
作者 | 陳駿達
編輯 | 李水青
智東西8月7日報道,昨天,小紅書hi lab(人文智能實驗室)開源了其首款多模態大模型dots.vlm1,這一模型基於DeepSeek V3打造,並配備了由小紅書自研的12億參數視覺編碼器NaViT,具備多模態理解與推理能力。
hi lab稱,在主要的視覺評測集上,dots.vlm1的整體表現已接近當前領先模型,如Gemini 2.5 Pro與Seed-VL1.5 thinking,尤其在MMMU、MathVision、OCR Reasoning等多個基準測試中顯示出較強的圖文理解與推理能力。
這一模型可以看懂複雜的圖文交錯圖表,理解表情包背後的含義,分析兩款產品的配料表差異,還能判斷博物館中文物、畫作的名稱和背景信息。

▲部分官方案例(圖源:小紅書技術)
在典型的文本推理任務(如AIME、GPQA、LiveCodeBench)上,dots.vlm1的表現大致相當於DeepSeek-R1-0528,在數學和代碼能力上已具備一定的通用性,但在GPQA等更多樣的推理任務上仍存在差距。
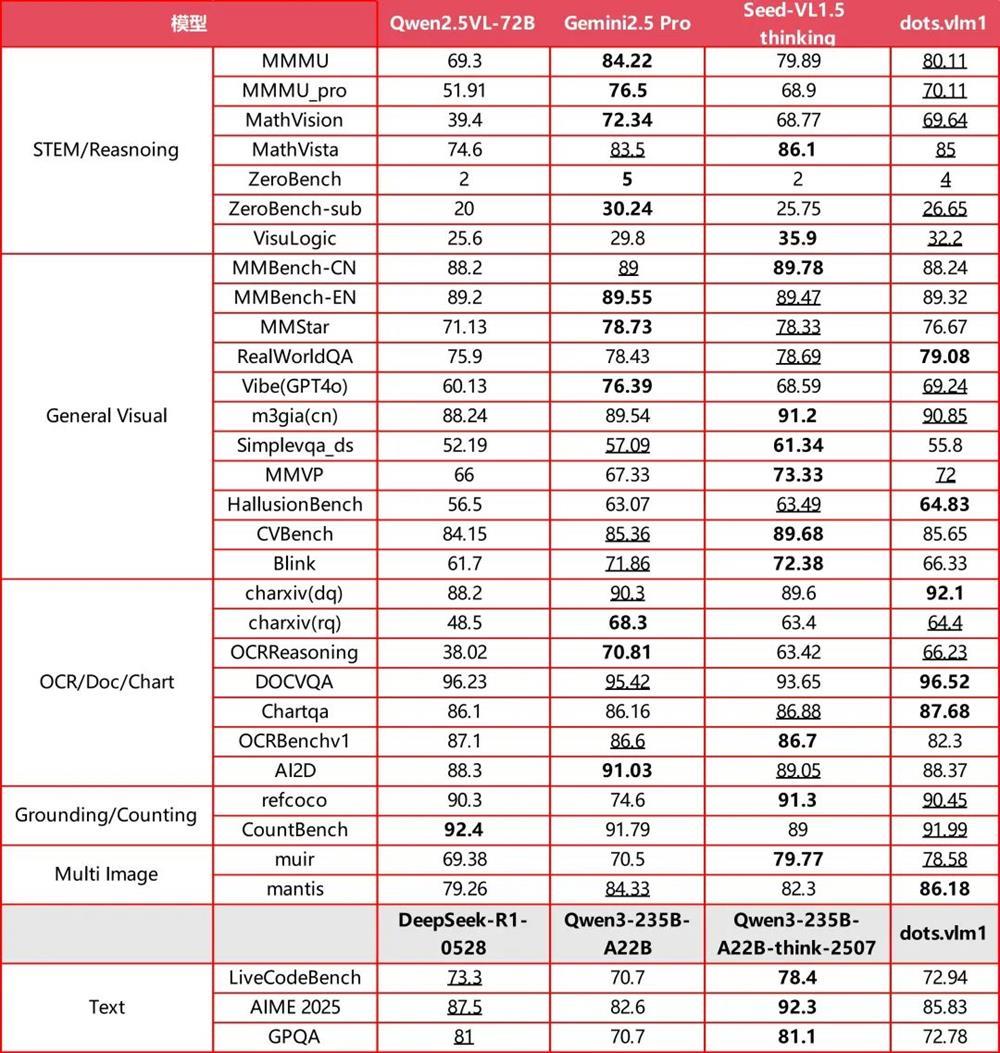
▲dots.vlm1基準測試結果(圖源:小紅書技術)
總體來看,dots.vlm1在視覺多模態能力方面已接近SOTA(最佳性能)水平,在文本推理方面達到了主流模型的性能。不過,hi lab也強調,dots.vlm1在部分細分任務上仍與最優結果存在一定距離,需要在架構設計與訓練數據上進一步優化。
目前,dots.vlm1已上傳至開源託管平台Hugging Face,用戶還可以在Hugging Face上的體驗鏈接中免費使用這一模型。
今年6月6日,小紅書開源了其首款大語言模型,並在之後開源了用於OCR的專用模型,以及視覺、獎勵模型等前沿方向的研究成果。這位大模型界新玩家的後續動作,值得持續關注。
一、解讀複雜英文圖表,還能玩視覺腦筋急轉彎
智東西體驗了dots.vlm1的多模態理解能力。我們將OpenAI昨日開源模型的體驗網頁截圖上傳給dots.vlm1,要求其解讀圖片的核心信息。
可以看到,dots.vlm1準確識別了圖中的大部分信息,還能通過閱讀右側的代碼,設想出這一代碼可視化後的效果。不過,或許是由於OCR環節的問題,它將其中一款模型的參數量識別錯了。
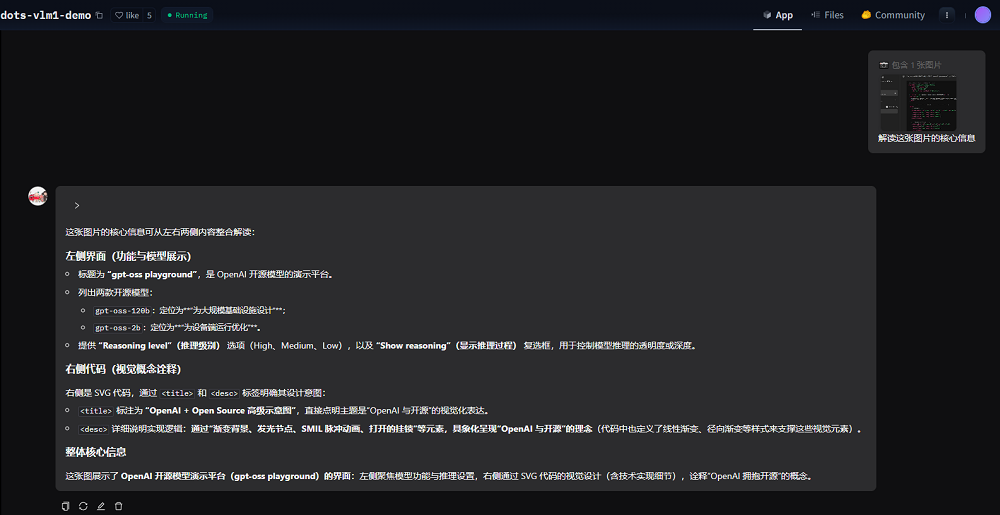
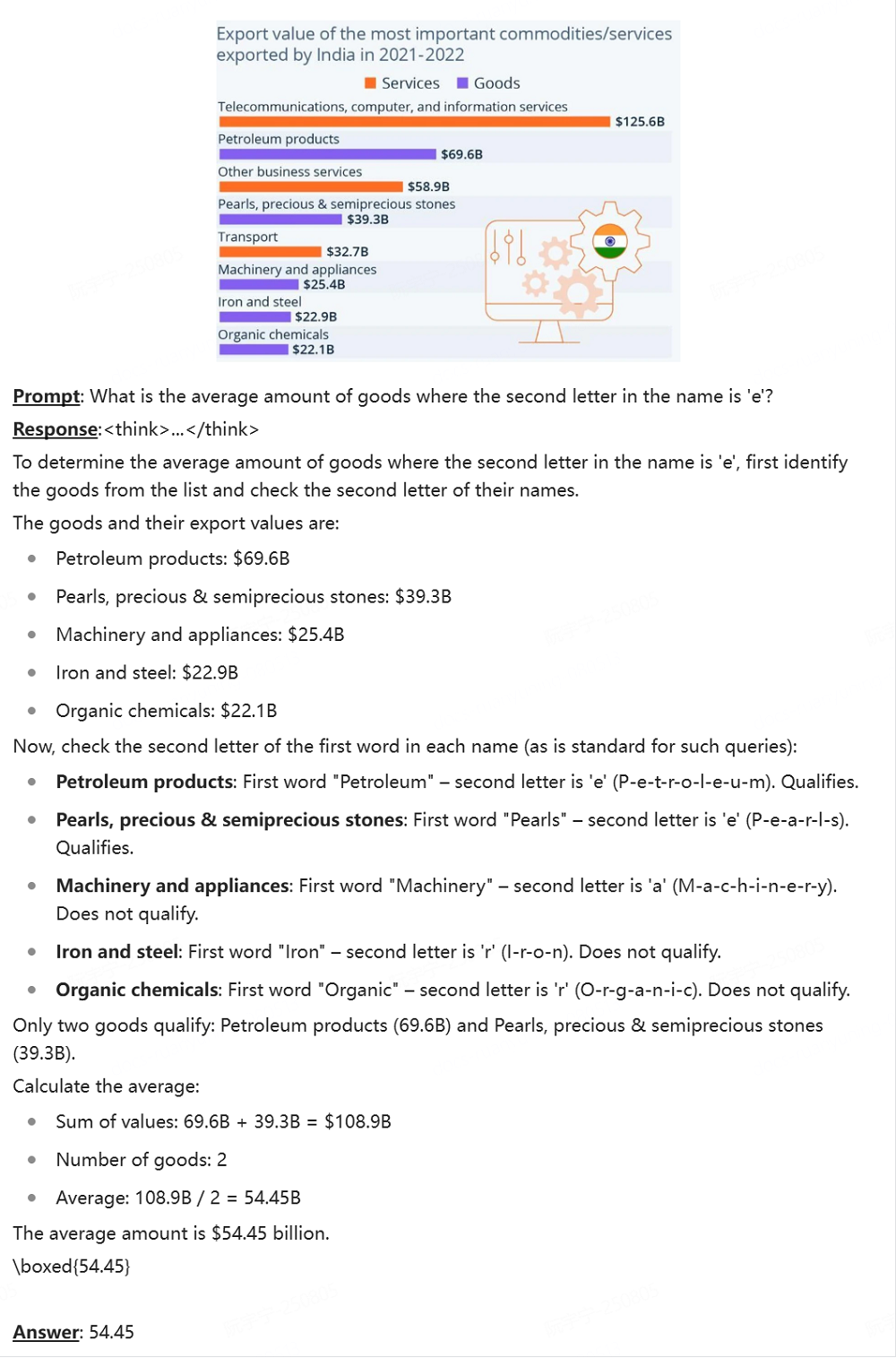
dots.vlm1具備一定的複雜圖表推理能力。官方Demo案例中,dots.vlm1讀懂了文本交錯的英文圖表,準確理解圖標元素之間的關係,並計算出了用戶所問的數據。
上傳一張景區價目表,再輔以文字提示詞描述團隊信息,dots.vlm1就能為用戶做好購票方案的規劃。

數學能力方面,dots.vlm1能看懂幾何題中的圖形,並理解顏色等信息,根據這些信息解題,並得出正確答案。

dots.vlm1還能對emoji等視覺信息進行推理。例如,它根據幾個emoji所代表的形象,猜測出了這一段信息代表的是《飢餓遊戲前傳:鳴鳥與蛇之歌》。

二、基於DeepSeek V3打造,12億視覺編碼器實現多模態感知
dots.vlm1由三個核心組件構成:一個12億參數的NaViT視覺編碼器、一個輕量級的MLP適配器,以及DeepSeek V3 MoE大語言模型。這一架構通過三階段流程進行訓練:
(1)視覺編碼器預訓練
NaViT編碼器由hi lab從頭訓練,旨在最大化對多樣視覺數據的感知能力。該編碼器包含42層Transformer,採用RMSNorm、SwiGLU和二維旋轉位置編碼(2D RoPE)等技術。
預訓練過程中,NaViT編碼器使用雙重監督策略,包括下一Token預測(NTP)和下一Patch生成(NPG)。前者通過大量圖文對訓練模型的感知能力,後者利用純圖像數據,通過擴散模型預測圖像patch,增強空間與語義感知能力。訓練過程中使用了大量圖文對。
在預訓練的第二階段,hi lab逐步逐步提升圖像分辨率,從百萬像素級別輸入開始,在大量token上進行訓練,之後升級到千萬像素級別進行訓練。為進一步提升泛化能力,還引入了更豐富的數據源,包括OCR場景圖像、grounding數據和視頻幀。
(2)VLM預訓練
在這一階段,hi lab將視覺編碼器與DeepSeek V3聯合訓練,使用大規模、多樣化的多模態數據集,主要包括跨模態互譯數據和跨模態融合數據。
跨模態互譯數據用於訓練模型將圖像內容用文本進行描述、總結或重構,包括普通圖像、複雜圖表、表格、公式、圖形、OCR場景、視頻幀以及對應的文本註釋等。
跨模態融合數據用於訓練模型在圖文混合上下文中執行下一token預測,避免模型過度依賴單一模態。
hi lab稱,該團隊為不同類型的融合數據設計了專門的清洗管線,以下兩類效果尤為顯著:
網頁數據:網頁圖文數據多樣性豐富,但視覺與文本對齊質量不佳。hi lab採用內部自研的VLM模型進行重寫和清洗,剔除低質量圖像和弱相關文本。
PDF數據:PDF內容質量普遍較高。為充分利用這類數據,hi lab開發了專用解析模型dots.ocr(這一模型也已開源),將PDF文檔轉化為圖文交錯表示。同時還將整頁PDF渲染為圖像,並隨機遮擋部分文本區域,引導模型結合版面與上下文預測被遮擋內容,從而增強其理解視覺格式文檔的能力。
(3)VLM後訓練
hi lab通過有監督微調(SFT)增強dots.vlm1模型的泛化能力,僅使用任務多樣的數據進行訓練,並未採用強化學習。
結語:感知推理能力仍有提升空間,下一步將探索強化學習
hi lab稱,該團隊在評估中發現,dots.vlm1在視覺感知與推理能力上仍存在不足。
在視覺感知方面,hi lab計劃擴大跨模態互譯數據的規模與多樣性,並進一步改進視覺編碼器結構,探索更有效的神經網絡架構與損失函數設計,從而提升訓練效率。
在視覺推理方面,hi lab將使用強化學習方法,以縮小文本與多模態提示在推理能力上的差距;同時也將探索把更多推理能力前置到預訓練階段的可能性,從而增強泛化性和效率。