
編譯 | 陳駿達
編輯 | 雲鵬
智東西8月11日報道,近日,智譜發布了其最新一代旗艦模型GLM-4.5的完整技術報告。GLM-4.5融合了推理、編程和智能體能力,並在上述場景的12項基準測試中,綜合性能取得了發布之際的全球開源模型SOTA(即排名第一)、國產模型第一、全球模型第三的成績,發布後不到48小時,便登頂開源平台Hugging Face趨勢榜第一。
智東西此前已對GLM-4.5的能力進行了介紹與測試,在技術報告中,智譜進一步分享了這款模型在預訓練、中期訓練和後訓練階段進行的創新。
GLM-4.5借鑑了部分DeepSeek-V3架構,但縮小了模型的寬度,增加了模型深度,從而提升模型的推理能力。在傳統的預訓練和後訓練之外,智譜引入了中期訓練,並在這一階段提升了模型在理解代碼倉庫、推理、長上下文與智能體3個場景的性能。
後訓練階段,GLM-4.5進行了有監督微調與強化學習,其強化學習針對推理、智能體和通用場景分別進行了訓練,還使用了智譜自研並開源的基礎設施框架Slime,進一步提升了強化學習的效率。
在多項基準測試中,GLM-4.5與DeepSeek-R1-0528、Kimi K2、OpenAI o3、Claude 4 Sonnet等頭部開閉源模型處於同一梯隊,並在部分測試中取得了SOTA。

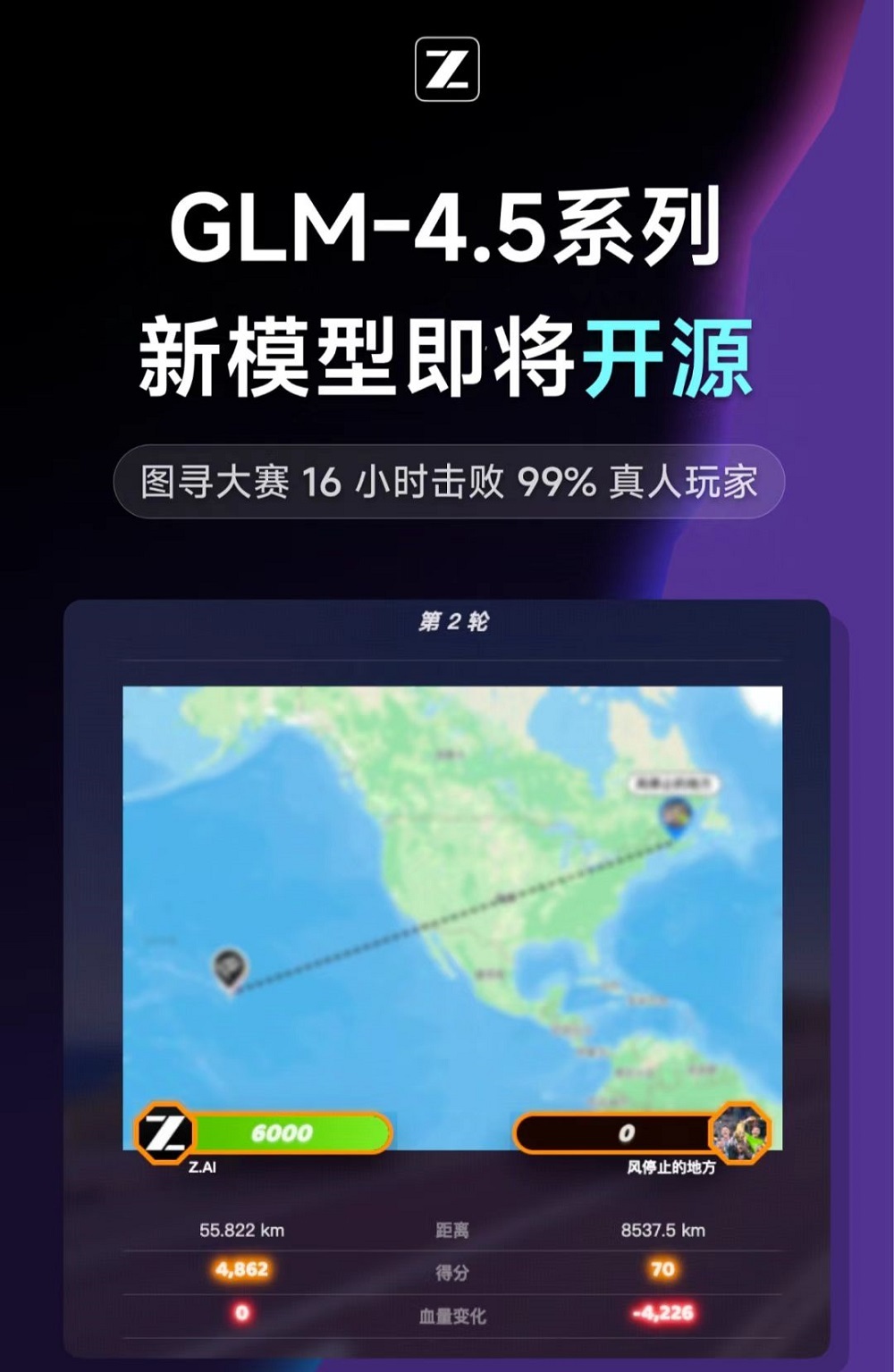
值得一提的是,智譜還計劃在今晚開源GLM-4.5系列的新模型,名為GLM-4.5V,或為一款視覺模型。
論文鏈接:
https://github.com/zai-org/GLM-4.5/blob/main/resources/GLM_4_5_technical_report.pdf
以下是對GLM-4.5技術報告核心內容的梳理:
一、從知識庫到求解器,「ARC」成新一代模型重要能力
GLM-4.5團隊提出,大模型正逐漸從「通用知識庫」的角色,迅速向「通用問題求解器」演進,目標是實現通用人工智能(AGI)。這意味着,它們不僅要在單一任務中做到最好,還要像人類一樣具備複雜問題求解、泛化能力和自我提升能力等。
智譜提出了三項關鍵且相互關聯的能力:Agentic能力(與外部工具及現實世界交互的能力)、複雜推理能力(解決數學、科學等領域多步驟問題的能力)、以及高級編程能力(應對真實世界軟件工程任務的能力),並將其統稱為ARC。
要具備上述能力,數據是基礎。GLM-4.5的預訓練數據主要包含網頁、多語言數據、代碼、數學與科學等領域,並使用多種方法評估了數據質量,並對高質量的數據進行上採樣(Up-Sampling),即增加這部分數據在訓練集中的出現頻率。
例如,代碼數據收集自GitHub和其他代碼託管平台,先進行基於規則的初步過濾,再使用針對不同編程語言的質量模型,將數據分為高/中/低質量,上採樣高質量、剔除低質量,源代碼數據使用Fill-In-the-Middle目標訓練,能讓模型獲得更好地代碼補全能力。對於代碼相關的網頁,GLM-4.5採用通過雙階段檢索與質量評估篩選,並用細粒度解析器保留格式與內容。
模型架構方面,GLM-4.5系列參考DeepSeek-V3,採用了MoE(混合專家)架構,從而提升了訓練和推理的計算效率。對於MoE層,GLM-4.5引入了無損平衡路由(loss-free balance routing)和sigmoid門控機制。同時,GLM-4.5系列還擁有更小的模型寬度(隱藏維度和路由專家數量),更大的模型深度,這種調整能提升模型的推理能力。
在自注意力模塊中,GLM-4.5系列採用了分組查詢注意力(Grouped-Query Attention)並結合部分RoPE(旋轉位置編碼)。智譜將注意力頭的數量提升到原來的2.5倍(96個注意力頭)。有趣的是,雖然增加注意力頭數量並未帶來比少頭模型更低的訓練損失,但模型在MMLU和BBH等推理類基準測試上的表現得到提升。
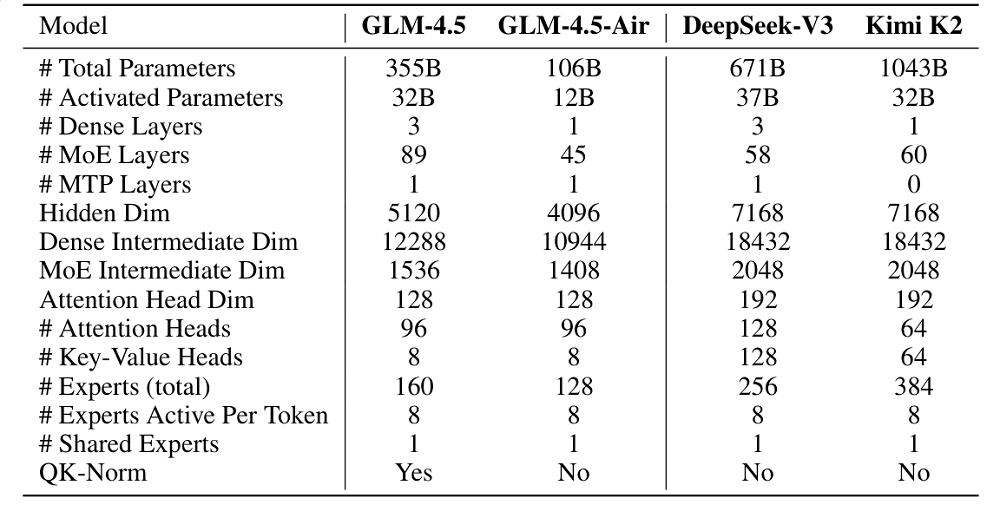
▲GLM-4.5系列模型與DeepSeek-V3、Kimi K2在架構方面的區別(圖源:GLM-4.5技術報告)
GLM-4.5還使用了QK-Norm技術,用於穩定注意力logits的取值範圍,可以防止注意力過度集中或過於分散,改善模型在長序列或複雜任務上的表現。同時,GLM-4.5系列均在 MTP(多Token預測)層中加入了一個MoE層,以支持推理階段的推測式解碼,提升推理速度和質量。
預訓練完成後,GLM-4.5還經歷了一個「中期訓練」階段,採用中等規模的領域特定數據集,主要在3個場景提升模型性能:
(1)倉庫級代碼訓練:通過拼接同一倉庫的多個代碼文件及相關開發記錄,幫助模型理解跨文件依賴和軟件工程實際場景,提升代碼理解與生成能力,同時通過加長序列支持大型項目。
(2)合成推理數據訓練:利用數學、科學和編程競賽題目及答案,結合推理模型合成推理過程數據,增強模型的複雜邏輯推理和問題解決能力。
(3)長上下文與智能體訓練:通過擴展序列長度和上採樣長文檔,加強模型對超長文本的理解與生成能力,並加入智能體軌跡數據,提升模型在交互和多步決策任務中的表現。
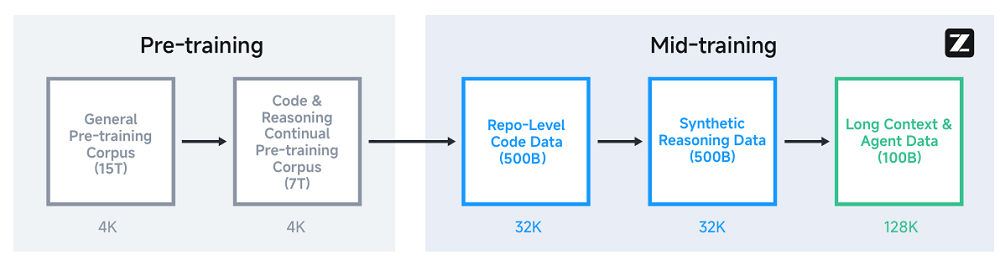
▲GLM-4.5的預訓練與中期訓練階段(圖源:GLM-4.5技術報告)
二、兩步走完成後訓練,自研開源基礎設施框架立功
GLM-4.5團隊將模型後訓練劃分為兩個階段,在階段一(專家訓練)中,該團隊打造了專注於推理、智能體和通用對話這3個領域的專家模型。在階段二(統一訓練)中,該團隊採用自我蒸餾技術將多個專家模型整合,最終產出一個融合推理與非推理兩種模式的綜合模型。
在上述兩個階段中,GLM-4.5都經歷了有監督微調(SFT)。
專家訓練中,SFT使用帶有思維鏈的小規模數據集,對專家模型進行基礎能力的預訓練,確保模型在進入強化學習前具備必要的推理和工具使用能力。
整體SFT中,GLM-4.5利用數百萬涵蓋多領域任務(推理、通用對話、智能體任務及長上下文理解)的樣本,基於128K上下文長度的基礎模型進行訓練。通過從多個專家模型輸出中蒸餾知識,模型學會在不同任務中靈活應用推理,同時兼顧部分不需複雜推理的場景,支持反思和即時響應兩種工作模式,形成混合推理能力。
在SFT過程中,GLM-4.5團隊採用了幾種方式,以提升訓練效果:
(1)減少函數調用模板中的字符轉義:針對函數調用參數中代碼大量轉義帶來的學習負擔,提出用XML風格特殊標記包裹鍵值的新模板,大幅降低轉義需求,同時保持函數調用性能不變。
(2)拒絕採樣(Rejection Sampling):設計了多階段過濾流程,去除重複、無效或格式不符的樣本,驗證客觀答案正確性,利用獎勵模型篩選主觀回答,並確保工具調用場景符合規範且軌跡完整。
(3)提示選擇與回覆長度調整:通過剔除較短的提示樣本,提升數學和科學任務表現2%-4%;對難度較高的提示詞進行回覆長度的調整,並生成多條回覆,進一步帶來1%-2%的性能提升。
(4)自動構建智能體SFT數據:包括收集智能體框架和工具、自動合成單步及多步工具調用任務、生成工具調用軌跡並轉換為多輪對話,以及通過多評判代理篩選保留高質量任務軌跡,確保訓練數據的多樣性與實用性。
SFT之後,GLM-4.5又進行了強化學習訓練。推理強化學習(Reasoning RL)重點針對數學、代碼和科學等可驗證領域,採用了難度分級的課程學習。因為早期訓練時,模型能力較弱,過難數據則會導致獎勵全為0,無法有效從數據中學習。分級學習後,模型學習效率得到了提升。
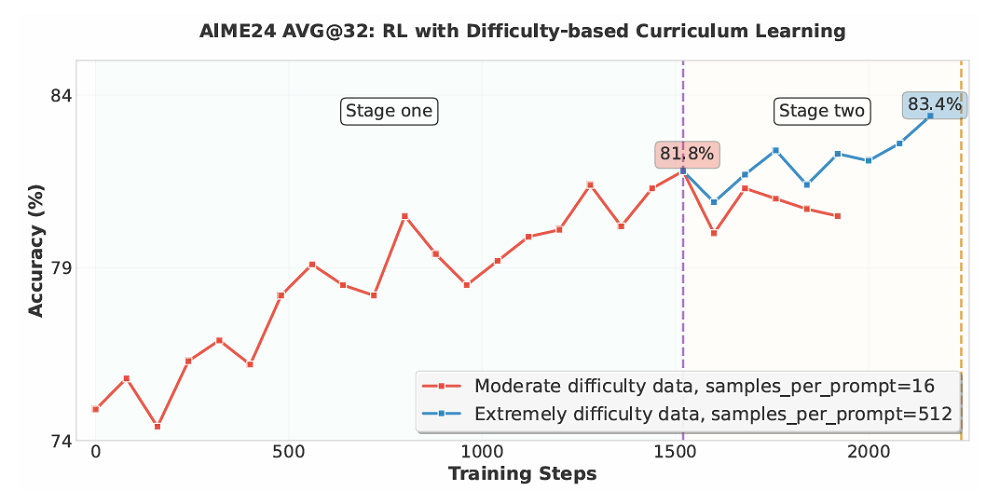
GLM-4.5模型還直接在最大輸出長度(64K)上進行單階段RL,這樣能維持在SFT階段獲得的長上下文能力。智譜還發現,在編程強化學習中,損失計算方式對訓練效率影響顯著。採用基於token加權的平均損失比傳統的序列均值損失效果更好,可提供更細粒度穩定的梯度信號,加快收斂速度,並有效緩解長度偏差和避免訓練中生成過於簡單重複樣本。
在科學領域的強化學習中,數據質量和類型尤為關鍵。GPQA-Diamond基準測試顯示,僅用專家驗證的多選題進行強化學習,效果明顯優於使用混合質量或未經驗證的數據,凸顯嚴格過濾高質量數據的重要性。
智能體強化學習(Agentic RL)則聚焦網頁搜索和代碼生成智能體,利用可自動驗證的獎勵信號實現強化學習的Scaling。為進一步提升強化訓練的效率,GLM-4.5團隊還採用了迭代自蒸餾提升技術,也就是在強化學習訓練一定步驟或達到平台期後,用強化學習模型生成的響應替換原始冷啓動數據,形成更優的SFT模型,再對其繼續強化學習。
該團隊還觀察到,在智能體任務中,隨着與環境交互輪數的增加,模型性能顯著提升。與常見的使用更多token進行推理,實現性能提升不同,智能體任務利用測試時計算資源持續與環境交互,實現性能提升。例如反覆搜索難以獲取的網頁信息,或為編碼任務編寫測試用例以進行自我驗證和自我修正。智能體任務的準確率隨着測試時計算資源的增加而平滑提升。
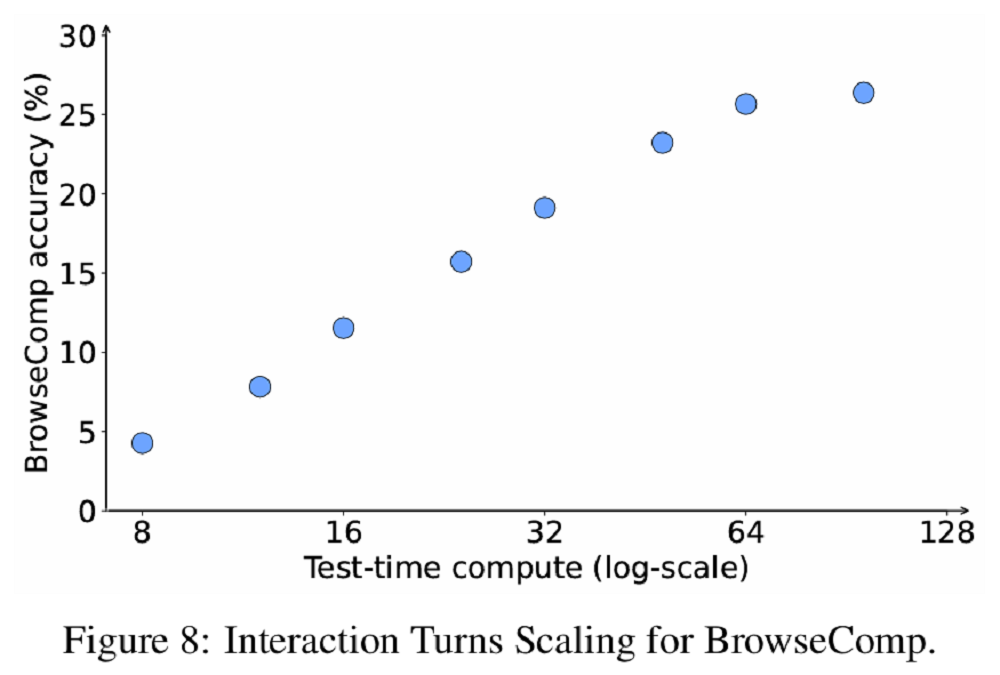
▲GLM-4.5在網頁搜索智能體評測集BrowseComp上的性能,隨着交互次數提升而變化(圖源:GLM-4.5技術報告)
通用強化學習(General RL)融合規則反饋、人類反饋和模型反饋等多源獎勵體系,提升模型整體能力。包括使用指令遵循RL,減少獎勵作弊,確保穩定進步;函數調用RL分為逐步規則和端到端多輪兩種方式,提升工具調用的準確性和自主規劃能力;異常行為RL通過針對性數據集高效減少低頻錯誤。
強化學習訓練中,智譜使用了其自研並開源的基礎設施框架Slime,針對靈活性、效率和可擴展性進行了多項關鍵優化。其最大特點是在同一套統一系統中,同時支持靈活的訓練模式和數據生成策略,以滿足不同RL任務的差異化需求。同步共置模式適用於通用RL任務或增強模型推理能力,可顯著減少GPU空閒時間並最大化資源利用率。異步分離模式適用於軟件工程(SWE)等智能體任務,可實現訓練與推理GPU獨立調度,利用Ray框架靈活分配資源,使智能體環境能持續生成數據而不被訓練周期阻塞。
為了提升RL訓練中的數據生成效率,GLM-4.5在訓練階段採用BF16精度,而在推理階段使用FP8 精度進行混合精度推理加速。具體做法是在每次策略更新迭代時,對模型參數執行在線分塊FP8量化,再將其派發至Rollout階段,從而實現高效的FP8推理,大幅提升數據收集的吞吐量。這種優化有效緩解了Rollout階段的性能瓶頸,讓數據生成速度與訓練節奏更好匹配。
針對智能體任務中Rollout過程耗時長、環境交互複雜的問題,該團隊構建了全異步、解耦式 RL基礎設施。系統通過高併發Docker運行環境為每個任務提供隔離環境,減少Rollout開銷;並將GPU分為Rollout引擎與訓練引擎,前者持續生成軌跡,後者更新模型並定期同步權重,避免長或多樣化軌跡阻塞訓練流程。此外,智譜還引入統一的HTTP接口與集中式數據池,兼容多種智能體框架並保持訓練與推理一致性,所有軌跡集中存儲,支持定製化過濾與動態採樣,確保不同任務下RL訓練數據的質量與多樣性。
三、進行12項核心基準測試,編程任務完成率接近Claude
智譜對多款GLM-4.5模型的性能進行了測試。
未經過指令微調的基礎模型GLM-4.5-Base在英語、代碼、數學和中文等不同基準測試中表現穩定,較好地融合了各領域能力。
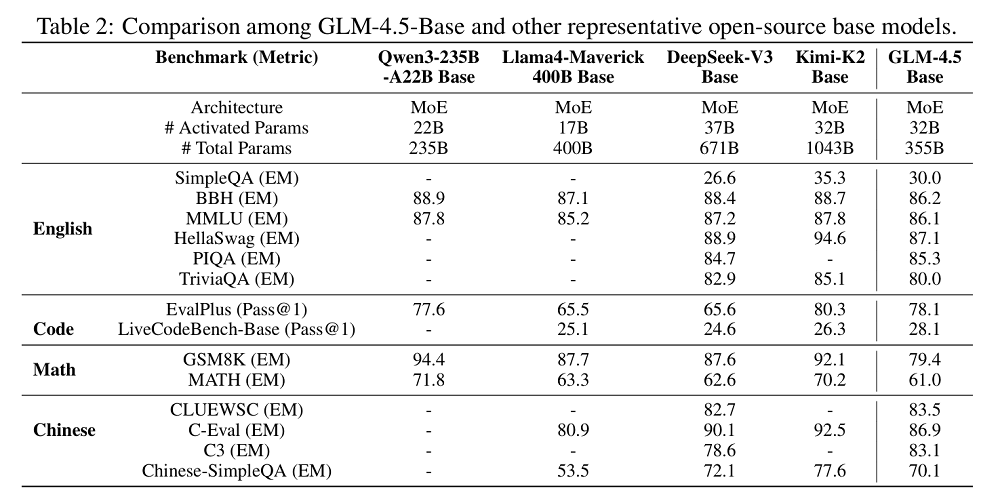
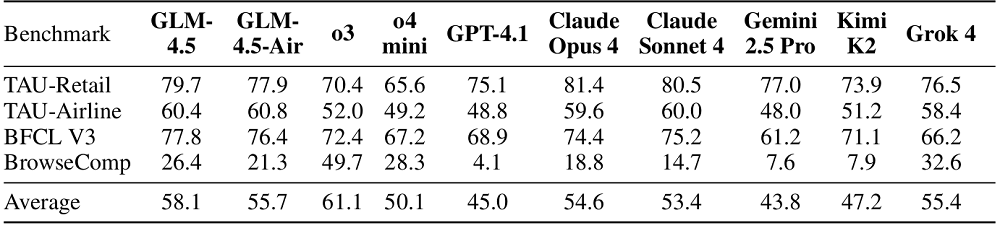
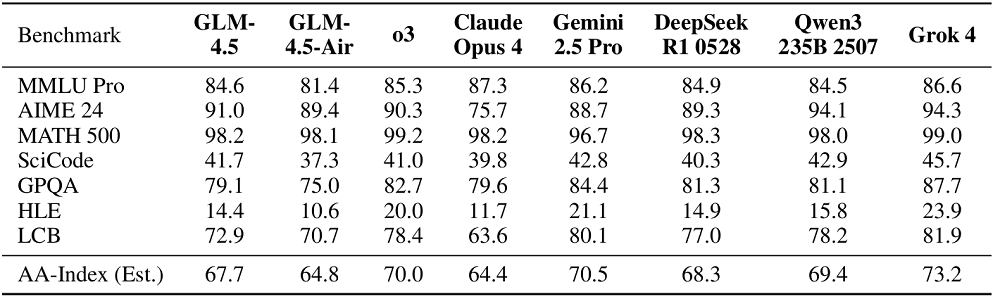
GLM-4.5還進行了12項ARC基準測試,分別為MMLU-Pro、AIME24、MATH-500、SciCode、GPQA、HLE、LCB(2407-2501)、SWE-BenchVerified、Terminal-Bench、TAU-Bench、BFCLV3、BrowseComp。
在智能體領域,基準測試主要考查了模型調用用戶自定義函數以回答用戶查詢的能力和在複雜問題中找到正確答案的能力。GLM-4.5在四項測試中的得分與平均分位列參與測試的模型前列,平均分僅次於OpenAI o3。
推理方面,智譜的測試集包括數學和科學知識等。GLM-4.5在AIME24和SciCode上優於OpenAI o3;整體平均表現超過了Claude Opus 4,並且接近DeepSeek-R1-0528。
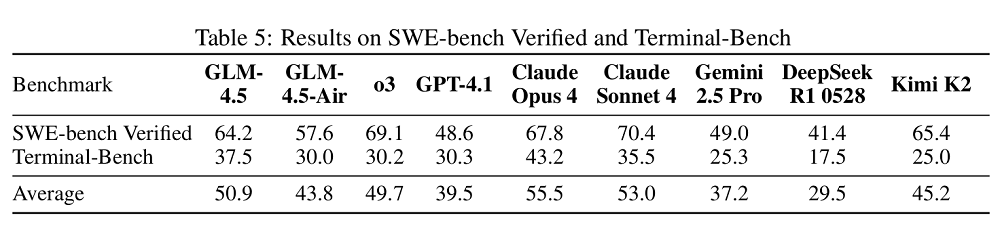
編程方面的基準測試側重考驗模型在真實世界編程任務上的能力。在SWE-bench Verified上,GLM-4.5 的表現優於GPT-4.1和Gemini-2.5-Pro;在Terminal-Bench上優於 Claude Sonnet 4。
為評估GLM-4.5在真實場景下的智能體編程能力,該團隊構建了CC-Bench基準,評估主要依據任務完成率(根據預先設定的完成標準判斷),若結果相同,則參考次要指標如工具調用成功率和Token消耗效率。評估優先關注功能正確性與任務完成,而非效率指標。
測試結果如下:
GLM-4.5 vs Claude 4 Sonnet:勝率40.4%,平局9.6%,敗率50.0%。
GLM-4.5 vs Kimi K2:勝率53.9%,平局17.3%,敗率28.8%。
GLM-4.5 vs Qwen3-Coder:勝率80.8%,平局7.7%,敗率11.5%。
智譜還在技術報告中分享了GLM-4.5在通用能力、安全、翻譯、實際上手體驗方面的特點。
結語:中國開源AI生態蓬勃
有越來越多的企業正採取模型權重開源+詳細技術報告的開源模式,這種方式不僅能讓企業第一時間用上開源模型,還能讓大模型玩家們從彼此的研究成果中借鑑,並獲得下一次技術突破的靈感。
在DeepSeek現象之後,國內AI企業通過密集的開源,已經逐漸形成了良性的國產開源AI生態,有多家企業在其他開源模型的研究成果上完成了創新。這種集體式的創新,或許有助於推動國產大模型獲得競爭優勢。