
作者 | 王涵
編輯 | 漠影
智東西8月7日報道,今天上午,通義千問Qwen宣佈推出兩款更小尺寸的新模型:Qwen3-4B-Instruct-2507和Qwen3-4B-Thinking-2507。
其中,Qwen3-4B-Thinking-2507的推理能力可媲美中尺寸模型;Qwen3-4B-Instruct-2507在知識、推理、編程、對齊以及agent能力上全面超越了閉源的小尺寸模型GPT-4.1-nano。
此次發布的「2507」版本的Qwen3-4B模型對手機等端側硬件部署較為友好,目前已在魔搭社區和Hugging Face正式開源。
▲已在Hugging Face開源(來源:Hugging Face)
一、性能比肩中尺寸模型,agent能力超越GPT-4.1-nano
Qwen3-4B-Instruct-2507與Qwen3-4B-Thinking-2507的上下文理解能力都擴展到了256K,可處理長文本,能支持更復雜的文檔分析、長篇內容生成以及跨段落推理等場景。
性能方面,Qwen3-4B-Thinking-2507在複雜問題推理能力、數學能力、代碼能力以及多輪函數調用能力上的表現大幅領先Qwen3同尺寸小模型。在Arena-Hard v2基準測試上,Qwen3-4B-Instruct-2507取得43.4分的成績,更勝一籌。
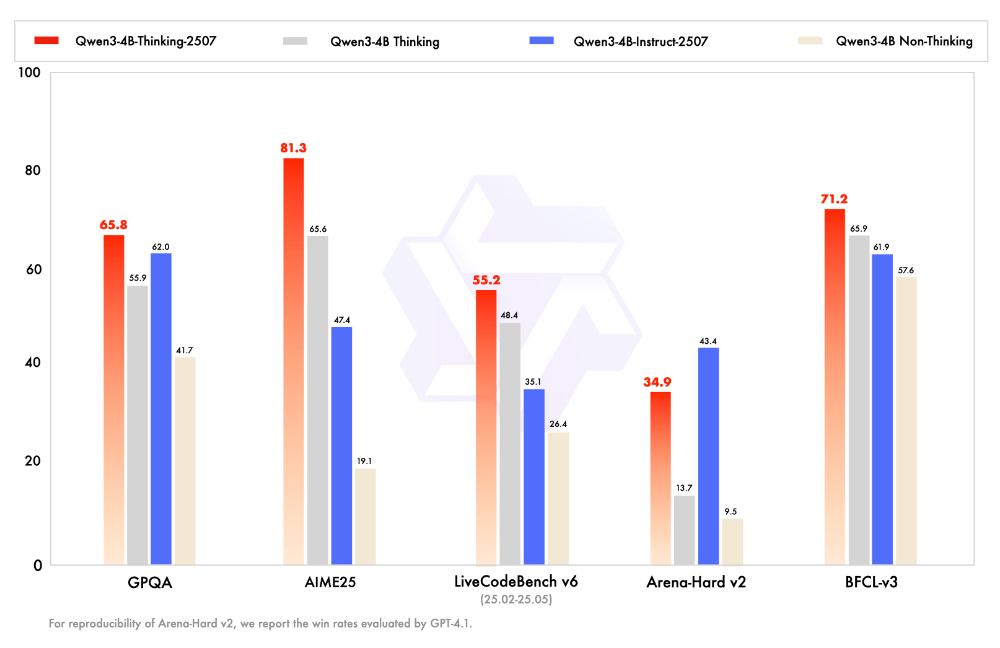
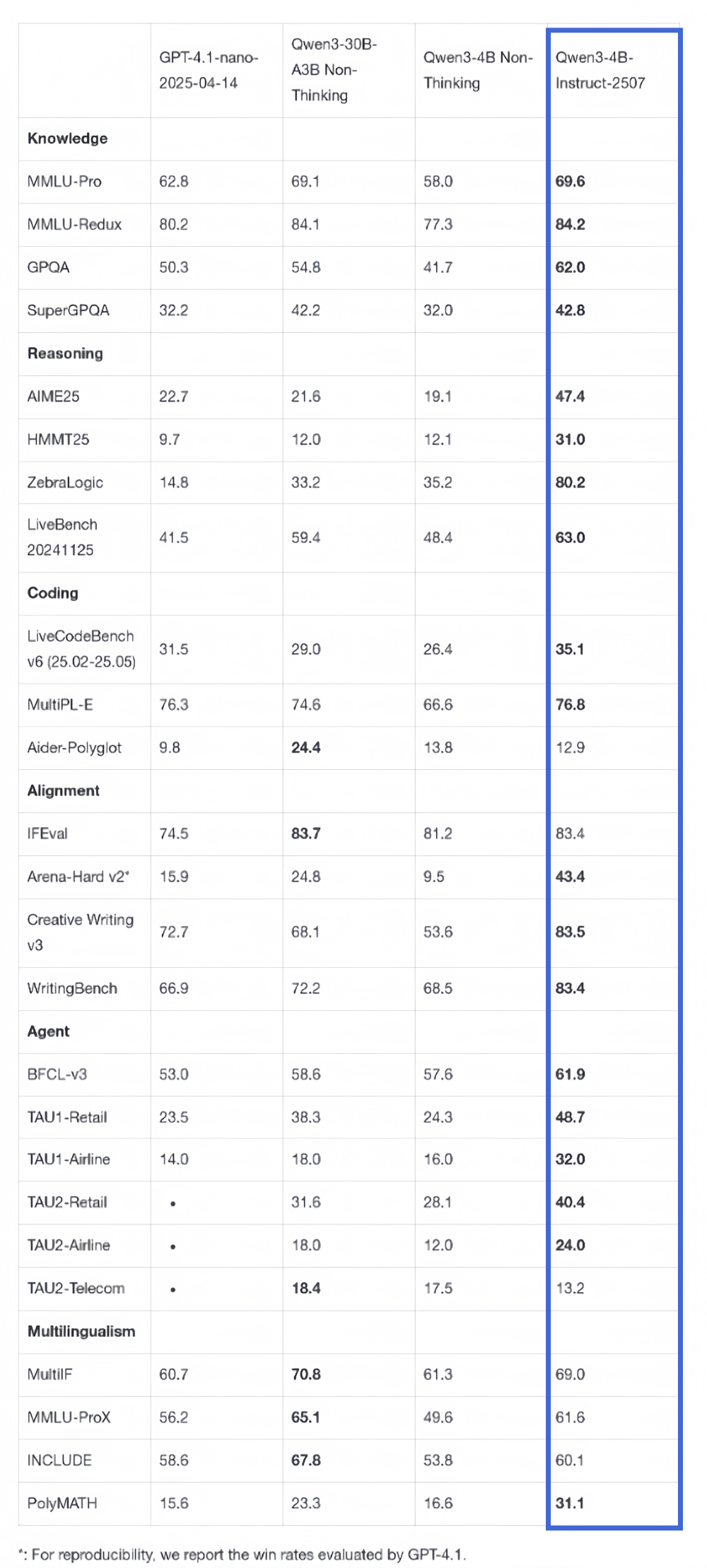
在非推理領域,Qwen3-4B-Instruct-2507在知識、推理、編程、對齊以及agengt能力上全面超越了閉源的小尺寸模型GPT-4.1-nano,且與中等規模的Qwen3-30B-A3B(non-thinking)性能接近。
該模型覆蓋了更多語言的長尾知識,在主觀和開放性任務中與人類偏好的對齊性增強,能夠提供更符合需求的答覆。
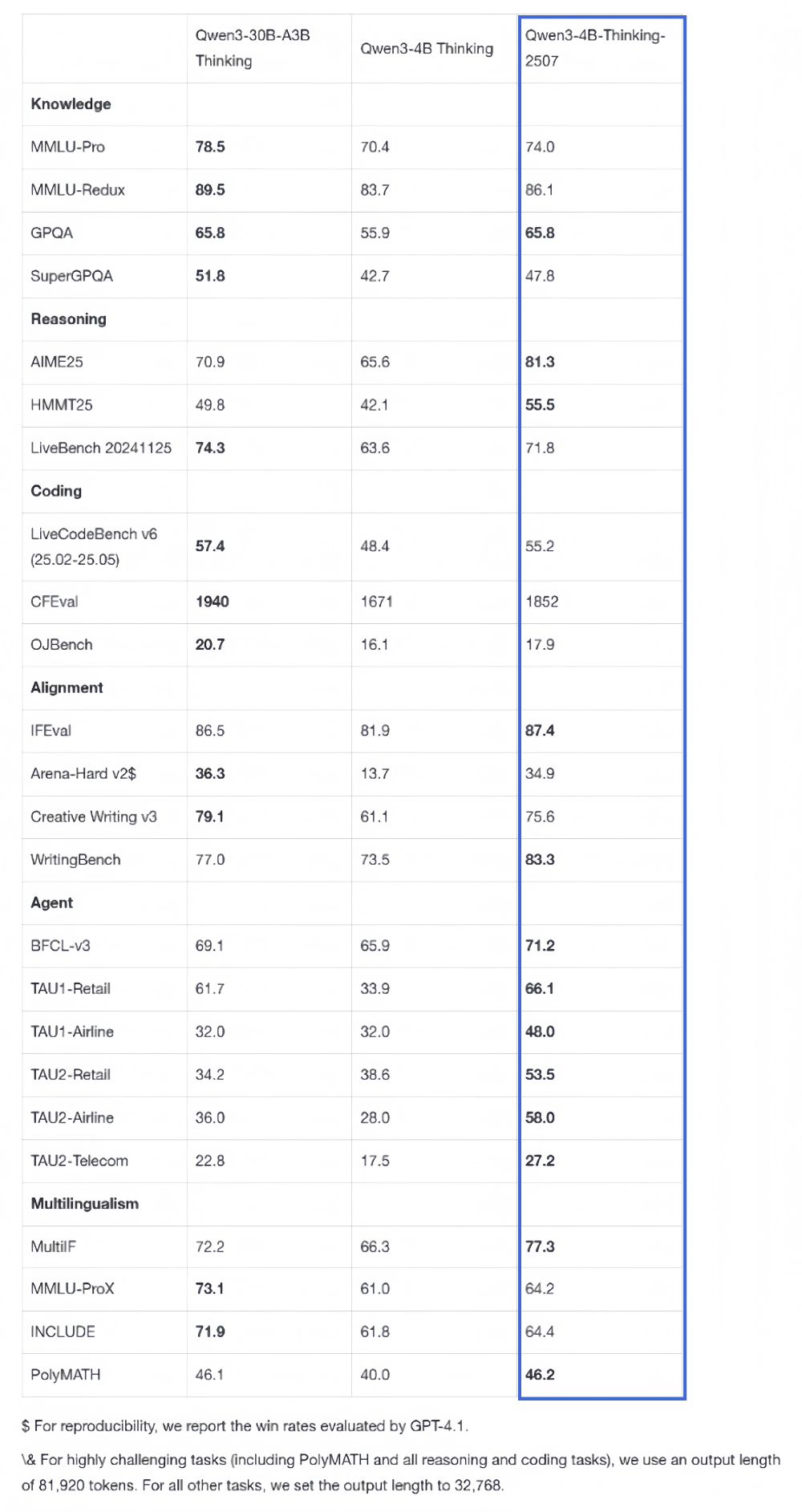
在推理領域,Qwen3-4B-Thinking-2507表現突出,推理能力可媲美中等模型Qwen3-30B-Thinking。特別是在聚焦數學能力的AIME25測評中,以4B參數量取得了81.3分的成績。
其通用能力也顯著提升,Agent分數超越了更大尺寸的Qwen3-30B-Thinking模型。
結語:小尺寸模型加速AI端側落地
通義千問此次推出的Qwen3-4B系列新模型,以更小的尺寸實現了性能上的優化,在通用能力上展現出超越同級別模型甚至逼近中大規模模型的實力,並且,小尺寸模型展現出了對端側硬件的更高的友好度。
無論是騰訊、阿里還是OpenAI等AI老玩家,都開始推出小尺寸模型,並且在agent能力上下功夫。這在一定程度上反映出目前主流市場認為小型語言模型(SLM)對Agentic AI的發展具有重要價值。
這類高性能小模型的開源與普及,將有望加速AI技術在端側設備的滲透,進而推動更多輕量化、場景化的智能應用落地。