

自動駕駛
終極答案
(update ver.)
去年,今年,同個時間,同個地點,我們向理想汽車提出同個問題:
自動駕駛的終極答案究竟是什麼?
去年,愛範兒和董車會在理想北京研發中心與理想輔助駕駛團隊進行了一場交流,正值理想輔助駕駛的新技術架構「端到端+ VLM 視覺語言模型」即將上車,團隊當時的表述是:
「端到端+ VLM 視覺語言模型」背後的理論框架,是自動駕駛的「終極答案」。
隨着「端到端+ VLM 視覺語言模型」的技術架構過渡到了 VLA(Vision-Language-Action,視覺語言動作模型),我們離「終極答案」又進了一步。
按照李想和理想輔助駕駛團隊的說法,這是理想輔助駕駛能力從「猴子」階段,進化到「人類」階段的關鍵一步。
今天,我們又來到了理想北京研發中心,繼續和理想輔助駕駛團隊聊這個領域的新動向。

理想汽車自動駕駛研發高級副總裁郎鹹朋
輔助駕駛裏,猴子和人類有什麼區別?
去年理想輔助駕駛方案切換到「端到端+ VLM 視覺語言模型」之前,採用的是業界通用的 「感知 Perception — 規劃 Planning — 控制 Control」技術架構,這個架構依賴工程師根據現實各種各樣的交通情況來編寫對應的規則指導汽車的控制,但難以窮盡現實所有交通情況。
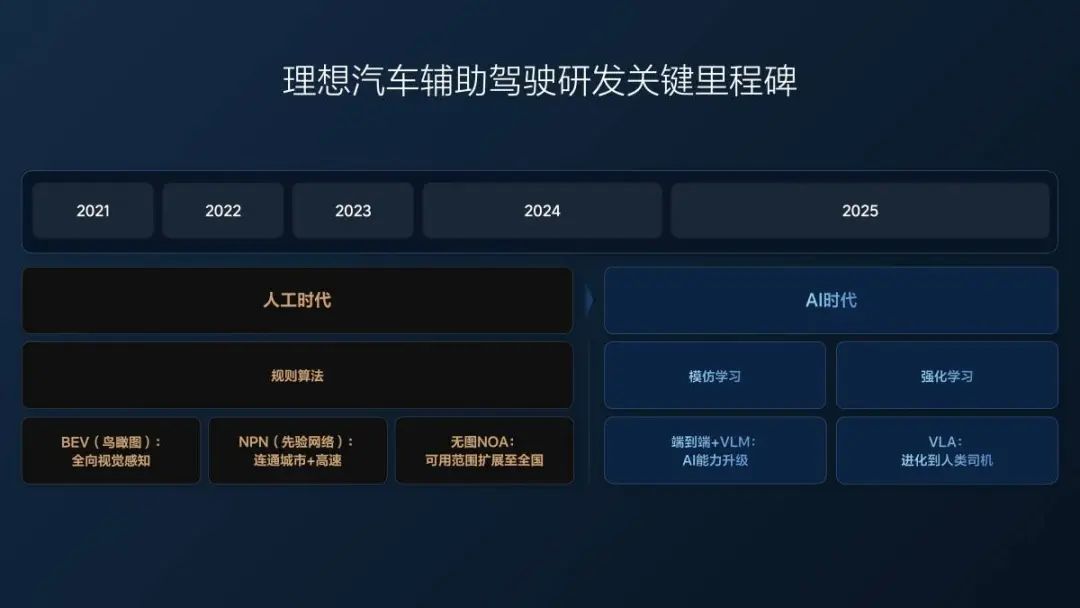
這是輔助駕駛的「機械時期」,輔助駕駛只會應付有對應規則的情況,沒有思考和學習的能力。
「端到端+ VLM 視覺語言模型」是輔助駕駛的「猴子時期」,相比於機械,猴子要更聰明,也有一些模仿和學習的能力,當然,猴子也更好動更不聽話。
「端到端+ VLM 視覺語言模型」的本質就是「模仿學習」,依賴大量人類駕駛數據進行訓練,數據的數量和質量決定性能。並且因為安全考慮,在這個架構中,負責複雜場景的 VLM 視覺語言模型並不能參與控車,只是提供決策和軌跡。

VLA(Vision-Language-Action,視覺語言動作模型)則是輔助駕駛的「人類時期」,擁有了「能思考、能溝通、能記憶、能自我提升」的能力。
猴子經歷了漫長的變化才變成人類,理論上「端到端+ VLM 視覺語言模型」的「模仿學習」也可以在漫長的歲月裏學會人類幾乎所有的駕駛數據,做到行為上幾乎像個人。
但代價就是「時間」。
理想汽車自動駕駛研發高級副總裁郎鹹朋說:
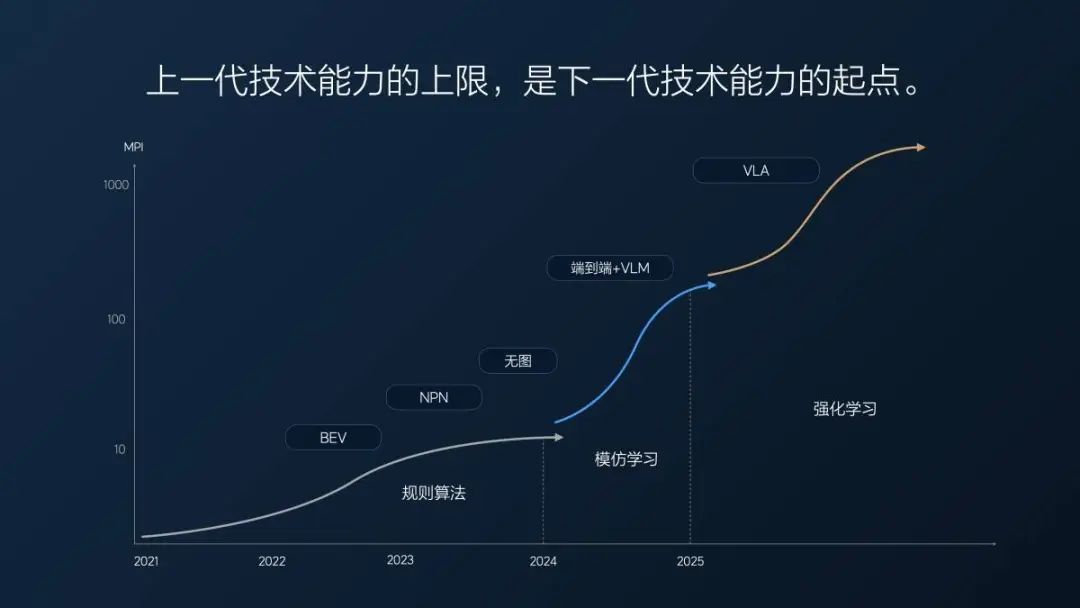
我們去年實際的端到端 MPI(平均接管里程),去年 7 月份第一個版本 MPI 大概在十幾公里,當時已經覺得挺不錯的,因為我們的無圖版本迭代了很長時間,綜合 MPI(高速+城市)也就 10 公里左右。
從 100 萬到 200 萬 Clips(用於訓練端到端輔助駕駛的視頻片段),再到 1000 萬Clips,隨着數據量上升,今年年初,MPI 達到 100 公里,7 個月 MPI 翻了 10 倍,平均一個月翻一點幾倍。
但是到了 1000 萬 Clips 之後,我們發現一個問題,只增長數據量是沒有用的,有價值的數據越來越少。這就跟考試一樣,不及格的時候,隨便學一學分就提升非常快。當考到八九十分了,再往上提 5 分、10 分,是很難的。
這時候我們使用了超級對齊,強制讓模型輸出符合人類要求的結果。另外,我們也篩選了一些數據補充到超級對齊裏,讓模型能力進一步提升,這樣做是有一定效果的,但我們大概從今年 3 月份到 7 月底,花了 5 個月時間,模型性能才提升了 2 倍左右。
這是「端到端+ VLM 視覺語言模型」技術架構在飛速進步後遇到的第一個問題:越往後,有用數據越稀少,模型性能進步的速度也越慢。

而其本質問題也隨之暴露出來,郎鹹朋說:
本質來看,現在端到端的這套模仿學習並不具備深度的邏輯思考能力,就像猴子開車一樣。喂猴子一些香蕉,它可能會按照你的意圖做一些行為,但並不知道自己為什麼要做這些行為,一敲鑼它就過來,一打鼓它就跳舞,但不知道為什麼要跳舞。 所以說端到端架構不具備深度思考能力,頂多算是一個應激反應,就是給一個輸入,模型給一個輸出,這背後沒有深度邏輯。
這也是為什麼要在端到端大模型之外再加一個 VLM 視覺語言模型的緣故,VLM 視覺語言模型具有更強的理解和思考能力,能提供更好的決策。但這個模型一是思考得慢,二是和端到端大模型耦合得不夠深,很多時候端到端大模型理解和接受不了 VLM 視覺語言模型的決策。
去年這個時候,理想輔助駕駛團隊就說過:
以後兩個趨勢,第一是模型規模變大,系統一和系統二現在還是端到端加 VLM 兩個模型,這兩個模型有可能合一,目前是比較松耦合,將來可以做比較緊耦合的。第二方面也可以借鑑現在多模態模型的大模型發展趨勢,它們就朝這種原生多模態走,既能做語言也能做語音,也能做視覺,也能做激光雷達,這是將來要思考的事情。
趨勢很快就變成了現實。
郎鹹鵬也說了為什麼要從端到端+VLM 切換到 VLA 的原因:
去年做端到端的時候一直也在反思,是不是端到端就夠了,如果不夠的話我們還需要再做什麼。 我們一直在做 VLA 的一些預研,其實 VLA 的預研代表的是我們對人工智能的理解並不是一個模仿學習,一定像人類一樣是有思維的,是有自己推理能力的,換句話說它一定要去有能力解決它沒有見過的事情或未知的場景,因為這個在端到端裏可能有一定的泛化能力,但並不是足以說有思維。
就像猴子一樣,它可能也會做出一些你覺得超越你想象的事情,但它不會總做出來,但人不是,人是可以成長的、可以迭代的,所以我們一定要按照人類的智能發展方式去做我們的人工智能,我們就很快從端到端切換到 了VLA 方案去做。
VLA(Vision-Language-Action,視覺語言動作模型)就是去年的趨勢思考,以及當下成為現實的技術架構。
雖然 VLA 和 VLM 就差了一個字母,但內涵差異非常大。
VLA 的 Vision 指各種傳感器信息的輸入,也包括導航信息,能夠讓模型對空間有理解和感知。
VLA 的 Language 指模型會把感知到的空間理解,像人一樣總結、翻譯、壓縮、編碼成一個語言表達出來。
VLA 的 Action 是模型根據場景的編碼語言,生成行為策略,把車開起來。
直觀的差異就是,人可以用語言去控車,說話就可以讓車慢點快點左轉右轉,這主要是 Language 部分的功勞,人的指令大模型收到的 prompt,VLA 模型內部的指令也是 prompt,等於是打通了人和車。
此外,視覺和行為之間,也沒有阻礙了,從視覺信息輸入到控車行為輸出的速度和效率都大大加快,VLM 慢,端到端不理解 VLM 的問題被解決了。
更顯著的差別是思維鏈(Chain of Thought,CoT)能力,VLA 模型的推理頻率達到了 10Hz,比 VLM 的推理速度快了 3 倍多,同時對環境的感知和理解更充分,可以更快更有理有據地進行思維推理,生成駕駛決策。
除了思維能力和溝通能力之外,VLA 也具備一定的記憶能力,可以記住車主的偏好和習慣;以及相當強的自主學習能力。

理想 i8 是理想 VLA 技術的首發車型
理想輔助駕駛的《飛馳人生》
現實世界裏,人類想要成為老司機,肯定先得去報個駕校考個駕照,然後貼「實習標」蹣跚上路,在真實道路上開幾年時間。
此前輔助駕駛的訓練也是如此,不光需要真實世界裏的行駛數據用作訓練,也需要在真實世界裏進行大量的路試。
在一些小說裏,有些天賦異稟的選手可以通過讀書,讀成武力境界超高的實戰高手,比如《少年歌行》裏的「儒劍仙」謝宣,《雪中悍刀行》裏的軒轅敬城。
但是在傳統武俠小說裏,只會有《天龍八部》裏王語嫣這樣精通武學典籍,自身卻是毫無實戰能力的戰五渣。

《飛馳人生》劇照
當然,也有介於中間態的情況:在賽車電影《飛馳人生》裏,落魄賽車手張弛在腦海裏不斷復現巴音布魯克地區的複雜賽道情況,每天在腦海裏開 20 遍,5 年模擬開了 36000 多遍,然後回到真實賽道的時候,成為了冠軍。
虛擬開車,不斷精進,超越自己過去的最好成績,這是「算法」。
不過張弛迴歸賽道,再次成為冠軍車手之前就已經在這條賽道多次證明過自己,積累了大量的實際駕駛經驗。
實車實路,積累經驗,直到了解這條賽道所有的路況,這是「數據」。

郎鹹朋說,想要做好 VLA 模型,需要四個層面的能力:數據,算法,算力和工程能力。
理想強調自己數據多,數據優秀,數據庫好,以及數據標註和數據挖掘準已經很久了,關於數據,理想也有新技能:生成數據訓練。

通過世界模型進行場景重建,然後在重建的真實數據之上,舉一反三,生成相似場景,比如理想在世界模型裏重建一個出高速 ETC 的場景,在這個場景下,不僅可以用原來的真實數據情況,比如白天晴朗地面乾燥,也可以生成出白天大雪地面溼滑,夜晚小雨能見度不佳等等場景。
理想訓練 VLA 模型算法的更迭也跟生成數據息息相關,郎鹹朋介紹說:
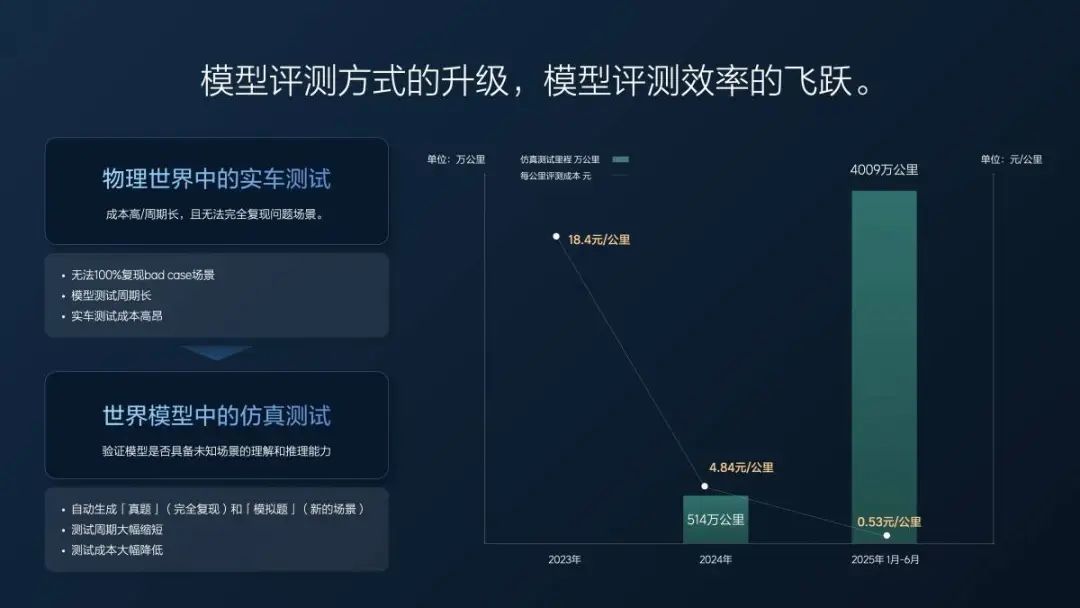
2023 年我們還沒做端到端,一年用實車的有效測試里程大概 157 萬公里,每公里花 18 塊錢。 我們開始做端到端的時候,就有一部分在做仿真測試了,2024 年全年的仿真測試仿了 500 萬公里左右,實車也測了 100 多萬公里,平均下來成本降到了 5 塊錢一公里不到,差不多也是花了 3000 萬左右。但是同樣花 3000 萬,我能測 600 萬公里了。
今年半年時間(1 月 1 日-6 月 30 日),我們測了 4000 萬公里,實車只有 2 萬公里,就跑一些基本的場景。所有的測試,大家看到的超級對齊、現在的 VLA,我們都是用仿真測的,5 毛錢一公里,就是付個電費,付個服務器的費用。並且測試質量還高,所有的 case、所有的場景都能舉一反三,可以完全複測,分毫不差。我們的測試里程多了,測試質量好了,研發效率就提升了。 所以很多人質疑我們不可能用半年做個 VLA,測都測不過來,實際上我們測試非常多。
仿真測試的優點除了成本低之外,還能完美復現場景,真實場景測試情況下,一個場景很難被 100% 還原,對於 VLA 模型來說,場景復現差之毫釐,駕駛表現可能就失之千里。

以此而言,理想訓練 VLA 模型的形式,與電影《飛馳人生》裏主角在真實駕駛經驗基礎上,不斷地虛擬訓練的模式,有一些類似。
當然,最後 VLA 模型的訓練,也需要背後巨大算力的支撐,理想現在的總算力為 13EFLOPS,其中 3EFLOPS 給了推理,10EFLOPS 給了訓練。換算成顯卡數量,是等效 2 萬張英偉達 H20 用作訓練,等效 3 萬張英偉達 L20 用於推理。

關鍵 Q&A
Q:智能輔助駕駛存在一個「不可能三角」,也就是效率、舒適和安全三個目標之間是互相制約的,目前階段可能難以同時實現。理想汽車的 VLA 目前在當前階段最先優化的指標是哪一個?啱啱提及到 MPI,是否可以理解為目前理想汽車最終的指標是提升安全性以有效減少接管?
郎鹹朋:MPI 是我們衡量的指標之一,還有一個指標是 MPA,也就是指發生事故的里程,理想車主的人駕數據是 60 萬公里左右出一次事故,而在使用輔助駕駛功能的情況下是 350 到 400 萬公里發生一次事故。這個里程數據我們還會持續提升,我們的目標是將 MPA 能提升到人類駕駛的 10 倍,也就是比人駕安全 10 倍,做到 600 萬公里纔出一次事故,但這必須等到 VLA 模型提升之後才能做到。
針對 MPI,我們也做過分析,可能一些安全風險問題會導致接管,但有時候舒適度不好也會導致接管,比如急剎、重剎等,因為並不一定每次都會遇到安全風險,但是如果駕駛舒適度不好,用戶依然不想用輔助駕駛功能。因為 MPA 可以衡量安全性,在 MPI 方面,除了安全性之外,我們重點提升了行車舒適度,如果體驗了理想 i8 的輔助駕駛功能,會體驗到舒適度比之前的版本有很大提升。
效率是排在安全和舒適之後的,比如走錯路,雖然效率有所損失,但我們不會通過一些危險的動作立刻糾正,還是要在安全和舒適的基礎上去追求效率。

Q:VLA 模型的難點在哪裏?對企業的要求是什麼?如果一個企業想要落地VLA模型會面臨哪些挑戰?
郎鹹朋:曾經也有很多人問過如果車企想做 VLA 模型是不是可以跳過前面的規則算法,跳過端到端階段,我認為是不行的。
雖然 VLA 的數據、算法等可能跟之前不太一樣,但是這些仍然是要建立在之前的基礎上的,如果沒有完整的通過實車採集的數據閉環,是沒有數據能夠去訓練世界模型的。理想汽車之所以能夠落地 VLA 模型,是因為我們有 12 億數據,只有在充分了解這些數據的基礎上,才能夠更好的生成數據。如果沒有這些數據基礎,首先不能訓練世界模型,其次也不清楚要生成什麼樣的數據。
同時,基礎訓練算力和推理算力的支撐需要大量資金和技術能力,如果沒有之前的積累是不能完成的。
Q:今年理想實車測試是 2 萬公里,請問大幅減少實車測試的依據是什麼?
郎鹹朋:我們認為實車測試有很多問題,成本是其中一方面,最主要的是我們在測試驗證一些場景時不可能完全復現發生問題時的場景。同時,實車測試的效率太低了,在實車測試過程中要開過去之後再複測回來,我們現在的仿真效果完全可以媲美實車測試,現在的超級版本和理想 i8 的 VLA 版本中 90% 以上的測試都是仿真測試。
從去年端到端版本我們就已經開始進行仿真測試的驗證,目前我們認為它的可靠性和有效性都很高,所以我們以此替代了實車測試。但仍有一些測試是無法替代的,比如硬件耐久測試,但和性能相關的測試我們基本上會使用仿真測試替代,效果也非常好。
工業時代來臨後,刀耕火種的流程被機械化替代;信息時代後,網絡替代了大量工作。在自動駕駛時代也是一樣,端到端時代來臨後,我們進入了使用 AI 技術做自動駕駛的方式,從僱佣大量工程師、算法測試人員,到數據驅動,通過數據流程、數據平台和算法迭代提升自動駕駛能力。而進入了 VLA 大模型時代,測試效率是提升能力的核心因素,如果要快速迭代,一定要把在流程中影響快速迭代的因素迭代掉,如果這其中仍有大量的實車和人工介入,速度是會降低的。並不是我們一定要替代實車測試,而是這項技術,這個方案本身就要求要使用仿真測試,如果不這樣做,並不是在做強化學習,並不是在做 VLA 模型。
Q:VLA 其實沒有顛覆端到端+VLM,所以是否可以理解成 VLA 是偏向於工程能力的創新?
詹錕(理想汽車自動駕駛高級算法專家):VLA 不只是工程方面的創新,大家如果關注具身智能,會發現這波浪潮伴隨着大模型對物理世界的應用,這本質就是提出了一個 VLA 算法,我們的 VLA 模型就是想把具身智能的思想和路徑引用在自動駕駛領域。我們是最早提出,也是最早開始實踐的。VLA 也是一種端到端,因為端到端的本質是場景輸入,軌跡輸出,VLA 也是如此,但算法的創新是多了思考。端到端可以理解為 VA,沒有 Language,Language 對應的是思考和理解,我們在 VLA 中加入了這一部分,把機器人的範式統一,讓自動駕駛也能成為機器人的一類,這是算法創新,不只是工程創新。
對於自動駕駛而言,很大的挑戰是必須要有工程創新。因為 VLA 是一個大模型,大模型部署在邊緣端算力上是非常具有挑戰的。很多團隊並不是認為 VLA 不好,而是因為 VLA 部署有困難,把它真正落地是非常具有挑戰性的事情,尤其是在邊緣端芯片算力不夠的情況下是不可能完成的,所以我們是在大算力芯片上才能部署。所以這不僅僅是工程創新,但的確需要工程部署大範圍優化才能實現。
Q:VLA 大模型在車端部署的時候是否會有比如模型裁剪或蒸餾版本?如何在推理效率和模型之間做好平衡?
詹錕:在部署時的效率和蒸餾上我們做了非常多平衡。我們的基座模型是自研的 8x0.4B 的 MoE 模型(混合專家模型),這是業界沒有的,我們在深入分析英偉達芯片後,發現這個架構非常適合它,推理速度快的同時模型容量大,能夠同時容納不同場景、不同能力的大模型,這是我們在架構上的選擇。
另外,我們是大模型蒸餾出來的,我們最早訓練了一個 32B 的雲端大模型,它容納了海量的知識和駕駛能力,我們把它做出的思考和推理流程蒸餾到 3.2B 的 MoE 模型上,配合 Vision 和 Action,使用了 Diffusion 技術(擴散模型,可以生成圖像、視頻、音頻,動作軌跡等數據,具體到理想的 VLA 場景,是利用 Diffusion 生成行車軌跡)。
我們用這樣的方法做了非常多的優化。從細節上來看,我們也針對 Diffusion 做了工程優化,並不是直接使用標準 Diffusion,而是進行了推理的壓縮,可以理解為一種蒸餾。以前 Diffusion 可能要推理 10 步驟,我們使用了 flow matching 流匹配只需要推理 2 步就可以了,這方面的壓縮也是導致我們真正能夠部署 VLA 的本質原因。

Q:VLA 是一個足夠好的解法了嗎?它抵達所謂的「GPT 時刻」還需要花多長時間?
詹錕:多模態模型之前說沒有達到 GPT 時刻,可能指的是 VLA 這種物理 AI,而不是 VLM,其實現在 VLM 已經完全滿足一個非常創新的「GPT 時刻」標準,如果針對物理 AI,現在的 VLA,特別是在機器人領域、具身智能領域可能並沒有達到「GPT 時刻」的標準,因為它沒有那麼好的泛化能力。
但在自動駕駛領域,其實 VLA 解決的是一個相對統一的駕駛範式,是有機會用這個方式做到一個「GPT 時刻」的,我們也非常承認現在的 VLA 是第一版本,也是業界第一個往量產上要推的 VLA 版本,肯定會存在一些缺陷。
這個重大嘗試是想說我們想用VLA來探索一個新的路徑,它裏面有很多嘗試的地方,有很多需要去落地的探索的點,不是說不能做到「GPT 時刻」就一定不能去做量產落地,它有很多細節,包括我們的評測、仿真去驗證它能不能做到量產落地,能不能給用戶「更好、更舒適、更安全」的體驗,做到以上三點就可以給用戶更好的交付。
「GPT 時刻」更多指的是具有很強的通用性和泛化性,在這個過程可能隨着我們自動駕駛往空間機器人或往其它具身領域去拓展的時候會產生出更強的泛化能力或者更綜合的統籌能力,我們也會在落地以後隨着「用戶數據迭代、場景豐富、思維邏輯性越來越多、語音交互越來越多」逐漸往 ChatGPT 時刻遷移。
像郎博(郎鹹朋博士)說的,到明年我們如果到了 1000MPI,可能會給用戶這種感覺:真的到了一個 VLA 的「GPT 時刻」。