炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:機器之心Pro)

本研究由中山大學、鵬城實驗室、美團聯合完成,第一作者王豪為中山大學博士研究生,主要研究方向為圖像和視頻分割、開放場景視覺感知、多模態大模型等。論文共同通訊作者為梁小丹教授和藍湘源副研究員。
背景與動機
Segment Anything Model (SAM) 作為基礎分割模型在密集分割掩碼生成方面表現卓越,但其依賴視覺提示的單一輸入模式限制了在廣泛圖像分割任務中的適用性。多模態大語言模型(MLLMs)雖在圖像描述、視覺問答等任務中表現出色,但輸出侷限於文本生成,無法直接處理像素級視覺任務,這一根本性限制阻礙了通用化模型的發展。
中山大學、鵬城實驗室、美團聯合提出X-SAM—— 一個統一的圖像分割多模態大模型,將分割範式從 「分割萬物」擴展到 「任意分割」。X-SAM 引入了統一框架,使 MLLMs 具備高級像素級感知理解能力。研究團隊提出了視覺定位分割(Visual Grounded Segmentation, VGS)新任務,通過交互式視覺提示分割所有實例對象,賦予 MLLMs 視覺定位的像素級理解能力。為支持多樣化數據源的有效訓練,X-SAM 採用統一訓練策略,支持跨數據集聯合訓練。實驗結果顯示,X-SAM 在廣泛的圖像分割基準測試中達到最先進性能,充分展現了其在多模態像素級視覺理解方面的優越性。

方法設計
X-SAM 設計了通用輸入格式和統一輸出表示:
1)文本查詢輸入(Text Query)
2)視覺查詢輸入(Vision Query)
3)統一輸出表示
X-SAM 採用端到端的統一分割 MLLM 架構,包含以下核心組件:
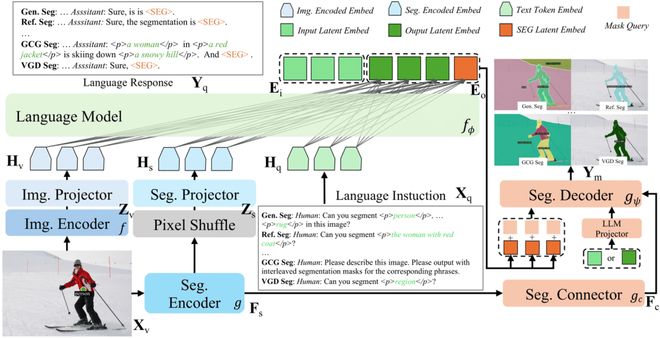
1)雙編碼器設計(Dual Encoders)
2)雙映射器架構(Dual Projectors)
為增強 LLM 的圖像理解能力,X-SAM 採用特徵融合策略。
3)分割連接器(Segmentation Connector)
針對圖像分割任務對細粒度多尺度特徵的需求,設計了分割連接器,為分割解碼器提供豐富的多尺度信息。
4)統一分割解碼器(Segmentation Decoder)
替換 SAM 原始解碼器,採用 Mask2Former 解碼器架構。
X-SAM 採用三階段漸進式訓練策略來優化多樣化圖像分割任務的性能:
1)第一階段:分割器微調(Segmentor Fine-tuning)

2)第二階段:對齊預訓練(Alignment Pre-training)

3)第三階段:混合微調(Mixed Fine-tuning)

針對訓練數據集規模差異(0.2K 到 665K 樣本),X-SAM 採用數據集平衡重採樣策略:
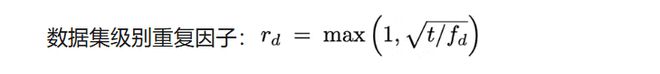
其中 t 為控制過採樣比例的超參數,f_d 為數據集 d 的頻率。在混合訓練過程中,根據 r_d 對數據集 d 進行重採樣,改善在少樣本數據集上的性能。
實驗結果
綜合性能指標
X-SAM 在超過 20 個分割數據集上進行了全面評估,涵蓋 7 種不同的圖像分割任務,實現了全任務最優性能。
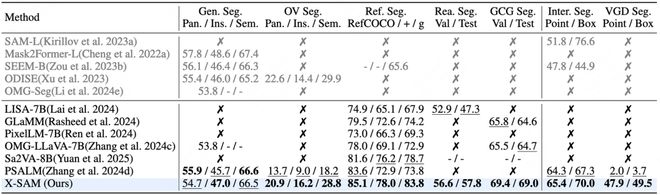
部分關鍵任務性能指標
指代分割任務:
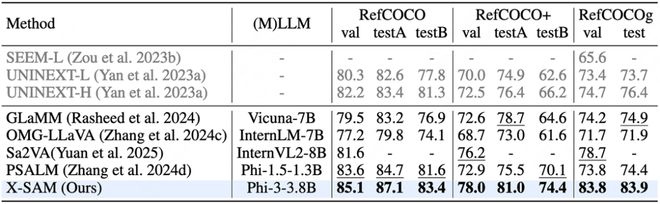
對話生成分割任務:
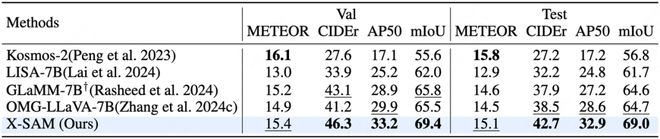
視覺定位分割任務:

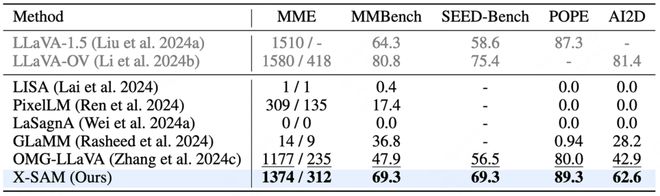
圖文理解任務:
可視化結果展示


總結與展望
X-SAM 作為首個真正統一的分割多模態大語言模型,成功實現了從「segment anything」到「any segmentation」的重要跨越。通過創新的 VGD 分割任務、統一架構設計和漸進式訓練策略,X-SAM 在保持各項任務競爭性能的同時,實現了更廣泛的任務覆蓋範圍,為圖像分割研究開闢了新方向,並為構建通用視覺理解系統奠定了重要基礎。未來研究方向可以聚焦於視頻領域的擴展。一是與 SAM2 集成實現圖像和視頻的統一分割,進一步擴展應用範圍;二是將 VGD 分割擴展到視頻中,引入視頻中的時序信息,構建創新的視頻分割任務,為視頻理解技術發展提供新的可能性。