炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:字母榜)

硅谷AI圈今年夏天的諸神之戰昨夜正式拉開序幕——OpenAI在GPT-2之後終於再次擁抱開源,發布了一個「號稱」最強的開源推理大模型gpt-oss.

谷歌同樣沒閒着,直接丟出了一個「開天闢地」式的大殺器——Genie 3。它可以讓用戶一句話生成一個長達數分鐘的可以交互的三維虛擬世界,效果炸裂。
而OpenAI的老冤家,不認AGI只管在AI編程賽道上矇眼狂奔的Anthropic也不甘寂寞。它更新了自己最頂(gui)級的大模型:Claude Opus 4.1,將AI編程能力的上限再次提升。

雖然在不同維度上,昨晚的3個新產品發布都具有相當重要的意義,但是這還只是未來幾天硅谷AI圈「神仙打架」的序幕,好戲還在後面呢。
而且就像御三家之前發布的所有產品一樣,背後團隊中,國人依然是中流砥柱。所以,就連硅谷的喫瓜群衆,也在期待來自東方的DeepSeek和Qwen。希望國內的AI力量,不會缺席這場夏末的AI盛宴。

01
OpenAI終於迎來了他的DeepSeek時刻
OpenAI時隔6年首次推出「開放權重」大語言模型:gpt-oss-120b和gpt-oss-20b。兩個模型都採用了Transformer架構,並融入MoE設計。gpt-oss-120b總參數1170億,激活參數51億。gpt-oss-20b總參數210億,每token激活36億參數。
模型採用了分組多查詢注意力機制,組大小為8,以及旋轉位置編碼(RoPE),原生支持128k上下文。
性能上來看,OpenAI官方的說法是現在同體量下開源推理模型的SOTA:
gpt-oss-120b模型在覈心推理基準測試中實現了與 OpenAI o4-mini 接近的性能,可以在單張80 GB GPU 上高效運行。gpt-oss-20b 在常見基準測試中能達到與 OpenAI o3-mini 類似的性能,可以在僅具有 16 GB 內存的端側運行。

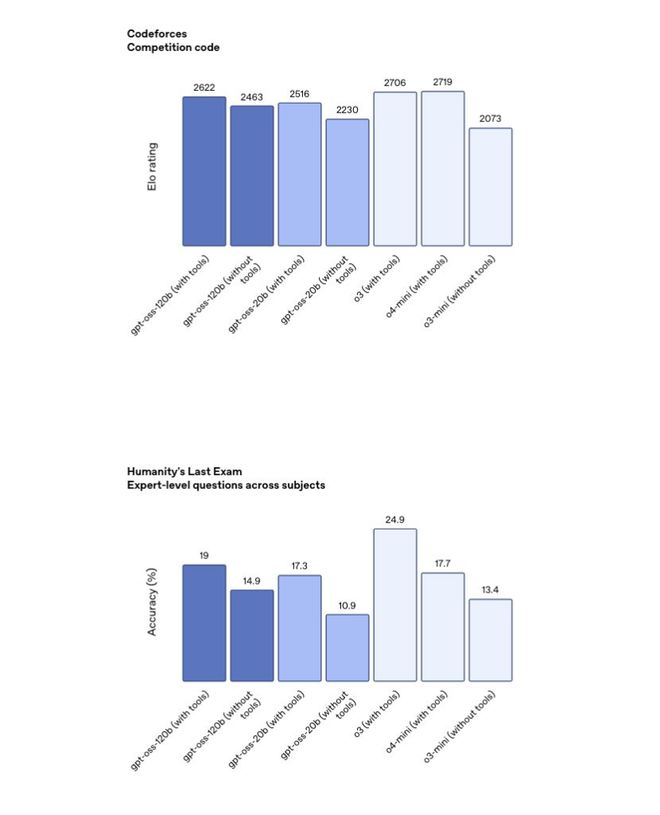
從模型體量上來看,OpenAI這次放出的兩個模型都是針對的本地部署的需求和市場,補齊之前的產品層面的短板。而且在許可證裏,依然很雞賊的進行了限制,不允許年收入高於1億美元或者日活超過100萬的實體商用。
發布之後,網友們也迫不及待地進行了本地化的部署,性能反饋還不錯。

在RTX5090上運行20B的版本,每秒能達到160-180tokens的輸出速度。
模型能力上看,用戶的實際反饋也都還不錯。這位網友在M4 MacBook上一次通過了3個常用的編程能力測試。

根據大模型能力測試機構Intelligence Evaluation公布的衆測結果,OpenAI這兩款模型的性能確實在遠遠小於DeepSeek R1和Qwen 3的體量下,獲得了接近於兩個中國開源模型的性能。
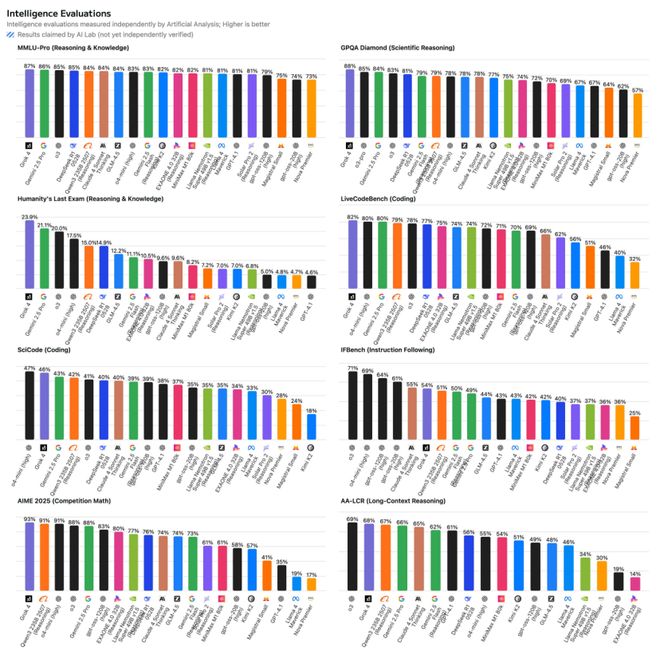
客觀地說,這次模型的發布最大的意義在於讓OpenAI再次回到了開源牌桌之上,讓用戶也多了一個方便單機本地部署,能力還不錯的模型可以選擇,但也只能算是一次補作業式的發布。而所有人對OpenAI的期待,依然還是落在之後到來的GPT-5上,到底OpenAI能給業界還能帶來多大的震撼,讓我們拭目以待。
02
谷歌Genie 3:炸裂,但是期貨
雖然OpenAI沒有放出GPT-5,但是谷歌也不會允許OpenAI獨食流量,發布了一個非常「戰未來」的模型——Genie-3。
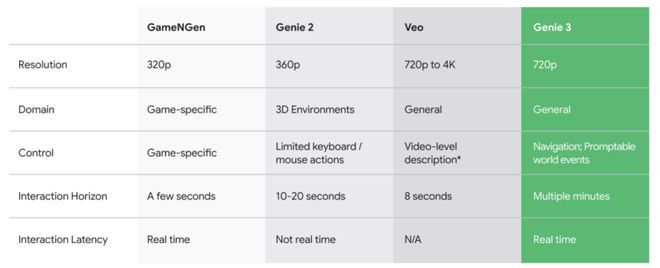
像開頭的視頻一樣,這是一個文生虛擬世界的模型,允許用戶用文字生成一個720p清晰度24 FPS流暢度的動態世界實時交互的世界模型,具有非常好的一致性和真實感。用戶可以自己用文字或按鈕的方式來控制探索這個世界中的各個細節。
 圖注:走到一個鋁架子旁邊,然後走到那個大型的紅色工業攪拌機旁邊
圖注:走到一個鋁架子旁邊,然後走到那個大型的紅色工業攪拌機旁邊通俗一點來說,如果說像Sora或者Veo 3這樣的文生視頻模型對應的是電影的話,Genie-3生成的就是一個遊戲或者說一個虛擬劇本殺。用戶不僅是在螢幕前看這個世界,更可以主動的通過自己的行為,和這個生成的世界進行互動。
而不同於視頻模型的是,這樣的「世界模型」需要對用戶的行進實時的反饋和互動,而且還必須符合現實世界的基本邏輯規律。比如你用手向後推一個漂浮的氣球,氣球不能向天上飛,而要向後飛。你用手輕推一輛汽車,它不能馬上就高速跑起來。
所以如果用戶對於視頻模型中一些小的瑕疵還能接受的話,世界模型就一定需要對物理反饋處理的非常精準,雖然不一定能到LeCun要求的「理解物理世界」的水平,但是相比於視頻模型生成的一閃而過的畫面,生成的虛擬世界如果處理不好這些物理交互邏輯,那就是沒有意義的產品。
而我們看到谷歌提供的Demo中,隨着用戶輸入不同的指令,世界會實時給出不同的反饋,生成不同的內容。想要做到這一點,需要的處理的技術問題是非常有挑戰性的。

而如果在未來,谷歌真的能把這條路徹底跑通,且不說「世界模型」背後的技術對機器人和自動駕駛領域會不會產生什麼顛覆性的改變,就算對VR,遊戲以及文生視頻行賽道生的影響,也將是難以想象的。
可惜的是,雖然Genie 3看起來足夠驚豔,但依然停留在官方演示階段,所有的發布內容都為官方放出,沒有提供普通用戶試用,還是經典的谷歌版期貨。
但雖說是期貨,可現如今,這樣具有跨時代意義的產品和技術突破,似乎只有對AI進行飽和式火力覆蓋的谷歌,才能做到。
從技術層面來講,即便是像OpenAI這樣的創業公司,也只能能在Transformer這一類模型上和谷歌形成你追我趕之勢。雖然一年多以前,是OpenAI推出的Sora炸裂全場,拉爆了人們對於視頻生成模型的期待。但是真正有實力能持續投入,在時間維度上持續保持領先的產品,依然是谷歌和它的Veo。而Genie 3,也是谷歌多年默默耕耘,迭代了數個大版本的成果。
考慮到即便是Transformer,也是發源於谷歌,希望它能善待每一株火苗,早日讓我們感受到燎原的熱浪。
03
偏科冠軍的執着:2%提升

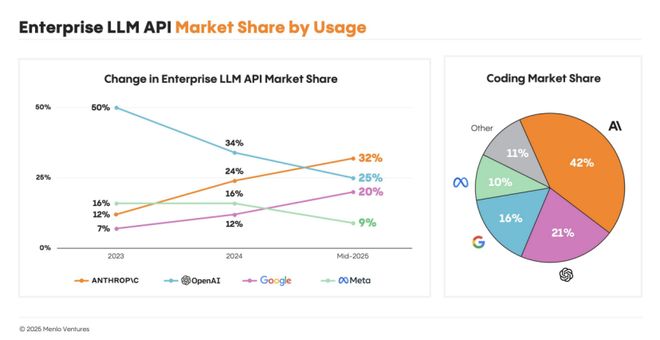
一張圖就能很好地概括Anthropic昨晚的發布,AI編程能力上限又提高了2%。
但需要強調的是,這裏的2%,不僅僅是Claude自己的提升,而是代表了現在AI編程能力的上限。

因為從用戶真實反饋和市場佔有率上來看,Claude Opus幾乎就是現在AI Coding的口碑和佔有率最高的模型。
而AI編碼,幾乎就是現階段大模型商業化最徹底,未來上限最高的一個分支賽道。所以面對OpenAI的血脈壓制,Anthropic選擇的是將所有資源和精力都花在提升自己模型的編程能力上。通過這個競爭策略,讓自己能夠持續留在大模型商業化的牌桌上,保留同谷歌和OpenAI持續對抗的可能。
所以從這個角度說,Opus 4.1的發布,似乎是在另外兩家發布補課和「戰未來」的產品時,向自己的所有客戶堅定地說,放心,你們選我錯不了。
04
AI聖誕夜背後的國人力量
昨夜硅谷AI圈的三彈連發,背後依然少不了華人科學家和工程師的身影。

OpenAI發布的gpt-oss系列模型的核心團隊成員之一,就有參與多個項目的北大校友任泓宇。

在OpenAI期間,他主要負責後訓練團隊,主要研究方向為語言模型訓練優化。
而他現在,也已經被小扎重金挖到了Meta,成為了Meta超(一)級(億)智(薪)能(酬)實驗室的成員。
在去OpenAI之前,他曾經在蘋果,微軟,谷歌,英偉達都工作或者實習過。2018年從北大本科畢業後,他在斯坦福大學獲得了計算機博士學位。

而在社交網絡上,他也專門感謝了另一位華人科學家Wang Xin在項目後訓練階段的貢獻。

她本科畢業於上海交大,後來在加州大學伯克利分校獲得了計算機博士學位。

之後在微軟,蘋果工作過,於今年2月份加入了OpenAI,主要負責模型的後訓練工作。
而在谷歌發布Genie 3團隊名單中,也有1名華人參與。

Emma Wang本科畢業於上海交通大學,在哈佛大學獲得博士學位。2019年博士畢業後加入谷歌,主要負責模型的優化。2023年,她加入了DeepMind團隊,之後參與了Genie 3服務系統的設計和優化了,降低了10倍的延遲,大大提升了模型的吞吐量,從讓模型而實現了24fps的流暢度和亞秒級響應延遲。
