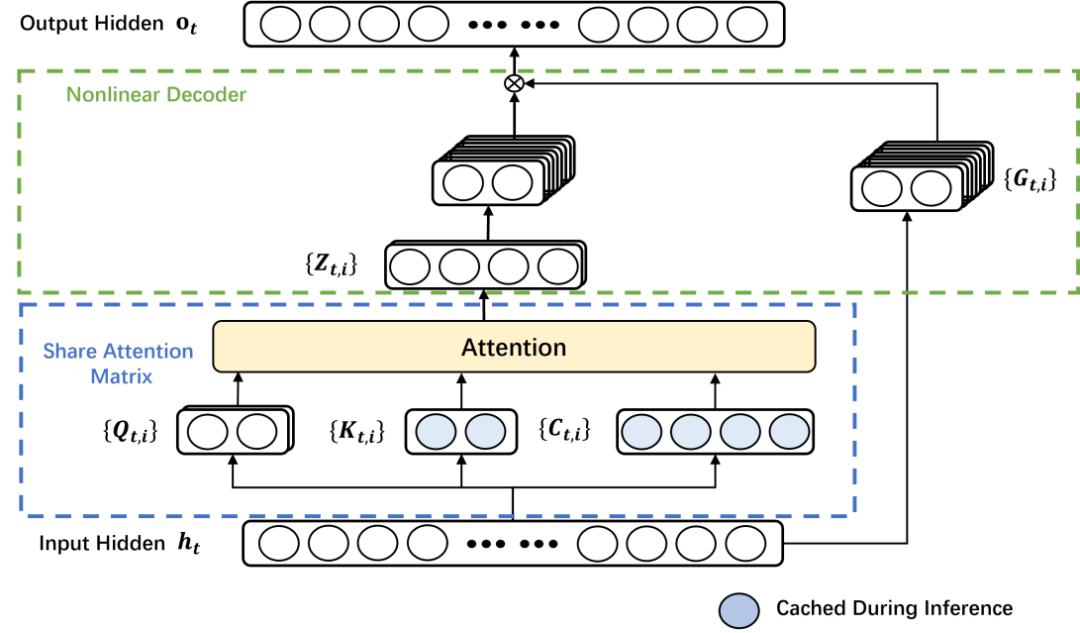
這種創新的方法不僅顯著節省了寶貴的內存資源,同時還巧妙地保留了每個注意力頭所特有的獨特表達能力,避免了信息損失。實驗結果令人鼓舞,GTA 的 KV 緩存規模成功縮減了 70%,這一突破性進展為大型語言模型在性能受限的邊緣設備上的廣泛部署鋪平了道路,使其能夠更普惠地服務於各類應用場景。
實驗驗證:GTA 的卓越性能與效率
研究團隊通過一系列嚴謹而全面的實驗,對 Grouped-head Latent Attention (GTA) 在不同模型規模、輸入序列長度以及多樣化硬件平台上的性能和效率進行了深入評估。實驗結果令人信服地表明,GTA 在大幅度提升計算效率和內存利用率的同時,不僅成功保持了,甚至在某些關鍵指標上超越了現有主流注意力機制的模型性能,展現出其強大的實用價值和廣闊的應用前景。
模型有效性驗證
為了確保實驗結果的公平性和準確性,研究團隊在實驗設計中採取了嚴格的控制變量法:所有非注意力相關的模型參數(例如隱藏層維度、多層感知機 MLP 的大小等)都被固定不變,從而確保模型參數量的任何變化都僅僅來源於注意力機制自身的創新設計。
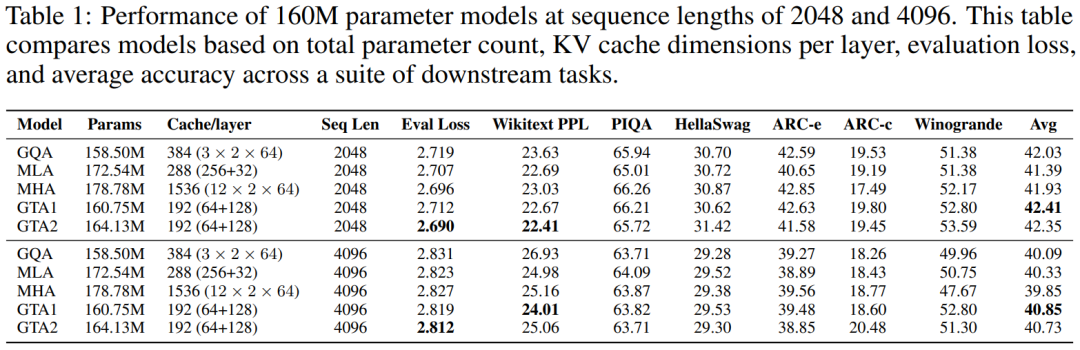
160M 參數模型表現
在針對 160M 參數規模模型的測試中,無論輸入序列長度是 2048 還是 4096 個 token,GTA 都持續展現出卓越的性能優勢。具體而言,採用 GTA2 配置的模型在 2048 token 序列長度下,成功實現了比傳統 MHA、GQA 和 MLA 更低的評估損失,並獲得了更優異的 Wikitext 困惑度(PPL)表現。此外,GTA1 配置的模型在多項下游任務中取得了更高的平均準確率,彰顯了其在實際應用中的有效性。尤為值得強調的是,GTA 在內存效率方面表現出類拔萃,其每層所需的 KV 緩存大小僅為 MHA 的 12.5%(具體數據為 192 維度對比 MHA 的 1536 維度),這一顯著的縮減充分突顯了 GTA 在內存優化方面的強大能力。實驗結果詳細呈現在下方的表格中:
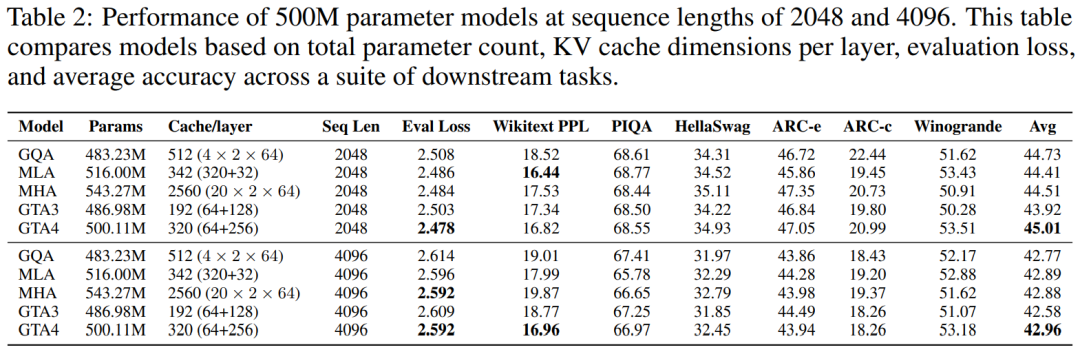
500M 參數模型表現
將模型規模擴展至 500M 參數時,GTA 依然保持了其在性能上的領先地位。在 2048 token 序列長度的測試中,GTA 不僅實現了更低的評估損失,還在下游任務中取得了更高的平均準確率,同時其 Wikitext 困惑度與 MHA 和 GQA 等主流模型保持在同等甚至更優的水平。GTA 持續展現出其獨有的內存優勢,其 KV 緩存大小僅為 MHA 的 12.5%(具體為 320 維度對比 MHA 的 2560 維度),即使在採用更小緩存(例如 192 維度,僅為 MHA 的 7.5%)的情況下,GTA 也能獲得可比擬的性能表現,充分印證了其在內存效率與性能之間取得的完美平衡。在處理 4096 token 長序列的任務中,GTA 不僅能夠與 MHA 的評估損失持平,更在 Wikitext 困惑度和下游任務的平均準確率上提供了更優異的表現。這些詳盡的實驗數據均已在下方的表格中列出:
1B 參數語言模型擴展性
為了進一步驗證 GTA 在大規模模型上的卓越擴展能力和穩定性,研究團隊特意訓練了 1B 參數級別的 GTA-1B 和 GQA-1B 模型。下圖清晰地展示了 GTA-1B 和 GQA-1B 在長達 50,000 訓練步中的損失曲線和梯度範數曲線,從中可以觀察到兩者均展現出令人滿意的穩定收斂趨勢。

儘管 GTA-1B 在設計上採用了更小的緩存尺寸,但其損失軌跡卻與 GQA-1B 高度匹配,這一事實有力地證明了 GTA 內存高效架構的有效性,即在減少資源消耗的同時不犧牲模型學習能力。在多項嚴苛的基準測試中,GTA-1B(包括經過 SFT 微調的版本)均展現出與 GQA-1B 相當甚至更為優異的性能,尤其在平均準確率上取得了顯著提升。這充分表明,GTA 即使在資源受限的環境下,也能通過微調有效泛化到各種複雜任務,保持強大的競爭力。這些詳盡的實驗結果均已在下方的表格中呈現:
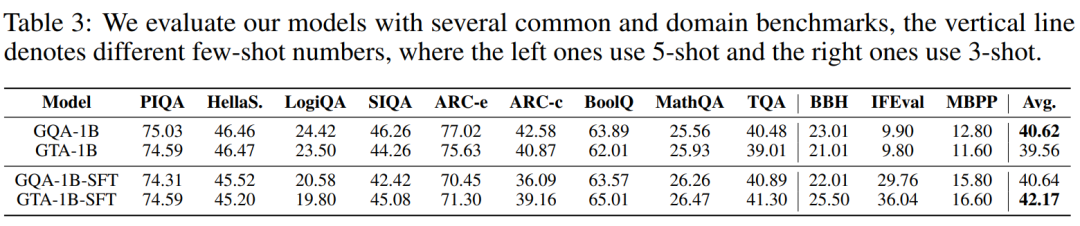
綜合來看,GTA-1B 無論是在基礎模型狀態還是經過微調後,都成功實現了與 GQA-1B 相當的卓越性能。與此同時,其 KV 緩存尺寸僅為 GQA-1B 的 30%,而自注意力計算成本更是低至 37.5%。這些令人矚目的數據有力地強調了內存和計算高效架構在大型語言模型擴展應用方面的巨大潛力,預示着未來 AI 發展將更加註重可持續性和資源效率。
效率評估
理論效率分析
從理論層面分析,GTA 在計算複雜度和內存使用方面均實現了顯著的效率提升。其 KV 緩存尺寸從 MHA 的
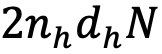
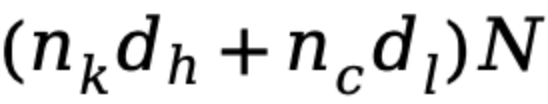
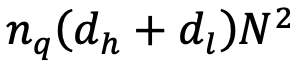
,這直接轉化為推理速度的顯著提升。這些嚴謹的理論分析和對比數據均已在下方的表格中詳細列出:
顯著降低到 GTA 的
,對於參數量龐大的大型模型而言,這意味着一個極其顯著的縮減因子,將有效緩解內存壓力。同時,注意力計算量也從 MHA 的
且
,其中
大幅減少至 GTA 的

通過 LLM-Viewer 進行經驗基準測試
為了將理論優勢轉化為可量化的實際性能,研究團隊利用 LLM-Viewer 框架,在配備 NVIDIA H100 80GB GPU 的高性能計算平台上,對 GTA-1B 和 GQA-1B 進行了全面的經驗基準測試。下圖清晰地展示了在不同配置下,兩種模型的預填充和解碼時間對比。從中可以明顯看出,GTA-1B 在計算密集型的預填充階段和 I/O 密集型的解碼階段都持續地優於 GQA-1B,充分展現了其卓越的延遲特性和更高的運行效率。
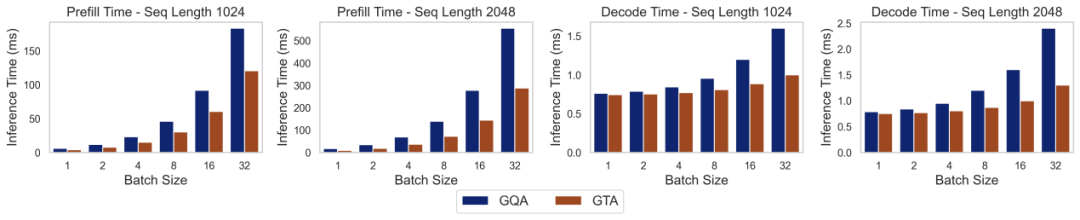
實際部署表現
為了更真實地評估 GTA-1B 在實際應用場景中的性能,研究團隊利用 transformers 庫,在多種異構硬件平台(包括服務器級的 NVIDIA H100、NVIDIA A800,消費級的 RTX 3060,以及邊緣設備如 Apple M2 和 BCM2712)上進行了深入的推理實驗。
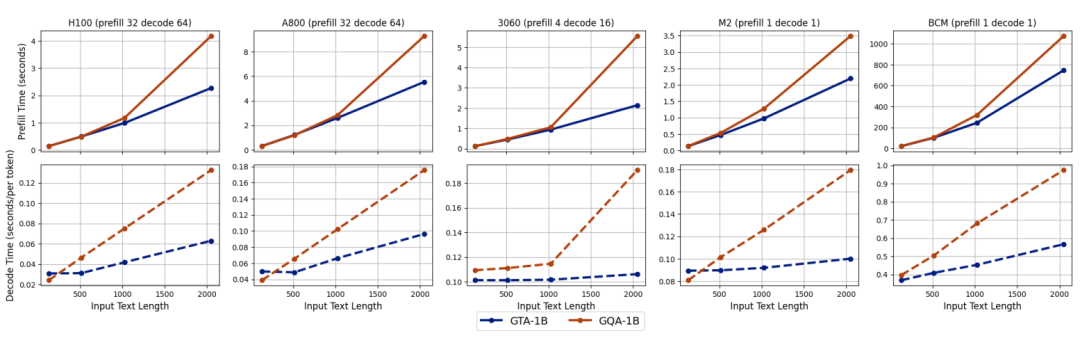
上圖直觀地展示了在不同配置下,GTA-1B 與 GQA-1B 的預填充和解碼時間對比。GTA-1B(藍色實線)在所有測試平台上都持續展現出優於 GQA-1B(橙色虛線)的預填充時間,尤其是在處理 2k token 等更長輸入序列時,性能差距更為顯著,體現了其在處理長文本時的強大優勢。在解碼階段,GTA-1B 同樣表現出卓越的性能,特別是在擴展生成長度時,這種優勢在所有硬件類型上都保持一致,充分突顯了其設計的魯棒性。
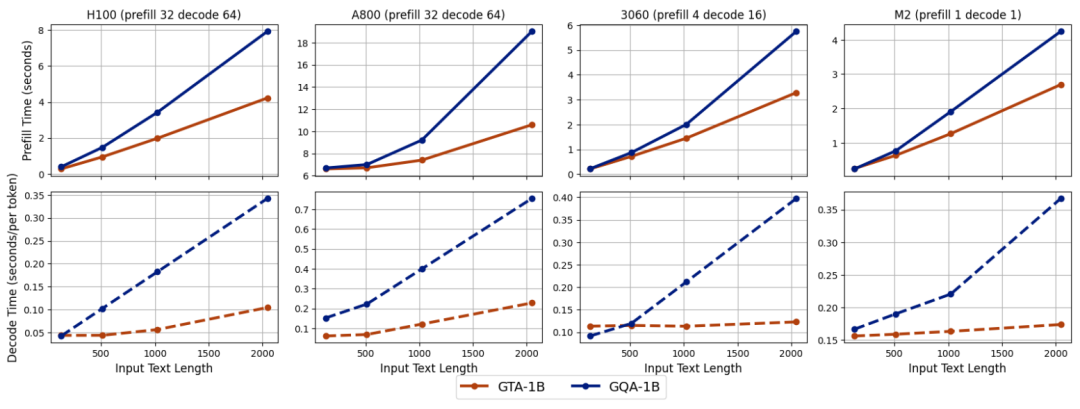
上圖進一步展示了在啓用緩存卸載功能時的性能表現。在 NVIDIA H100 平台上,GTA-1B 在處理更長輸入序列時依然保持了其預填充優勢,並且在解碼時間上實現了比 GQA-1B 更大的改進。這種在所有平台上的持續趨勢,有力地突顯了 GTA-1B 在 I/O 密集型場景中的高效性,這類場景中緩存卸載需要 GPU 和 CPU 內存之間頻繁的數據傳輸,而 GTA-1B 在這種複雜環境下依然表現出色。
綜上所述,GTA-1B 在各種硬件平台下,無論是在預填充還是解碼時間上,均全面超越了 GQA-1B,並在處理更長輸入序列時展現出顯著的性能優勢。它不僅在標準推理設定中表現出色,在啓用緩存卸載的 I/O 密集型條件下也同樣傑出,充分展現了其在不同硬件能力和批處理大小下的強大多功能性。這種卓越的適應性使得 GTA-1B 成為服務器級和消費級部署的理想解決方案,通過顯著降低計算複雜度和內存需求,極大地提升了大型語言模型中注意力機制的整體效率。
技術侷限與未來方向
儘管 Grouped-head latent Attention (GTA) 在效率和性能方面取得了令人矚目的突破,但作為一項新興技術,仍有一些關鍵的技術挑戰需要我們持續關注和深入探索。首先,非線性解碼器在進行模型壓縮的過程中,可能會引入微小的近似誤差,這需要未來的研究在架構設計和訓練策略上進一步優化,確保模型輸出的準確性。其次,當前 GTA 的研究和驗證主要集中在自然語言處理任務上,其在計算機視覺或多模態任務中的適用性和性能表現,還需要進行更廣泛和深入的探索與驗證。
儘管存在這些侷限,研究團隊已經為 GTA 的未來發展制定了清晰且富有前景的後續研究方向。他們計劃持續改進非線性解碼器的架構設計,以期在保證高效解碼的同時,進一步減少信息損失,提升模型性能上限。此外,研究團隊還雄心勃勃地計劃將 GTA 應用於更大規模的模型,以驗證其在超大規模場景下的可擴展性和效率優勢,推動大型語言模型向更廣闊的應用領域邁進。