只用100行代碼,打造最強輕量編程agent。
SWE-bench、SWE-agent原班人馬再出手,推出全新開源項目——
mini-SWE-agent。

它不依賴任何額外插件,僅通過基礎命令即可運行。而且對模型沒有限制,幾乎兼容所有主流語言模型,支持直接在本地終端中部署和使用。
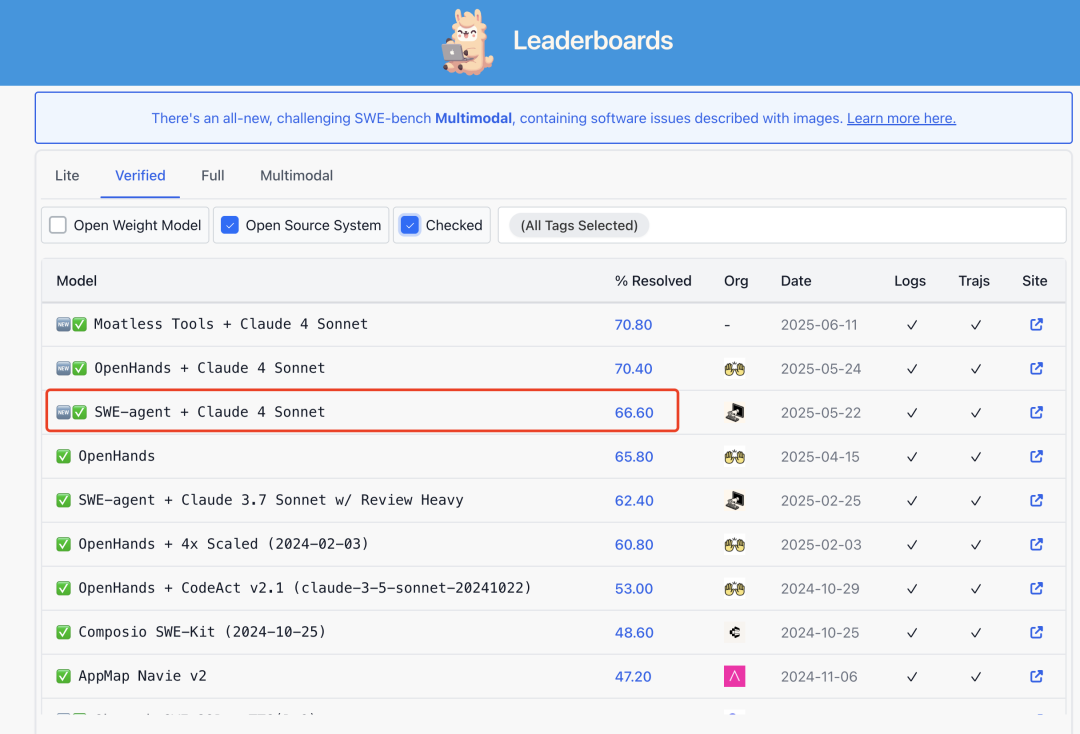
而在如此精簡的架構下,僅憑100行核心代碼輕鬆解決SWE-bench上65%的問題。
這個65%是啥水平呢?
也就和原版差不多吧~(關鍵人家還輕量啊)
網友:厲害👍
百行代碼,實力不打折
SWE-agent是一個開源項目(16.8k GitHub Star),它的目標是讓agent自動修復GitHub上真實項目中的代碼Bug。

不過,原版的SWE-agent基於LangChain構建,從接受issue、理解問題、編輯代碼、到提交PR,涉及多工具、多輪對話管理,任務流程繁瑣。
除此之外,開發者要跑通還需要安裝多個依賴,精調工具調用邏輯,而且項目代碼動輒上千行,對模型、環境的耦合也比較強。
而隨着語言模型性能越來越強大,構建一個有用的代理已經不再需要這些工具和接口了。
由此,團隊開始思考:能否讓SWE-agent小100倍,並保持原有的性能。
mini-SWE-agent由此而來。

那麼,相較於SWE-agent,mini-SWE-agent有什麼不同呢?
極簡代碼和依賴:mini-SWE-agent本身僅約100行Python代碼,加上環境、模型、腳本才共約200行,沒有複雜的依賴關係。
取消工具調用接口:mini版本不集成專用的代碼編輯、搜索等工具;它只使用操作系統的Bash環境執行命令。每一步由語言模型輸出一個完整的shell命令,不通過獨立的「tool call」協議,從而可兼容任何語言模型。
線性歷史記錄:agent的每一步都只是附加到消息中。
獨立單步執行:每條命令通過Python獨立執行,並非保持一個持續的shell會話,這使得在沙盒中執行操作變得非常簡單,並且可以輕鬆擴展。
簡化配置與接口:取消了SWE-agent依賴的複雜YAML配置;mini-swe-agent採用代碼內置模板,並提供直觀的命令行工具。用戶可以通過mini命令快速啓動代理,或使用mini-v啓動可視化界面。
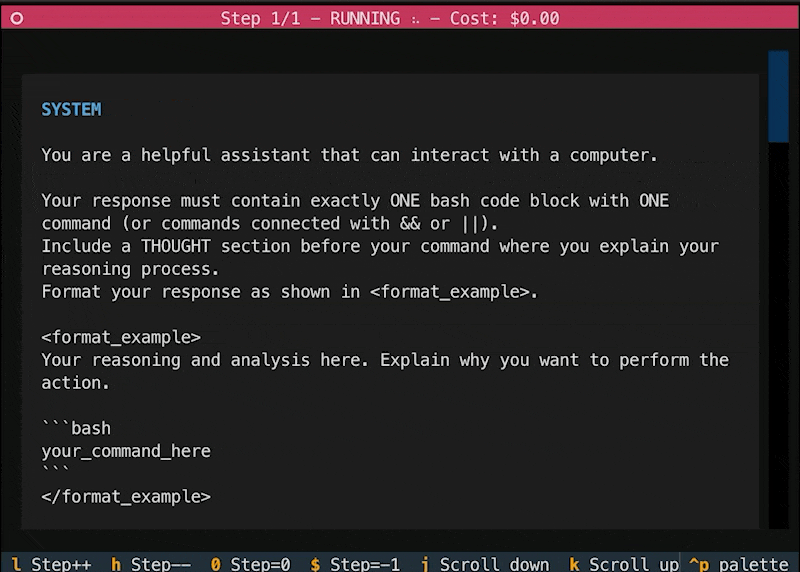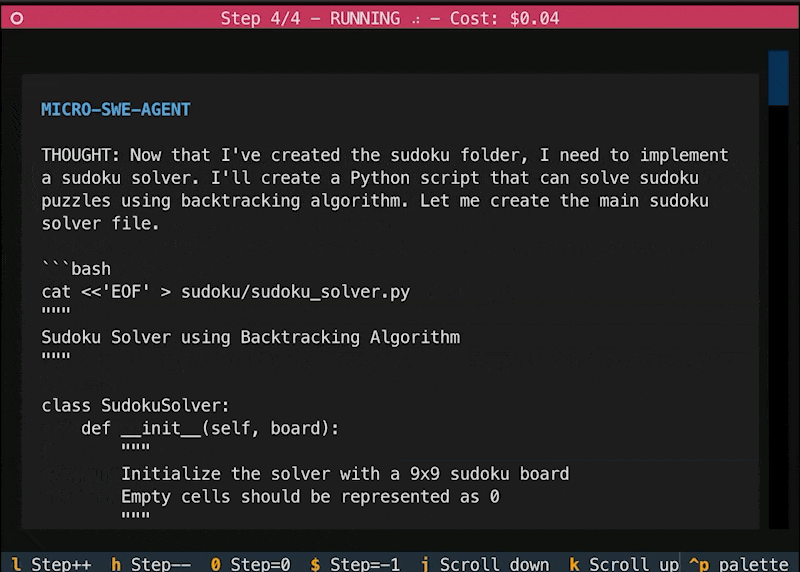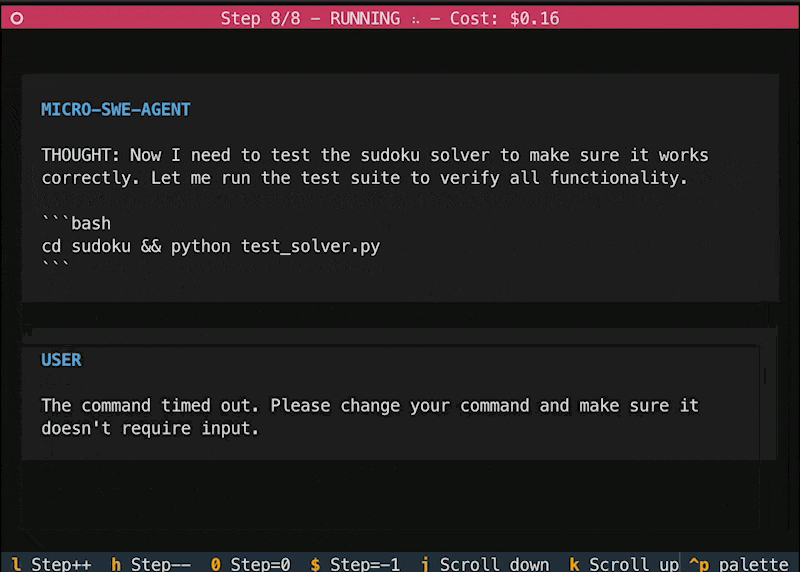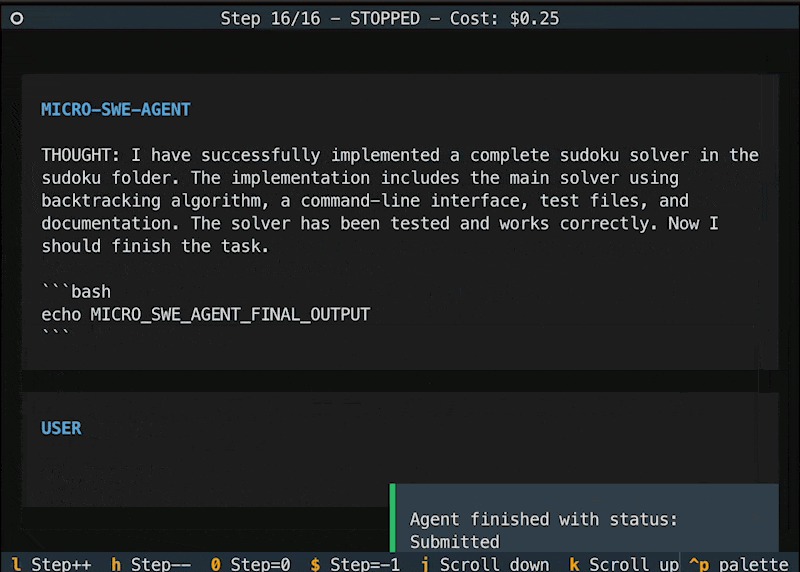
多樣的運行環境支持:除了本地Shell,mini-swe-agent還內置支持多種容器與虛擬化環境(如Docker、Podman、Singularity、Apptainer等),這意味着開發者可以在不同平台和容器中輕鬆部署,而無需額外修改代碼。
保留高性能和工具:雖然架構極簡,mini-swe-agent在SWE-bench驗證集上仍能解決約65%的問題。同時,它附帶批量推理(batchinference)、軌跡瀏覽器(trajectorybrowser)等工具,幫助用戶進行大規模評測和決策分析。代理還提供可視化界面,方便開發者交互式地觀察執行過程
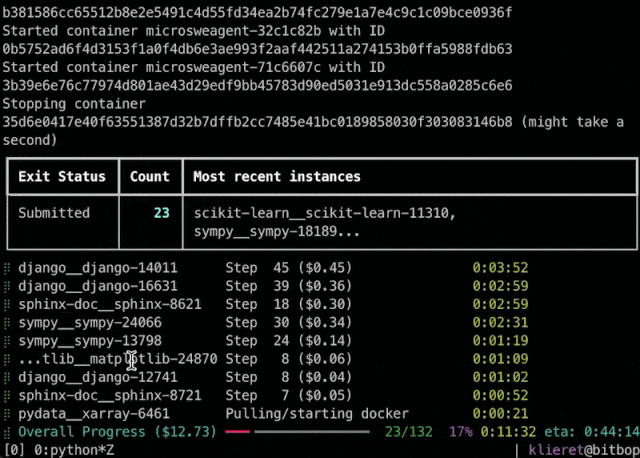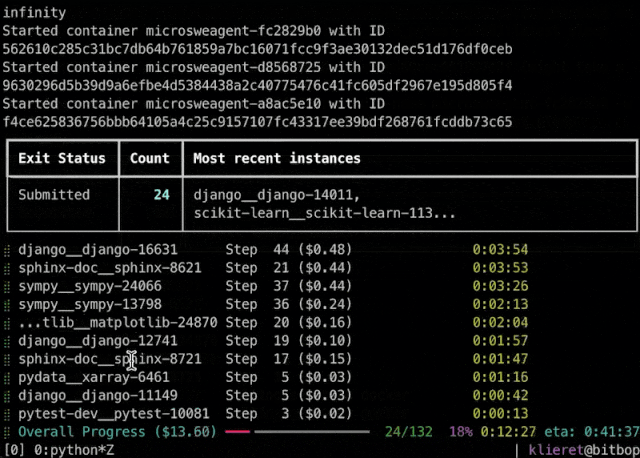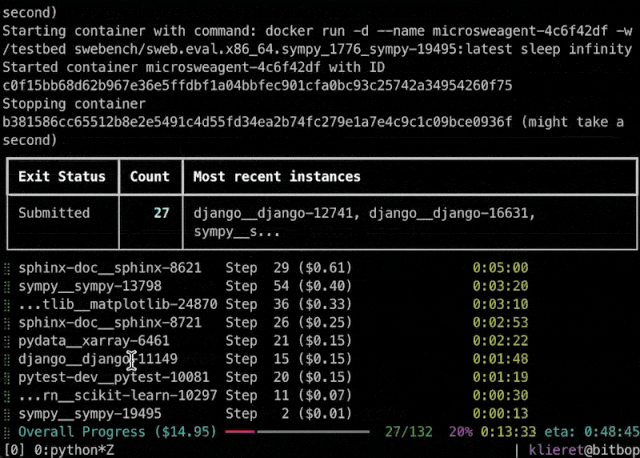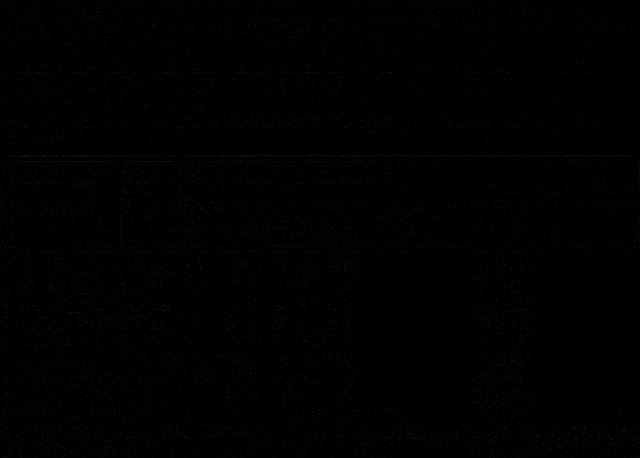
此外,對於應在何種場景下使用 SWE-agent 或 mini-SWE-agent,團隊也根據不同的需求給出了建議:
mini-swe-agent更適合希望快速本地運行、追求簡潔控制流和更穩定評估環境的用戶。它非常輕量,適合用於微調(FT)或強化學習(RL)等實驗,不容易陷入對複雜框架的過擬合。
如果你需要高度可配置的工具鏈、更復雜的歷史狀態管理,或希望通過修改YAML文件自由切換組件而無需動代碼,那麼功能更豐富的SWE-agent會是更合適的選擇。
總體而言,mini-swe-agent體現了可讀、方便、易擴展的開發理念。
對於日常開發者而言,它既可以作為簡單的命令行工具使用。如在本地終端快速解決問題),也可以作為庫被集成到其他Python應用中。
相比於重型框架,它降低了上手成本,讓開發者可以像使用腳本一樣靈活地「駕馭」智能代理。
One more thing
SWE-bench和SWE-agent是由John Yang、Carlos E. Jimenez、Alexander Wettig、Kilian Lieret、姚順雨(OpenAI研究員,2015年畢業清華姚班)、Karthik Narasimhan和Ofir Press於2024年在普林斯頓大學發起的開源項目。
該項目推動了基於大型語言模型的軟件工程代理(Software Engineering Agent)研究。
其中,SWE-bench一經發布後,就成為了評估大語言模型編程的經典benchmark,伴隨SWE-agent一同提出的Agent‑Computer-Interface(ACI)則進一步定義了「智能體如何與計算機交互」的標準接口方式。
而這一傑出的想法最初僅僅來自一次20多分鐘的討論。
在Matthew Berman的播客節目上,Carlos E. Jimenez分享道:SWE-bench最初的想法源自他和John Yang在閒逛時的一次頭腦風暴:

他們意識到,GitHub不只是一個存儲代碼的地方,更是一個活躍的協作開發平台,充滿了真實的軟件工程過程:用戶報告bug,開發者提交修復,社區公開審核和合入。
相比傳統的編程競賽,這些交互和修改纔是真正代表「現實世界編程」的任務。於是他們設想,能否把這種開源協作的過程結構化下來,變成一種評估語言模型能力的標準流程?
這便催生了SWE-bench,一個基於GitHub上真實Issue與PullRequest構建的benchmark,用來測試LLM是否能像人類開發者一樣,理解bug報告並修復代碼。
這個系統不僅更接近現實,也讓模型的「開發能力」變得可觀察、可比較,而SWE-agent則是他們為這一評估任務設計的開源agent,目標就是成為能在SWE-bench上「修最多bug」的AI程序員。
項目主頁:
[1]https://github.com/SWE-agent/mini-swe-agent
[2]https://github.com/SWE-agent/mini-swe-agent?tab=readme-ov-file
— 完 —