炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:虎嗅APP)

出品|虎嗅科技組
作者|SnowyM
編輯|陳伊凡
頭圖|視覺中國
「AI原生100」是虎嗅科技組推出針對AI原生創新欄目,這是本系列的第「12」篇文章。
8月8日,OpenAI最新模型GPT-5正式發布,但性能提升幅度遠沒有達到人們期待的「下一代模型」水準,雖然性能有一部分大幅提升,但有相當一部分並未與o3或者是Claude、Grok4拉開距離。
這個現象背後,整個AI行業正在面臨一個關鍵轉折點:僅僅通過增加數據量和計算資源來提升模型性能的傳統路徑,可能已接近天花板。
此時,一家給OpenAI喂數據的公司浮出水面——Turing。
2022年年初,Turing的CEO——喬納森·西達爾特(Jonathan Siddharth)從美國硅谷帕洛阿爾託,驅車前往OpenAI的辦公室。彼時的Turing是一家人力資源招聘公司。
在去的路上,他做好了給這家新興的硅谷AI巨頭推銷Turing產品的準備——Turing可以幫助OpenAI招聘人才。
當走進辦公室時,一堆OpenAI的研究員卻向喬納森提了一個需求——他們不要人,他們要數據。彼時,OpenAI的研究員們發現,在訓練GPT-3的數據集中,加入一些計算機代碼,有助於提高模型的推理能力。因此,他們希望Turning能夠給他們提供質量上乘的代碼,用於GPT-4的開發中。
這次會議,成為了Turing發展的拐點。只用了7年時間,這家公司從零達到22億美元估值,並且成為了繼Scale AI之後,硅谷第二家風頭正盛的數據標註公司。
如今隨着大模型能力的演進,互聯網上可公開的數據已經很少了,對更難生成的數據的需求將會急劇增長。隨着Scale AI被Meta收購,Turing將有希望在數據標註領域成為估值第一的公司。
虎嗅接觸了Turing的早期投資方——硅谷風投資機構UpHonest Capital,其投資人表示,他們對Turing團隊的第一印象是沉穩從容的連續創業團隊,對產品路線與商業化有清晰判斷;同時,Turing還通過高頻、透明的進展彙報營造出強烈的FOMO(形容創業者對新技術、新趨勢敏感的表現),善於動員資源。
彼時的Turing與現在的業務相距甚遠,UpHonest Capital投資Turing是2019年,正值Zoom上市,Zoom早期藉助了亞洲工程人才紅利快速成長,投資方認為,這是「人才地理套利」結構性機會,而Turing創始團隊具備亞裔跨境背景與執行力,在這一賽道擁有天然優勢。這也是他們投資Turing的原因。
不過,業內投資人也表示,Turing這樣的數據標註公司,本質上還是一種人力資源外包型企業,毛利率不高,需要精細化運作和控制成本。隨着如今數據標註公司越來越多,數據的質量成為了競爭的勝負手。
Turing正在書寫着"經濟上行期"的故事。
Turing最初切入的是遠程工程師招聘市場,憑藉AI驅動的人才雲(Talent cloud,Turing積攢的人才網絡)平台快速壯大。
2021年,公司成功躋身獨角獸行列。此時,他們已經有了400萬專業開發者的龐大人才網絡和ALAN AI平台(Turing自研的AI模型開發工具平台),併成為了最大、最國際化的開放人才平台之一。
但這遠不是故事的結局。
當OpenAI等頂級AI基礎模型廠商對數據的需求正在瘋漲時,Turing捕捉到這一機遇,果斷轉型為AGI基礎設施提供商,將以往積攢的龐大資源(軟件工程代碼數據及模型評估能力)包裝成標準化服務。
如今,頭部模型廠商基本都是Turing的客戶,例如,OpenAI、Anthropic、Google、Meta等頂級AI實驗室,Turing為他們提供模型訓練、微調和智能體開發等底層支持。
如果了解大語言模型的誕生經過就知道,大模型會先將大量從網頁上收集到的數據進行預訓練,然後再經過微調和後訓練,讓AI模型學習如何回答問題,在監督微調中,模型可以通過專門的數據,學會新的技能。這個專門的數據,就是Turing提供的,標註過的,高質量數據集。
這個目的是讓模型學習和泛化。因此,數據標註的專業性在這個環節就顯得尤為重要。
Turing的人才庫中,有涉及不同領域的專家。喬納森表示,他們要做的就是提供互聯網上搜不到的數據。
資本市場對Turing的認可度可以用「估值翻倍」來概括。2021年底的Series D輪孖展中,公司籌得8700萬美元,投後估值約11億美元,正式成為獨角獸。
2025年3月完成的Series E輪孖展:1.11億美元的資金注入讓估值直接翻倍至22億美元。這輪孖展由馬來西亞主權財富基金Khazanah Nasional Berhad領投,WestBridge Capital、Sozo Ventures、UpHonest Capital等十多家機構參投。
截至Series E完成,Turing累計孖展總額約2.25億美元。更值得關注的是其業績表現:2024年公司年度收入達到3億美元規模,較上一年增長三倍,併成功實現盈虧平衡。
我們梳理了Turing的孖展歷史:
最新財務數據顯示,Turing的 年度經常性收入(ARR)約3億美元。
Turing由Jonathan Siddharth和Vijay Krishnan於2018年聯合創立。

Vijay Krishnan(左)Jonathan Siddharth(右)
兩位創始人均擁有斯坦福大學計算機科學碩士背景,在校期間因對機器學習的共同興趣而結識,並萌生了聯合創業的想法 。研究生畢業後,他們多次合作技術項目並嘗試創業。
2008年,他們聯合創辦了內容推薦平台Rover,後於2016年被Revcontent收購 ,兩人深刻體會到僅依賴灣區本地招募頂尖工程師的侷限,於是開始嘗試遠程分佈式團隊的模式 。
在這個過程中,他們逐步摸索出如何高效甄別和管理全球各地的人才,並「無心插柳」地獲得了打造AI驅動的人才雲平台的靈感。
2018年,Jonathan和Vijay將這一洞見付諸實踐,創立了Turing,以機器學習技術對工程師進行技能審核和匹配,幫助企業「雲端組建」全球開發者團隊。
正如Jonathan所強調的,傳統線下招聘和外包模式已難以滿足高速發展的科技行業需求,他們希望通過Turing打造全球人才網絡,讓企業「不受地理位置限制找到世界上最優秀的人才」。
Turing的華麗轉身值得細說,因為他們所上演的故事幾乎堪稱傳統企業向AI企業轉型的標準教科書。
在收到OpenAI需求時,喬納森坦言,他們當時完全沒料到ChatGPT會引發AI熱潮,更沒想到「軟件工程師的代碼對教會大語言模型思考和推理如此重要」。「他們的要求簡直是瘋了,他們想要在這麼短的時間內獲得大量數據。」喬納森回憶。
但最後,Turing確實給OpenAI在模型性能上提供了巨大幫助,使得ChatGPT能夠在發布後,震驚世界。
另一面,Turing並沒有完全拋棄原有業務。創始人強調,各條業務線都在增長,只是把主要資源投入到AI相關的新業務上。這種務實的做法為新戰略提供了現金流支撐。

Turing的AI業務
轉型後的Turing形成了兩大核心業務板塊,即公司內部稱為「Turing AGI Advancement」和「Turing Intelligence」的兩條業務線。
Turing AGI Advancement專門服務全球頂級AI實驗室,幫助提升前沿基礎模型的各項能力。簡單說,就是讓AI模型變得更聰明。他們為OpenAI、Anthropic、Google、Meta等頂尖公司提供高質量訓練數據、代碼生成、模型微調等服務。
Turing Intelligence則致力於將前沿AI能力轉化為企業應用。面向財富500強企業和政府機構,構建定製的AI系統和解決方案,幫助傳統企業實現智能化升級。
兩條產品線分別對應"造模型引擎"與"用模型賦能",既服務AI行業本身,又將AI能力推廣到各行各業。
支撐業務發展的是Turing的兩大核心資產,這兩大資產又能夠形成閉環,為Turing提供源源不斷的專業數據資產。
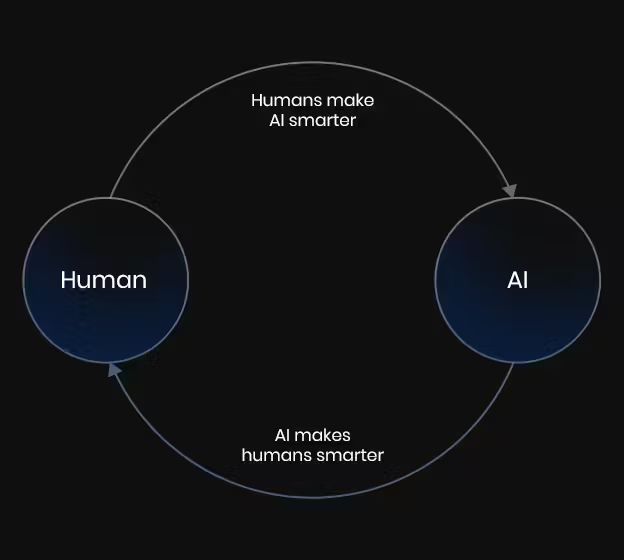
Turing的AI+人才循環
首先是AI驅動的人才雲平台。Turing聲稱通過自動化測試篩選,Turing從全球數百萬報名者中篩選出400萬技術人才,堪稱全球最大的人類智能網絡之一。當AI項目需要特定專家時,平台能迅速匹配合適團隊。
例如,當OpenAI需要大量Python/C++工程師編寫代碼來豐富模型訓練數據集時,Turing可以迅速組建起一支分佈式的專業開發者團隊投入任務 ;又如某製藥企業需要生命科學背景的標註人員來給模型做專業數據標記,Turing也能從人才庫中篩選出合格的PhD等高端人選。
其次是自研的ALAN AI工具平台,用於高效編排AI模型開發的各類工作流。ALAN將人類專家與機器算法緊密結合,支持從數據生成到模型評估的全流程自動化。Turing通過這個平台實現了模型訓練與優化的"流水線式"標準化生產。
Turing最初採用典型的人力資源外包模式,通過撮合企業與遠程開發者並抽取佣金盈利。
轉型後,商業模式變得更加多元:
在Turing AGI Advancement板塊,公司的主要客戶是全球頂級的AI模型研發機構。這些AI Labs利用Turing來獲取大規模的定製數據服務和人類反饋,例如為模型生成代碼語料、構建評測基準、執行模型對比測試,以及提供成百上千名有特定領域專業的標註人員進行RLHF微調等 。
Turing Intelligence板塊,則類似軟件項目制或訂閱制,從需求分析到部署運維,提供端到端的AI應用開發服務。在多個行業已有顯著成果,例如幫助醫院降低15%庫存成本、將製藥晶體分析時間從250小時縮短到2-3小時、提升銀行客服響應速度40%
2024年,Turing實現了盈利,這也證明了商業模式的可持續性。投資者也給予高度評價,從Foundation Capital、WestBridge到馬來西亞主權基金,每輪孖展都有頂級機構背書。
根據市場研究機構預測,全球AI數據收集與標註市場2024年的規模已達到約180億美元,預計2025年將增至約220億美元,此後幾年維持20–30%的年複合增長率 。
這一領域受到資本的熱烈追捧:Scale AI等頭部公司的高估值就是明證。例如Meta斥資143億美元收購Scale AI 49%股權,將該數據標註獨角獸估值推高至290億美元,並挖走其CEO負責Meta的超級智能項目 。
OpenAI的內部評估亦印證了這種趨勢——其表示,下一代模型若按傳統方式訓練,性能增益將大幅低於預期,GPT-5就是最好的例子 。為突破瓶頸,各大實驗室紛紛尋求解決方案,包括從企業自身業務中挖掘私有數據、生成合成數據、引入更多人類反饋等。
去年12月,OpenAI展示了一項叫做"Test-Time Scaling"的新技術測試結果,這被業界視為大模型在後預訓練時代提升能力的重要突破。這個技術簡單來說,就是讓AI在回答問題時花更多時間"思考",從而給出更準確的答案。
2024年下半年,OpenAI祕密開發了一個代號為"Orion"的新模型。公司內部原本計劃將它作為萬衆矚目的GPT-5發布,期望它能比當時最強的GPT-4o模型表現更出色。然而,測試結果讓人失望——Orion的表現並沒有達到預期的大幅提升。
從Orion到GPT-4.5再到GPT-5,海外媒體的許多報道印證了一個事實:性能提升確實不夠顯著。這期間,關於OpenAI面臨數據瓶頸的消息不斷傳出。特別值得注意的是,OpenAI前首席科學家Ilya Sutskever在一次公開演講中曾表示,支持Scaling Law(算力越大越好)的高質量訓練數據已經不多了。
一個顯而易見的趨勢是,數據標註正在進入「精英餵養」時代,各領域的專家,取代了初級數據標註員。
其中,引入海量高質量人類標註和代碼數據被證明是近期最有效的手段之一 。例如,Meta在訓練Llama3模型時投入了超過1000萬條人類標註數據 。但如此巨量且高質量的數據獲取絕非易事,必須建立起專業化的數據生產流水線。
這正是像Turing這樣的AI數據服務商崛起的背景:它們填補了AI實驗室「數據生產能力」的空白,幫助後者源源不斷地獲取所需的「燃料」,從而延續Scaling Law。
喬納森在Turing官網上發布了一篇文章提出,領先的前沿實驗室正在面臨新的挑戰——需要具有適當深度、多樣性和反饋結構的數據,從而真正釋放能力提升——這意味着,數據標註領域,正在進入「精英餵養」的模式。喬納森則表示,Turing採取的是中立的態度,不會與任何實驗室對抗。
Surge AI的創始人Edwin Chen表示,質量高於一切。Turing則能夠提供400多萬軟件工程師、數據科學家、領域專家的人才庫;能夠即時招聘跨專業領域的博士、奧林匹克級別的人才;發起人工智能驅動的審查,確保每位貢獻者的質量一致。
不過,隨着資本不斷湧入,這個賽道正變得越來越擁擠。數據質量是決定這個行業的勝負手,並且,當大語言模型的性能提升曲線逐漸平緩,對數據標註的質量要求將越來越高。
在AI數據服務領域,Turing和SurgeAI這兩家十分有潛力的AI公司走出了截然不同的路子,就像兩個基因不同的物種,各有各的生存策略。
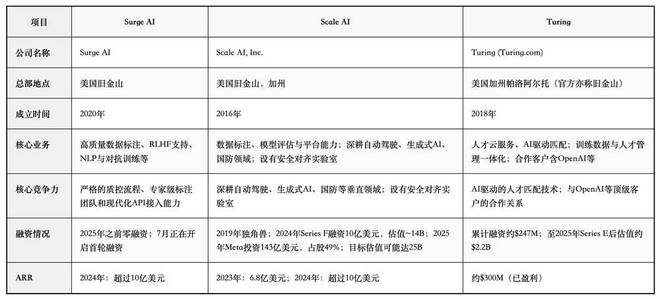
硅谷三大數據標註公司情況 虎嗅根據公開信息整理
Turing更像一個什麼都能幹的「一站式平台」。由於一開始的人才雲業務積累,它的業務範圍很寬,既能提供技術人員(工程師、數據科學家),又能提供高質量的代碼數據和評測,並依靠這些能力幫助企業搭建AI系統。
而Surge AI走的是精品路線,主要做多輪對話標註、AI安全測試、複雜評測等高難度任務,需要頂級專家和嚴格流程來保證質量。業內提到它的孖展時,都會強調"人類在環"這個定位。其創始人Edwin Chen在談及SurgeAI業務時,十分「驕傲」,並始終強調「質量為王」。
它的擴張邏輯與Turing完全不同:不求量大,但求價值高。圍繞高質量數據這個核心,不斷完善工具和流程,讓每個數據樣本都更值錢。
在AI數據提供這方面,SurgeAI雖然晚成立2年,但已經圍繞數據深入做好了相關技術儲備,甚至被稱為「業內早已公認超越了ScaleAI」,而Turing的資源池積累相對更大一些,未來的Turing還有多大上升空間,值得關注。

本文來自虎嗅,原文鏈接:https://www.huxiu.com/article/4673897.html?f=wyxwapp