
7 月 30 日,ACL(國際計算語言學年會)公布了 2025 年的獲獎論文。令人驚喜的是,這些論文裏的中國作者比例超過 51%,排在第二的美國僅為 14%。
其中,一篇由 DeepSeek 梁文鋒作為通訊作者、與北京大學等聯合發表的論文不僅拿下 Best Paper 獎,相關成果也引發熱議。
現場講座中,該論文的第一作者袁境陽透露,這項技術可以把上下文長度擴展到 100 萬 tokens,並將應用在他們的下一個前沿模型中。據了解,袁境陽當時寫這篇論文時還只是 Deepseek 的實習生。

引入兩大核心技術創新
長上下文建模對於下一代語言模型至關重要,但標準注意力機制的高計算成本帶來了顯著的計算挑戰。隨着序列長度的增加,延遲瓶頸問題愈發凸顯。理論估算表明,在解碼 64k 長度的上下文時,採用 softmax 架構的注意力計算佔總延遲的 70%–80%,這凸顯了對更高效注意力機制的迫切需求。
為解決這些侷限性,有效的稀疏注意力機制在實際應用中必須應對兩項關鍵挑戰:與硬件適配的推理加速,要將理論上的計算量減少轉化為實際的速度提升,就需要在預填充和解碼階段都採用硬件友好型的算法設計,以緩解內存訪問和硬件調度方面的瓶頸;兼顧訓練的算法設計,通過可訓練算子實現端到端計算,在維持模型性能的同時降低訓練成本。
綜合考慮這兩個方面,現有方法仍存在明顯差距。該團隊認為,稀疏注意力為在保持模型能力的同時提高效率提供了一個很有前景的方向。
在獲獎論文中,他們提出了 NSA,這是一種可原生訓練的稀疏注意力(Natively trainable Sparse Attention)機制。它將算法創新與硬件對齊優化相結合,以實現高效的長上下文建模。據介紹,NSA 採用動態分層稀疏策略,結合粗粒度的 token 壓縮和細粒度的 token 選擇,以同時保留全局上下文感知和局部精度。
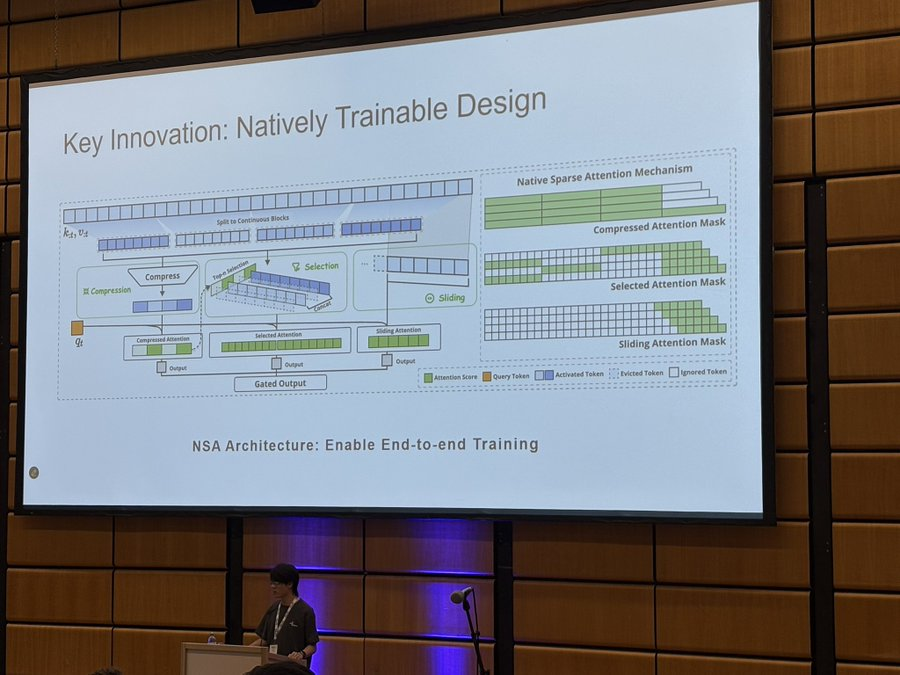
具體來說,NSA 引入了兩項核心創新。
通過算術強度平衡的算法設計實現了顯著的加速,並針對現代硬件進行了實現優化:優化塊式稀疏注意力,以提高張量核利用率和內存訪問,確保均衡的算術強度。
通過高效算法和反向算子實現穩定的端到端訓練,在不犧牲模型性能的情況下減少了預訓練計算量。
上下文處理速度狂飆,
準確率堪稱「完美」
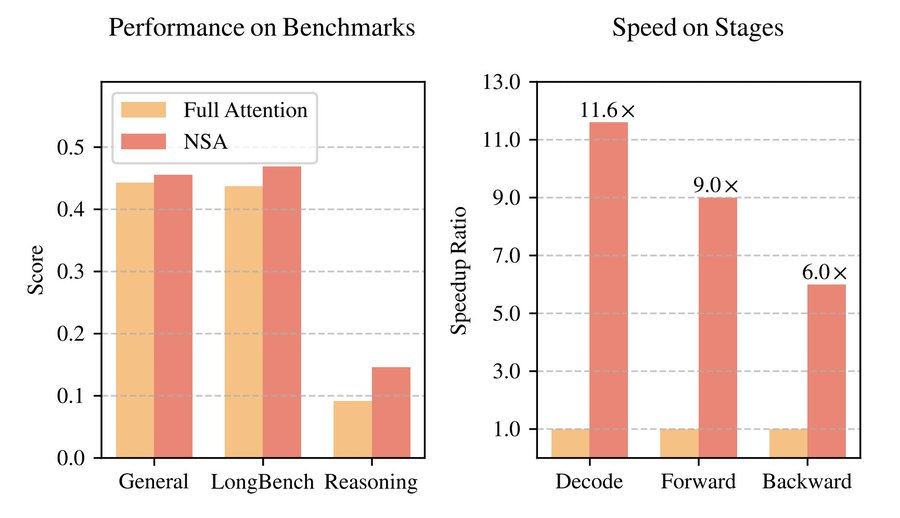
在真實世界語言語料庫上進行綜合實驗評估後,NSA 由於稀疏性過濾掉更多噪聲,在基準測試中產生更好的準確率。據悉,該團隊在一個擁有 270 億參數的 Transformer 骨幹網絡(其中激活參數為 30 億)上,使用 2600 億個 token 進行預訓練,並從通用語言評估、長上下文評估和思維鏈推理評估三個方面評估了 NSA 的性能,還在 A100 GPU 上將其內核速度與經過優化的 Triton 實現作了進一步比較。
實驗結果表明,NSA 的整體性能與全注意力模型相當甚至更優。在 9 項指標中的 7 項上,NSA 均超過了包括全注意力模型在內的所有基線。這表明,儘管 NSA 在較短序列上可能無法充分發揮其效率優勢,但它展現出了強勁的性能。
值得注意的是,NSA 在推理相關的基準測試中取得了顯著提升(DROP:+0.042,GSM8K:+0.034),這說明該團隊的預訓練有助於模型發展出專門的注意力機制。這種稀疏注意力預訓練機制迫使模型聚焦於最重要的信息,通過過濾無關注意力路徑中的噪聲,可能會提升性能。在各類評估中表現出的一致性,也驗證了 NSA 作為通用架構的穩健性。
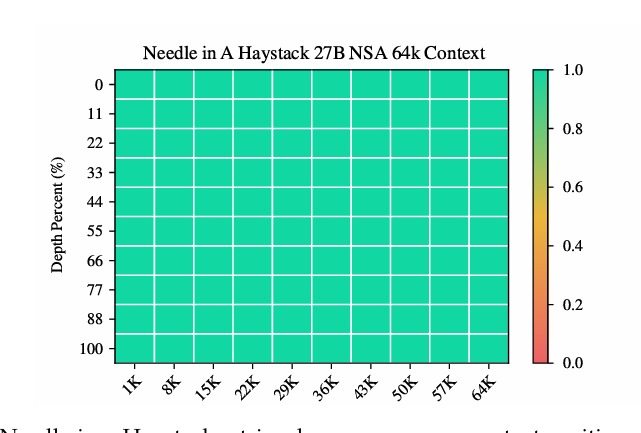
在 64k 上下文的「大海撈針」測試中,NSA 在所有位置都實現了完美的檢索準確率。此外,與全注意力相比,NSA 在解碼、前向傳播和反向傳播方面都實現了顯著的速度提升,且序列越長,提速比例越大。
據該團隊稱,這一性能正是得益於其分層稀疏注意力設計,該設計結合了用於高效全局上下文掃描的 token 壓縮和用於精確局部信息檢索的 token 選擇。粗粒度的 token 壓縮以較低的計算成本識別相關的上下文塊,而對 token 選擇的標記級注意力則確保保留關鍵的細粒度信息。
同時,NSA 優於多種現有的稀疏注意力方法,包括 H2O、infLLM、Quest 以及 Exact-Top。
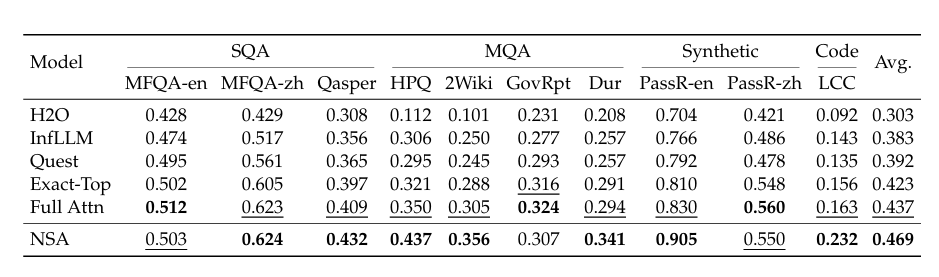
值得注意的是,NSA 在需要對長上下文進行復雜推理的任務上表現出色,在多跳問答任務(HPQ 和 2Wiki)上比全注意力模型分別提升 0.087 和 0.051,在代碼理解任務(LCC)上超出基線模型 0.069,在段落檢索任務(PassR-en)上優於其他方法 0.075。這些結果也驗證了 NSA 處理各種長上下文挑戰的能力,其原生預訓練的稀疏注意力在學習任務最優模式方面帶來了額外優勢。
為評估 NSA 與先進下游訓練範式的兼容性,該團隊研究了其通過後期訓練獲得思維鏈數學推理能力的潛力。鑑於強化學習在較小規模模型上的效果有限,其採用來自 DeepSeek-R1 的知識蒸餾,使用 100 億個 32k 長度的數學推理軌跡進行有監督微調(SFT)。這產生了兩個可比較的模型:全注意力 - R(全注意力基線模型)和 NSA-R(稀疏變體)。
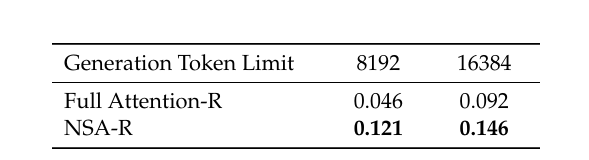
接着,他們在具有挑戰性的美國數學邀請賽(AIME 24)基準上對這兩個模型進行了評估,使用 0.7 的採樣溫度和 0.95 的核採樣值,為每個問題生成 16 個回答並取平均分。並且,為驗證推理深度的影響,他們在兩種生成上下文序列下進行了實驗。結果顯示,NSA-R 在 8k 和 16k 序列長度下的表現均優於全注意力 - R。
這些結果驗證了原生稀疏注意力的兩項關鍵優勢:(1)預訓練的稀疏注意力模式能夠高效捕捉複雜數學推導所必需的長程邏輯依賴關係;(2)我們架構的硬件對齊設計保持了足夠的上下文密度,以支持推理深度的增加,同時避免災難性遺忘。在不同上下文長度下的持續優異表現證實,當稀疏注意力被原生整合到訓練流程中時,其在高級推理任務中具有切實可行性。
計算效率方面,該團隊將基於 Triton 實現的 NSA 注意力機制和全注意力機制,與基於 Triton 的 FlashAttention-2 在 8-GPU A100 系統進行了比較,以確保在相同後端下進行公平的速度對比。
結果表明,隨着上下文長度的增加,NSA 實現了越來越顯著的速度提升。在 64k 上下文長度下,前向速度提升高達 9.0 倍,反向速度提升高達 6.0 倍。值得注意的是,序列越長,速度優勢就越明顯。隨着解碼長度的增加,NSA 的方法延遲顯著降低,在 64k 上下文長度下提速高達 11.6 倍,且這種內存訪問效率方面的優勢也會隨着序列變長而進一步擴大。
值得一提的是,這篇論文早在今年 2 月就對外公布,而相關研究成果至今還沒有出現在任何 DeepSeek 模型中。不過,根據論文一作袁境陽的說法,DeepSeek 下一代模型就將應用這項技術,這也讓許多網友對 DeepSeek V4 的發布更加期待,畢竟其與 DeepSeek R2 的發布計劃似乎也有很大關聯。
早在今年 4 月,就有「DeepSeek R2 提前泄露」的傳言在 AI 圈刷屏。源頭是來自 Hugging Face CEO 發布的一條耐人尋味的帖子,配圖是 DeepSeek 在 Hugging Face 的倉庫鏈接,接着引發不少關於 R2 發布時間和技術細節的各類傳播。但對此,DeepSeek 官方一直未作出回應。
前不久,有外媒報道稱,DeepSeek R2 可能繼續推遲。遲遲未發布的內部原因是 DeepSeek 創始人梁文鋒對該模型當前的性能不滿意,工程師團隊仍在優化和打磨。與此同時,也有人這樣推測:R2 好歹要等 V4 出來再說,V3 可能已經到達極限了。