炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:智東西)

智東西
作者 陳駿達
編輯 李水青
智東西8月9日報道,今天,宇樹科技創始人兼CEO、CTO王興興在2025世界機器人大會上,分享了他對全球機器人行業發展現狀的最新觀點。王興興認為,人形機器人行業已經走到「ChatGPT時刻」的前夜,最快1-2年就能迎來這一時刻。
王興興認為,由於政策支持與需求爆發,2025年上半年,人形機器人整機與零部件廠商平均實現了50%-100%的增長,幅度驚人。然而,行業內還存在幾大誤區:
首先,人形機器人大規模應用的最大問題,並不是硬件,而是具身智能。雖然硬件在量產工程化上仍有提升空間,但具身智能問題更為明顯,還無法驅動機器人自主地完成任務,這背後的原因並不是大家普遍關注的數據問題,而是模型架構問題。
王興興稱,未來2到5年,智能機器人技術的重心是端到端的具身智能AI模型。當前行業常見的VLA(視覺-語言-動作)模型,在他看來屬於「傻瓜式架構」,他個人對這類模型持懷疑態度。由視頻生成模型(或是世界模型)驅動機器人控制,是他眼中有望更快收斂的技術路徑。
同時,機器人研究還需要在強化學習Scaling Law(擴展定律)上實現突破,從而讓每次訓練的速度越來越快,學習新技能的效果越來越好。隨着機器人日益普及,分佈式的算力將成為大勢所趨,有望突破機器人本體搭載算力的限制,並滿足實際應用過程中對安全性和通信延遲的要求。
王興興還在演講中回顧了宇樹科技的發展,從2013年研發機器狗X dog原型機開始,並獲得8萬元的第一桶金,再到2023年應客戶需求推出首款人形機器人,他認為,機器人與AI的發展始終是一個全球共創的過程,他也鼓勵更多企業和高校參與到這一過程中。
以下是王興興部分精彩演講內容的整理(智東西在不改變原意的前提下,進行了一定程度的增刪修改):
我分享一下我個人對全球人形機器人行情的看法。今年上半年,最大的特點就是由於機器人行業非常火爆,以及政策的相關支持,整機廠商、零部件廠商,平均實現了50%到100%的增長。增長幅度還是非常嚇人的,這對整個行業而言都是十分罕見的,需求端拉動了整個的行業的發展。
海外市場方面,特斯拉作為行業代表,計劃今年量產數千台人形機器人,並將發布第三代Optimus人形機器人,值得重點關注。此外,全球企業對機器人行業的熱情高漲,包括英偉達、蘋果、Meta、OpenAI等企業都持續在推動這一領域的發展。
我分享幾個個人的觀點,未必準確。
第一點,對於機器人本體來說,很多人可能會有這樣一個誤區:機器人目前沒有大規模應用、功能不夠完善的原因,是硬件不夠好,或者成本比較高。
其實目前的硬件,無論是整機還是靈巧手,從某種意義上來說完全是夠用的。當然不夠好,還需要優化,更大的問題是量產,工程上的問題肯定是很多的。
但是在技術層面上,或者從AI的角度來說,目前的硬件是完全是夠用的。目前最大的挑戰還是具身智能,或者說AI技術的發展,完全不夠用。這也是限制當前機器人,尤其是人形機器人大規模的應用的最大問題。
目前,機器人行業所處的位置,就像是ChatGPT誕生前的1-3年左右,目前業界已經發現了類似的方向以及技術路線,但是沒人把它做出來。

ChatGPT出來的前幾年,做語音AI的已經做了十幾年,近二十年了,但是大家一直覺得他很傻瓜,很弱智,根本完全沒法用。ChatGPT出來後,它實現了比一般人還要強的能力。機器人還沒有到達這一臨界點。
對於機器人的AI技術,我覺得臨界點可能是這樣的:當一個人形機器人能夠進入一個完全陌生的環境(比如從未見過的會場),我跟他說「把這瓶水帶給某位觀衆」,或是「整理一下這個房間」,而它能夠順暢自主地完成任務,這就是人形機器人的ChatGPT時刻。
如果進展快的話,可能未來的1-2年或者2-3年,我們就能實現這一目標,最慢的話3-5年也有很大概率能實現。
目前,具身智能不夠用的問題,究竟是模型還是數據導致的?我反而感覺目前全球範圍內,大家對機器人數據這個問題的關注度有點太高了。現在最大的問題是反而是模型的問題,並不是數據問題。
對於具身智能和機器人來說,模型架構都還不夠好,也不夠統一。大家對模型問題的關注度高,反而對數據的問題關注很多。因為在大語言模型領域,大家覺得我有足夠多的數據,尤其有足夠多的好的數據的時候,我就能把模型訓練的越來好。
但是在具身智能,在機器人領域,大家可以發現,很多情況下有了數據,會發現這個數據用不起來。
相對比較火的就是VLA模型。VLA是一個相對比較傻瓜式的架構,我個人對VLA模型還是保持一個比較懷疑的態度。VLA模型在與真實世界交互時,它的數據質量、能採集的數據是不太夠用的。
有個簡單的想法,就是在VLA模型上面加一個RL的訓練,這是一個非常自然的想法。但是我個人感覺,包括我們公司目前嘗試下來VLA模型加RL訓練,我覺得還是不夠的,模型架構還是得再升級和優化。
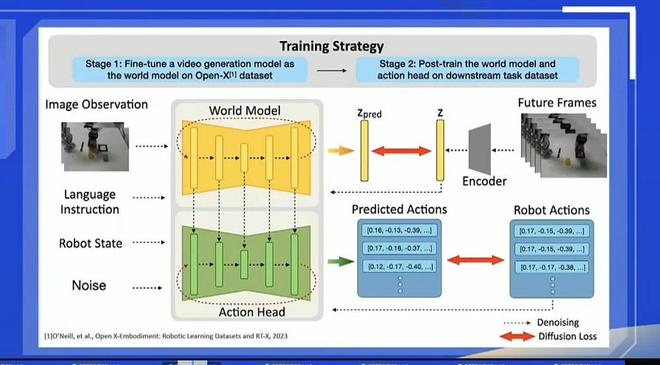
這裏也簡單分享一下我們過去做的一些事情。大家也可以關注到,谷歌發布了他們全新一代的視頻生成模型,或者某種意義上是一個視頻驅動的一個世界模型。還有,去年的時候,當OpenAI發布了視頻生成模型以後,大家會有一個很自然的想法:我可以控制一個視頻生成模型,跟他說「幫我生成一個機器人,去整理一下房間」。
如果模型生成的視頻中,機器人可以完成任務,那我是不是能讓這個視頻生成模型直接去驅動一個機器人完成任務。這個想法非常簡單直接,我們去年的時候就去做了這個事情。
大家可以看到,右上角的視頻其實是生成出來的,不是用攝像頭採集的。我們用一個預訓練的視頻生成模型,重新訓練了一下,讓他先去生成一個機器人動作的視頻,然後再控制一個機器人去做,這個技術是能實現的。包括谷歌的視頻生成世界模型,他們也想實現這個效果。

我覺得這個路線的方向可能會比VLA模型發展得要快,收斂概率還更大。但我不敢打包票,可能還是有很多問題。其中有個很大的問題就是,視頻生成模型太關注視頻生成的質量了,導致對GPU的消耗有點大。
對機器人幹活來說,某種意義上你並不需要很高精度的視頻生成質量,你只要驅動機器人去幹活就行了。大家可以關注谷歌的視頻生成模型,還是非常有意思的。整個模型的架構還是非常簡單粗暴的,就是把機器人的一些動作序列控制,直接對齊到模型的架構上。
另外一點,大家也知道,目前機器人跳跳舞、打格鬥效果其實不錯了,但實際上面臨一個很大的問題,如果要進一步機器人能力提升,也就是機器人RL的Scaling Law,還是做得非常不好。
舉個最簡單的例子,我訓練一個機器人做新的動作、跳新的舞蹈,都要重新訓練,還是從頭開始訓練,這是非常不好的一個事情。我們是希望機器人每次做一個新的訓練的時候,可以在過去訓練基礎上進行。
理論上我做RL訓練的時候,每次訓練的速度應該越來越快,學習新技能的效果越來越好。但是全行業內,目前整個機器人在RL的Scaling Law,沒有人做出來,做好。我覺得這是非常值得做的一個方向。
因為RL Scaling Law在語言模型上已經是充分驗證過的事情。但在機器人的運動控制上面,大家才啱啱開始。
我個人感覺,在未來2到5年,智能機器人技術的重心是端到端的具身智能AI模型。我覺得模型本身是最重要的。
然後就是更低成本的,更高壽命的硬件,這個是毋庸置疑的。大家也知道,哪怕對於汽車行業來說,已經一百多年了,哪怕到今天,一家企業要做很好的一輛汽車出來,工程量還是非常大的。
對機器人行業來說,未來如果每年要生產製造幾百萬、幾千萬甚至幾億的人體機器人,它的工程量挑戰還是非常驚人的。
同時,低成本的大規模的算力也很重要。在人形機器人上,或者在移動機器人本體上,其實沒辦法直接部署大規模的算力。它的尺寸只有這麼大,它的電池只有這麼大,它部署算力的功耗是有限制的。
我個人感覺在人形機器人上,最多隻能部署峯值功耗為100瓦的算力,平時工作的時候算力只有小几十瓦,簡單說就只有大概幾個手機的算力水平。
但是,未來機器人還是需要大規模算力的,而且我覺得可能是分佈式的算力。機器人幹活的時候,我們希望其通信延遲比較低的,如果在北京幹活的機器,數據中心在上海或者在內蒙,延遲實在是太大了。
我個人感覺,未來在工業領域大規模運用人形機器人時,工廠裏面可以有個分佈式的服務器,所有的機器人直接連接工廠裏的局部服務器就好了。服務器的安全性、通信延遲是可以接受的。
或者換一個話題,如果一個小區每家每戶有一個機器人的時候,在這個小區可能是有分佈式的集群算力中心的,可以保證延遲與安全性。並且,如果有新客戶想買一個人形機器人的時候,他不需要給這部分算力的建設花錢,成本也會更低很多。
我覺得分佈式算力會是機器人行業未來非常重要的一個領域,可能比目前算力的分佈還要更廣一些。
另外一點,大家也知道,在AI領域、機器人領域一直是一個全球共創的過程。中國的企業、美國的企業,包括英偉達等,已經做出了很多貢獻。
在AI領域,沒有一家大公司能保證,只要有足夠的人、有足夠的資源,我就能永遠領先。OpenAI和DeepSeek已經證明了,AI的創新永遠伴隨着一些隨機性,伴隨着更多的聰明年輕人的。所以很多情況下都是很多公司、高校做出的貢獻,還是要全球共創出來的。謝謝大家。