炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:機器之心Pro)

本文的主要作者來自復旦大學和南洋理工大學 S-Lab,研究方向聚焦於視覺推理與強化學習優化。
先進的多模態大模型(Large Multi-Modal Models, LMMs)通常基於大語言模型(Large Language Models, LLMs)結合原生分辨率視覺 Transformer(NaViT)構建。然而,這類模型在處理高分辨率圖像時面臨瓶頸:高分辨率圖像會轉化為海量視覺 Token,其中大部分與任務無關,既增加了計算負擔,也干擾了模型對關鍵信息的捕捉。
為解決這一問題,復旦大學、南洋理工大學的研究者提出一種基於視覺 Grounding 的多輪強化學習方法 MGPO,使 LMM 能在多輪交互中根據問題,自動預測關鍵區域座標,裁剪子圖像並整合歷史上下文,最終實現高分辨率圖像的精準推理。相比監督微調(SFT)需要昂貴的 Grounding 標註作為監督,MGPO 證明了在強化學習(RL)範式中,即使沒有 Grounding 標註,模型也能從 「最終答案是否正確」的反饋中,湧現出魯棒的視覺 Grounding 能力。
MGPO 的核心創新點包括: 1)自上而下的可解釋視覺推理:賦予了 LMMs 針對高分辨率場景的 「自上而下、問題驅動」 視覺搜索機制,提供可解釋的視覺 Grounding 輸出; 2)突破最大像素限制:即使因視覺 Token 數受限導致高分辨率圖像縮放後模糊,模型仍能準確識別相關區域座標,從原始高分辨率圖像中裁剪出清晰子圖像用於後續分析; 3)無需額外 Grounding 標註:可直接在標準 VQA 數據集上進行 RL 訓練,僅基於答案監督就能讓模型湧現出魯棒的視覺 Grounding 能力。


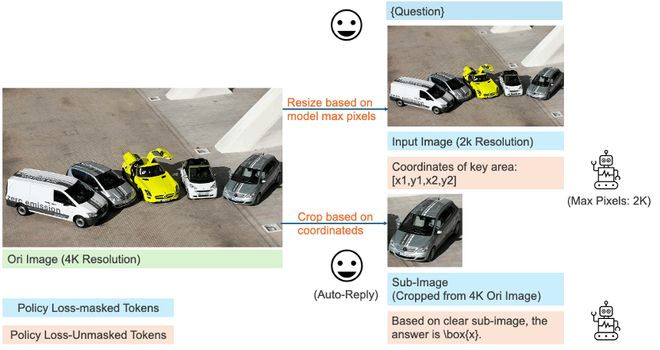
圖 1:基於 MGPO 訓練的模型性能展示,在處理高分辨率圖像時,模型會根據問題輸出關鍵區域座標,然後自動觸發圖像裁剪函數,返回清晰的子圖幫助模型回答問題。
介紹
當前,以 Qwen2.5-VL 為代表的多模態大模型(LMMs)通常基於強大的語言模型(如 Qwen2.5)結合外部原生分辨率視覺 Transformer(NaViT)構建。然而,這類模型在處理高分辨圖像任務時面臨挑戰:高分辨率圖像會轉換成海量視覺 Token,其中大部分與任務無關,既增加了計算負擔,也干擾了模型對關鍵信息的捕捉。
相比之下,在處理高分辨率真實場景時,人類視覺系統會採用任務驅動的視覺搜索策略,首先定位,再仔細審視關鍵興趣區域。受這一生物機制啓發,我們嘗試通過視覺 Grounding 為 LMMs 賦予類似的視覺搜索能力,使其聚焦於圖像中的關鍵區域。
但傳統視覺 Grounding 模型需依賴大量 Grounding 標註進行訓練,而此類標註成本較高。有沒有可能不需要額外 Grounding 標註,僅通過最終答案的正確性對模型進行獎勵,就讓模型自動學會 「找重點」?
我們的答案是:可以。本文提出基於視覺 Grounding 的多輪強化學習算法 MGPO(Multi-turn Grounding-based Policy Optimization),使 LMMs 能在多輪交互中自動預測關鍵區域座標、裁剪子圖像並整合歷史上下文,最終實現高分辨率圖像的精準推理。我們的實驗證明,即使沒有任何 Grounding 標註,模型也能從 「最終答案是否正確」 的獎勵反饋中,湧現出魯棒的視覺定位能力
方法概覽
MGPO 的核心思想是模擬人類的多步視覺推理過程:給定高分辨率圖像和問題,模型先預測關鍵區域的座標,裁剪出子圖像;再結合原始圖像和子圖像的上下文,進行下一步推理。
下圖比較了 MGPO 與 SFT、GRPO 的區別,MGPO 可以僅靠正確答案的監督信息,湧現魯棒的視覺 Grounding 能力。

解決 「冷啓動」:固定兩回合對話模板
在實際訓練中,我們發現 LLMs 在 Rollout 過程中,難以自主在中間過程調用 Grounding 能力,使得 RL 訓練過程緩慢。為了解決模型的冷啓動問題,我們設計了一個固定兩輪對話模板(如下圖所示),在第一輪對話中明確要求模型只輸出與問題相關的區域座標,在第二輪對話中再要求模型回答問題。

處理高分辨率:座標歸一化與子圖像裁剪
受限於模型能夠處理的視覺 Token 數量,高分辨率圖往往會被縮放成模糊圖像,導致細節丟失。如下圖所示,當處理縮放圖像時,MGPO 會先定位到與問題相關的區域,再從原始圖像中裁剪出清晰的子圖,確保模型能夠正確回答相關問題。
實驗結果
1.不同範式對比
基於相同訓練數據下,我們對比了 SFT、GRPO、MGPO 在兩個高分辨率圖像 Benchmark 的表現:MME-Realworld(In-Distribution)和 V* Bench (Out of Distribution)。實驗結果顯示,GRPO 相較於 SFT 並未帶來顯著性能提升,這與之前多模態數學任務的研究結論相反。我們推測,對於高分辨率視覺中心任務,核心挑戰在於讓模型感知細粒度圖像細節,而非進行復雜的長鏈推理。
相比之下,MGPO 取得了顯著提升,相比 GRPO 在 MME-Realworld、V* Bench 分別提升 5.4%、5.2%。我們還將結果與 OpenAI 的 o1、GPT-4o 在 V* Bench 上進行了對比,儘管我們的模型僅基於 7B 模型、用 2.1 萬樣本訓練,經過 MGPO 訓練的模型仍超過了這兩個商業大模型。

2.RL 訓練過程中視覺 Grounding 能力的湧現
我們統計了 GRPO 與 MGPO 兩種 RL 框架訓練過程中,模型生成的有效 Grounding 座標比例。結果顯示,MGPO 的有效比例隨訓練迭代呈現顯著上升趨勢,證明了 MGPO 僅需利用標準 VQA 數據(無需額外 Grounding 標註),就能在 RL 訓練過程中自主湧現出穩定、精準的視覺 Grounding 能力。

總結
MGPO 通過多輪強化學習算法激活視覺 Grounding 能力,有效提升了多模態大模型處理高分辨率圖像時的 「視覺 Token 冗餘」 和 「關鍵信息丟失」 等問題。同時,實驗證明了,相比 SFT 需要昂貴的 Grounding 標註,RL 算法可以僅通過最終答案的獎勵反饋,使得模型自主湧現出魯棒的 Grounding 能力,避免了對昂貴 Grounding 標註的依賴。