
作者 | 陳駿達
編輯 | 李水青
國產SOTA(最佳表現)級開源圖像生成模型,來了!
智東西8月5日報道,今天,阿里開源了Qwen-Image,通義千問系列中首個圖像生成基礎模型。Qwen-Image主打複雜文本渲染能力,能在不同場景中,準確地生成不同語種、風格的文字,甚至可以寫毛筆字書法,或是直接生成帶有文本和圖像的PPT頁面。

下圖中,Qwen-Image不僅準確還原了提示詞中的「宮崎駿」風格要求,還隨着構圖的景深變化,將「雲存儲」、「雲計算」等字樣準確地渲染。文字與畫面的融合較為自然。

Qwen-Image同樣準確生成英文內容。它根據英文提示詞生成了一個書店的櫥窗場景,所有指定的文字都被準確還原,並且它還自動為每本書生成了不同的風格化字體以及封面,與書名契合。

除了文本處理,Qwen-Image在通用圖像生成方面支持了多種藝術風格。從照片級寫實場景到印象派繪畫,從動漫風格到極簡設計都掌握了。

Qwen-Image是一個20B的模型,使用了MMDiT(多模態擴散Transformer)架構,其中「MM」代表的是模型生成圖像、文本等多模態內容的能力,「DiT」則代表了這是一個擴散Transformer。
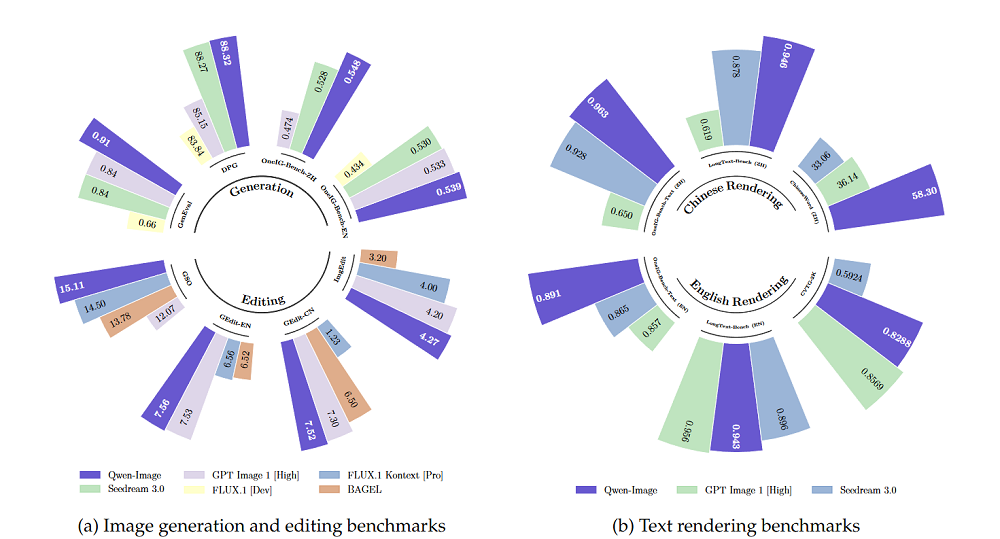
千問團隊在多個公開基準上對Qwen-Image進行了評估,比較對象為全球頭部的開源、閉源圖像生成模型,共獲得12項SOTA(最佳表現)。在通用圖像生成測試GenEval、DPG和OneIG-Bench,以及圖像編輯測試GEdit、ImgEdit和GSO上,Qwen-lmage超過了Flux.1、BAGEL等開源模型、字節跳動的SeedDream 3.0和OpenAI的GPT Image 1(High)。
在用於文本渲染的LongText-Bench、ChineseWord和TextCraft基準測試上的結果表明,Qwen-Image在文本渲染方面表現尤為出色,特別是在中文文本渲染上,大幅領先現有的最先進模型,包括SeedDream 3.0和GPT Image 1(High)。
目前,Qwen-Image已在魔搭、Hugging Face等社區開源,普通用戶可在QwenChat(chat.qwen.ai)中選擇圖像生成功能,直接體驗這款模型。
Qwen-Image的技術報告也同步開源,報告內容逐一揭祕了這款模型的具體技術實現。

一、架構包含三大核心組件,多模型協作實現圖像生成
千問團隊觀察到,市面上已有的圖像生成模型雖然在分辨率、細節刻畫上實現一定突破,但在多行文本渲染、非字母語言(如中文)生成、局部文本插入或文本與視覺元素融合等任務時,仍然表現不佳。
智東西也將關注度頗高的Flux生圖模型與Qwen-Image進行對比,在提示詞完全一致的前提下,左側的Flux直接拒絕生成「2025年夏季上映」的中文字樣,其畫面衝擊力也略遜於Qwen-Image。

▲智東西實測電影海報生成,提示詞:科幻電影海報標題‘GALAXY INVASION’,金屬質感字體帶有霓虹光效和破損邊緣,背景是太空爆炸,小字標註‘2025年夏季上映’。
其次,在圖像編輯方面,編輯結果與原始圖像之間的對齊仍面臨挑戰。首先要保持視覺一致性,例如僅改變髮色而不影響面部特徵;還需擁有語義連貫性,例如修改人物姿態的同時保持身份和場景的一致。

▲智東西實測圖像編輯,提示詞為加入宇宙飛船元素,改為2026年夏季上映(左側為Flux,右側為Qwen-Image)
中文書法場景下,智東西讓Qwen-Image自主選擇了書寫的內容和字體,最終的結果如下。

Qwen-Image的架構由三個核心組件構成,三者協同工作,實現文本到圖像生成。
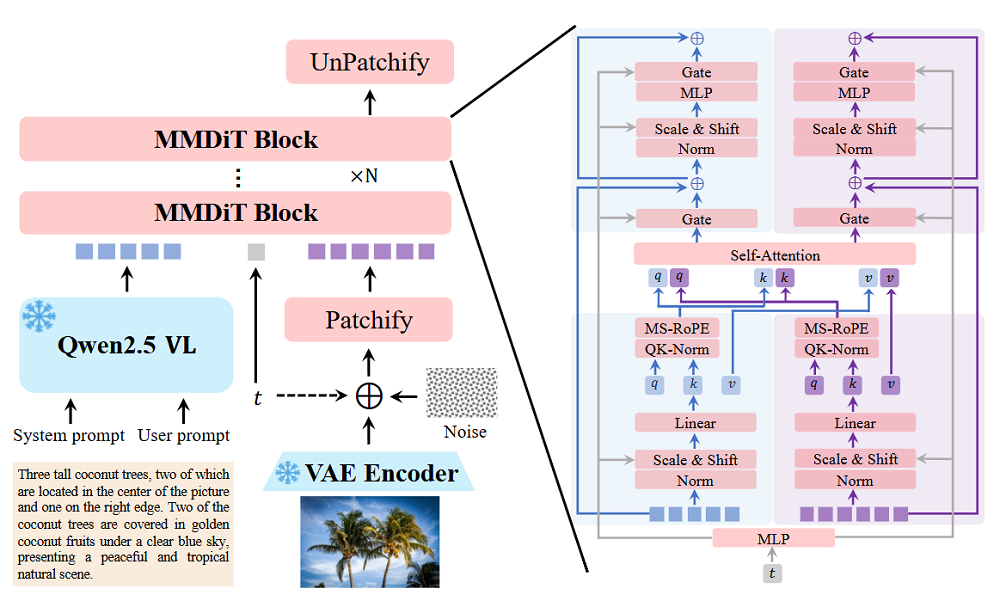
Qwen2.5-VL多模態大語言模型(MLLM)作為條件編碼器,負責從文本輸入中提取特徵。
系統提示詞要求Qwen2.5-VL詳細描述物體和背景的顏色、數量、文字、形狀、大小、紋理以及空間關係,來為圖像生成提供依據,引導模型生成精細化的潛在表示。
Wan-2.1視頻生成模型的分自編碼器(VAE)被用於充當Qwen-Image的圖像分詞器(tokenizer)。
它能將輸入圖像壓縮為緊湊的潛在表示,並在推理階段將其解碼還原。值得注意的是,Qwen團隊凍結了Wan-2.1的編碼器,僅對圖像解碼器進行微調,但仍然顯著增強了模型的細節表現力。
多模態擴散Transformer(MMDiT)作為主幹擴散模型,在文本引導下建模噪聲與圖像潛在表示之間的複雜聯合分佈。
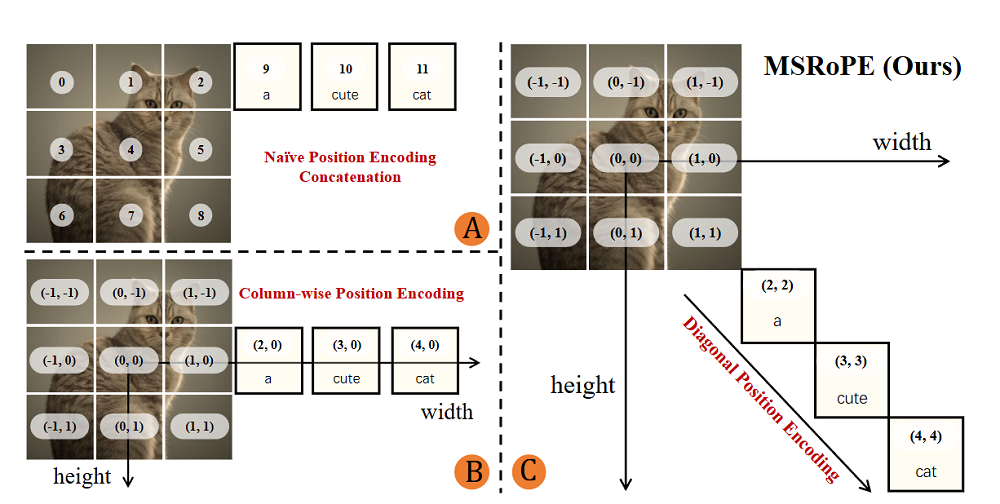
在每個MMDiT中,千問團隊引入一種多模態可擴展RoPE方法,能幫助模型在區分圖像與文本token的前提下,保持較強的高分辨率圖像生成能力,準確生成文字內容。
二、打造數十億規模數據集,模型「漸進學習」生圖能力
架構設計完成後,Qwen-Image通過數據工程、漸進式學習策略、增強的多任務訓練範式以及可擴展的基礎設施優化,來解決圖像生成模型的常見問題。
為實現複雜提示對齊,千問團隊構建了一套數據處理流程,涵蓋大規模數據採集、標註、過濾、合成增強與類別平衡。
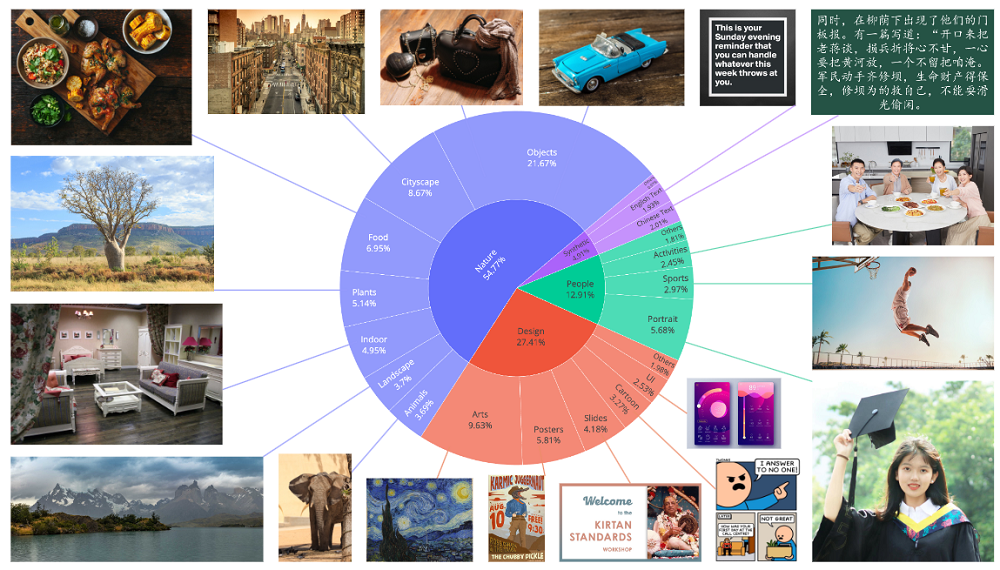
數據收集與分類階段,該團隊系統性地收集並標註了數十億規模的圖文對數據,該數據集分為四大核心領域:
(1)自然(55%):涵蓋物體、風景、城市、植物、動物、室內、食物等廣泛類別,是模型生成多樣化真實圖像的基礎。
(2)設計(27%):包含海報、用戶界面、PPT、繪畫、雕塑、數字藝術等,富含文本、複雜佈局和藝術風格,對提升模型理解藝術指令、文本排版和設計語義至關重要。
(3)人物(13%):包括肖像、運動、人物活動等,用於提升模型生成真實、多樣人像的能力。
(4)合成數據(5%):特指通過可控文本渲染技術生成的數據,而非其他AI模型生成的圖像。此舉避免了AI生成圖像帶來的僞影、文本扭曲和偏見風險,確保數據可靠性。
拿到原始數據集後,千問團隊進行了七階段漸進式數據過濾,包含初始預訓練數據整理、圖像質量增強、圖文對齊優化、文本渲染增強、高分辨率精煉、類別平衡與肖像增強、平衡的多尺度訓練。
進入預訓練階段,Qwen-Image採用課程學習(curriculum learning)策略,從基礎的文本渲染任務起步,逐步過渡到段落級和佈局敏感型描述的生成。這一方法顯著提升了模型對多樣化語言的理解與生成能力,尤其在中文等表意文字語言上表現突出。
這種漸進式的學習方式體現在多個方面。
分辨率上,Qwen-Image從256p開始,逐步提升至640p和1328p,使模型由淺入深地學習從整體到細節的視覺特徵。
數據質量也漸進提升,初期使用大規模數據快速建立基礎能力,後期引入更嚴格的數據過濾,使用高質量、高分辨率數據進行精煉。
文本渲染能力逐步增強,先訓練無文本的通用圖像生成,再逐步加入含文本(尤其是中文)的圖像,專門強化文本渲染能力。
數據分佈上,不同領域(自然、設計、人物)和不同分辨率的數據比例會根據訓練情況調整,防止過擬合。
在圖像編輯方面,Qwen-Image支持風格遷移、增刪改、細節增強、文字編輯,人物姿態調整等多種操作。
三、多任務框架統一生成、編輯,20萬+次對決後躋身競技場前三
圖像生成模型的訓練對基礎設施提出了更高的要求,為應對模型巨大的參數量和數據量,千問團隊設計了高效的分佈式訓練框架。
這一框架中包含生產者與消費者(Producer-Consumer)。
生產者負責所有數據預處理,包括數據過濾、MLLM特徵提取和VAE編碼。處理後的數據按分辨率存入高速緩存。
消費者部署在GPU集羣上,專注於模型訓練。通過專用的HTTP傳輸層,消費者能異步、零拷貝地從生產者拉取預處理好的批次。
這一框架解耦了吞吐密集型的預處理和計算密集型的訓練,極大提升了GPU利用率和整體吞吐量,且支持數據管道的在線更新。
千問團隊還採取了混合併行策略,結合數據並行與張量並行,在多頭注意力模塊中採用「頭並行」(head-wise parallelism)以減少通信開銷。
預訓練後,該團隊通過監督微調(SFT)和強化學習(RL)進一步提升Qwen-Image的生成質量,並對齊人類偏好。
監督微調階段構建了一個分層組織的高質量數據集,所有樣本均經過人工精標,強調圖像清晰度、細節豐富性、亮度表現和照片級真實感,用以引導模型輸出更高品質的視覺內容。
隨後引入強化學習進一步優化生成偏好,主要採用直接偏好優化方法:對同一提示生成多個候選圖像,由人工標註出最優與最差樣本,DPO損失函數基於流匹配框架,通過比較模型對「好」與「壞」樣本在速度預測上的差異來更新參數。
在此基礎上,Qwen-Image進一步應用組相對策略優化(GRPO)進行細粒度調優,在每組生成結果中依據獎勵模型打分計算優勢函數,並據此調整策略;為增強探索能力,GRPO在採樣時採用隨機微分方程(SDE)替代傳統的ODE。
Qwen-Image還通過一個統一的多任務框架,支持文本到圖像(T2I)和圖文到圖像(TI2I,即圖像編輯)等多種生成模式。對於圖像編輯任務,用戶提供的參考圖像會經由Qwen2.5-VL處理,畫面由視覺Transformer(ViT)編碼,並與文本標記(text tokens)拼接,形成輸入序列。
這一過程中,Qwen2.5-VL會描述輸入圖像的關鍵特徵(顏色、形狀、大小、紋理、物體、背景),然後解釋用戶的文本指令應如何改變或修改該圖像。Qwen-Image會生成一張符合用戶要求的新圖像,同時在適當的情況下保持與原始輸入圖像的一致性。
為了使模型能夠區分多張圖像,千問團隊在原有用於定位單張圖像內圖像塊的高度和寬度基礎上,進一步擴展了MSRoPE,引入了一個額外的「幀(Frame)」維度,進一步增強了模型保持視覺保真度以及與用戶所提供圖像在結構上保持一致的能力。
千問團隊用大量定量與定性實驗,驗證了Qwen-Image在生成和編輯兩方面的能力。
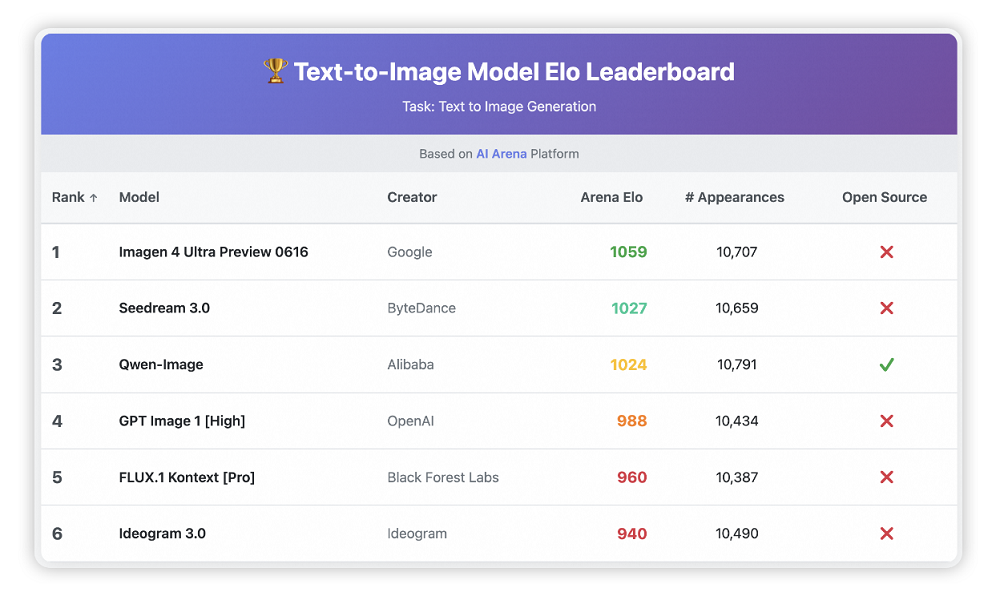
在5000條提示、20萬+次匿名對決的AI Arena中,Qwen-Image作為唯一開源模型躋身前三,領先GPT Image 1、FLUX.1 Pro等30分以上。
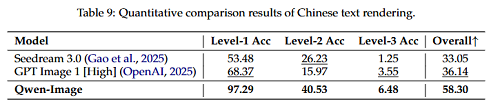
在其主打的中文文字生成場景,Qwen-Image單字渲染準確率達到58.3%。
圖像編輯任務上,Qwen-Image在GEdit、ImgEdit等排行榜獲得第一,深度估計與零樣本新視角合成也能與閉源模型持平或更好。
技術報告中還展現了這一模型與其他模型的生成效果對比。可以看到,在書店櫥窗的案例中,Qwen-Image在書籍封面與文字的搭配上做得不錯。

複雜英文文本渲染上,左側兩款模型已經出現不同程度的亂碼,右側的GPT Image 1(High)和Qwen Image沒有出現類似問題。

在圖像編輯類任務上,其他三款模型都未能準確展現出提示詞中要求的冰箱貼質感,而Qwen-Image的結果無論從顏色還是形狀來看,都較為符合提示詞要求。

結語:阿里持續開源圖像模型,可用性進一步提升
今年6月,阿里已經開源了Wan 2.1圖像生成模型,提供最大14B的版本。本次的Qwen-Image將參數量進一步提升至20B,模型可用性進一步提升。
Qwen-Image憑藉對文本生成、圖像編輯等功能的針對性提升,已經具備了海報製作、PPT生成、精準圖像編輯等能力,這些能力對圖像生成技術走入真實生產場景有較大意義。