炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:量子位)
大模型OUT,小模型纔是智能體的未來!
這可不是標題黨,而是英偉達最新論文觀點:
在Agent任務中,大語言模型經常處理重複、專業化的子任務,這讓它們消耗大量計算資源,且成本高、效率低、靈活性差。
相比之下,小語言模型則能在性能夠用的前提下,讓Agent任務的執行變得更加經濟靈活

網友的實測也印證了英偉達的觀點:當6.7B的Toolformer學會調用API後,其性能超越了175B的GPT-3。
7B參數的DeepSeek-R1-Distill推理表現也已勝過Claude3.5和GPT-4o。
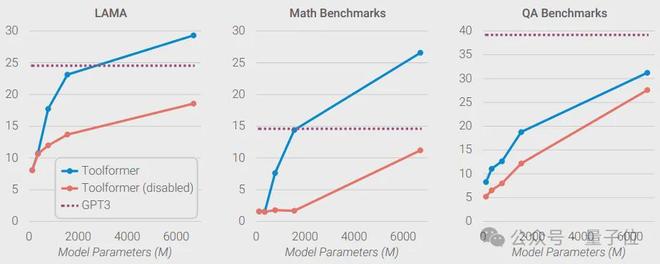
那麼,小模型是如何「四兩撥千斤」,放倒大模型的?
針對硬件與任務的優化
總的來說,小模型通過優化硬件資源Agent任務設計兩個方面來更高效地執行Agent任務。
首先是針對GPU資源和調度的優化
由於小模型「體積」小巧的獨特優勢,它們可以在GPU上高效共享資源,其可在並行運行多個工作負載的同時保持性能隔離。
相應的,小巧的體積還帶來了更低的顯存佔用,從而使得超分配機制得以可能,進一步提升併發能力。
此外,GPU資源還能根據運行需求靈活劃分,實現異構負載的彈性調度和整體資源優化。
而在GPU調度中,通過優先調度小模型的低延遲請求,同時預留部分資源應對偶發的大模型調用,就能實現更優的整體吞吐與成本控制
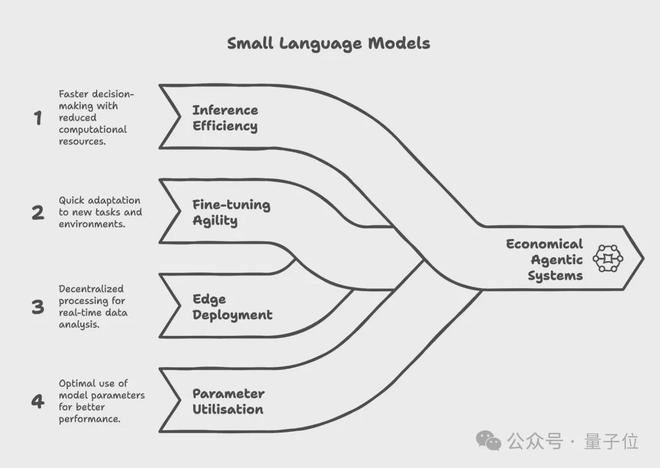
其次是針對特定任務的模型部署
在傳統的Agent任務場景中,Agent依賴大模型完成工具調用、任務拆解、流程控制和推理規劃等操作。
然而就像網友提到的,Agent任務往往是重複性的、可預測的、範圍明確的。譬如,幫我「總結這份文檔,提取這份信息,編寫這份模板,調用這個工具」,這些最大公約數需求最常被拉起。
因此,在大部分需求中,往往不需要一個單一的大模型來執行簡單重複的任務,而是需要為每個子任務選擇合適的工具。
基於此,英偉達指出,與其讓花費高企的通用大模型處理這些常見的任務,不如讓一個個經過專業微調的小模型執行每個子任務。
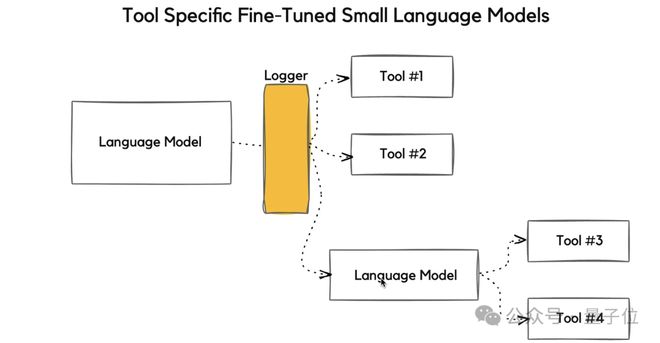
這樣一來,不僅可以避免Agent任務中,大模型「高射炮打蚊子」帶來的資源浪費,還可以有效地降低推理成本。
舉例來說,運行一個70億參數的小模型做推理,要比用700–1750億參數的大模型便宜10–30倍
同時,由於小模型計算資源佔用低,因而也更適合在本地或邊緣部署,而大模型則更多地依賴大量GPU的並行計算,依賴中心化的雲計算供應商,需要花費更多地計算成本。
此外,大模型還有「大船掉頭難」的毛病,不僅預訓練和微調成本遠高於小模型,難以快速適配新需求或新規則,而且還無法充分利用海量參數(一次推理只激活少量參數)。
與之相對,小模型則可以在較小數據量和資源條件下完成高效微調,迭代更快,同時還能憑藉更合理的模型結構和定製設計,帶來更高的參數利用率
不過,也有一些研究者提出了反對的聲音。
例如,就有研究者認為大模型因其規模龐大而具有更好的通用理解能力,即使在專業的任務中也表現更佳。
針對這一疑問,英偉達表示,這種觀點忽略了小模型的靈活性,小模型可以通過輕鬆的微調來達到所需的可靠性水平 。
同時,先進的Agent系統會將複雜問題分解為簡單的子任務,這使得大模型的通用抽象理解能力變得不那麼重要 。
此外,還有研究者對小模型相對大模型的經濟性提出了質疑:
對此,英偉達表示了部分地認同,但同時也指出:
最後,也是爭議的核心——雖然小模型部署門檻正在下降,但大模型已經佔先,行業慣性讓創新仍集中在大模型,轉型未必會真的降本增效。
這就引出了小模型在實際落地中要面臨的挑戰。
從大模型到小模型
英偉達表示,小模型雖然以其高效、經濟的特點在特定任務中表現出了不錯的潛力,但仍然需面臨以下挑戰:
由此看來,一種折衷的手段就變得未嘗不可:
為此,英偉達給出了將大模型轉換為小模型的方法:
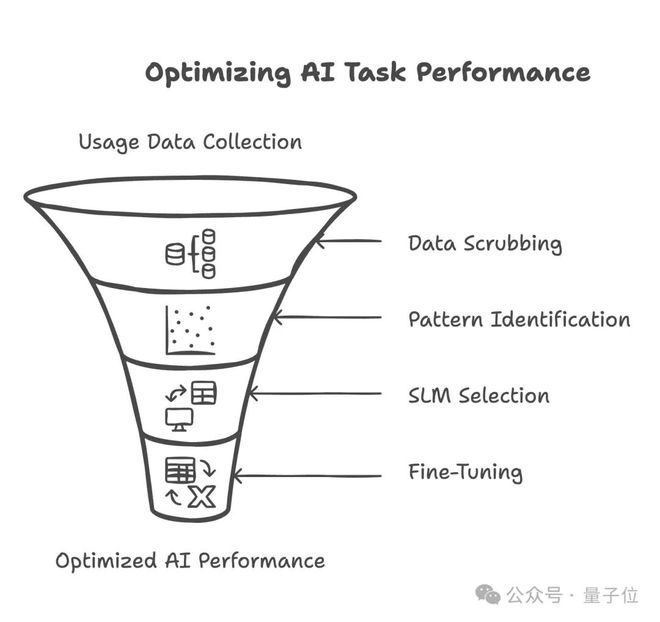
首先,通過數據採集記錄當前大模型的運行數據、資源佔用和請求特徵,然後對數據進行脫敏處理,只保留使用模式。
接着,根據請求類型和任務結構對工作負載進行聚類,識別常見子任務。
隨後,選擇合適的小模型,並匹配相應的GPU分配策略。在定製數據上完成模型微調後,將其部署上線服務。
最後,構建持續反饋閉環機制,不斷優化模型性能和資源利用率,實現迭代提升。
小模型vs大模型
圍繞英偉達的這篇論文,網友們針對「小模型纔是 Agentic AI的未來」這一觀點展開了討論。
例如,就有網友分享了自己在Amazon處理產品退款的心得,他認為在這種簡單的任務中,使用小模型比使用大型語言模型更具成本效益。
就像論文裏指出的,大模型在處理簡單任務時,其強大的通用性往往會被浪費,因此,使用小模型更為合適。

不過,也有網友提出了反對意見。
比如,小模型因其專業性在面對偏離預設流程的情況時,可能不夠魯棒。同時,為了應對這些corner case,設計者還需要預先考慮更多的變數,而大模型在應對複雜情況時可能更具適應性。

說起來,小模型就像Unix「一個程序只做好一件事」(Do One Thing and Do It Well)的設計哲學,把複雜系統(大模型)拆成小、專一、可組合的模塊(小模型),每個模塊做好一件事,然後讓它們協同完成更大任務。
但與此同時,系統也需要在功能多樣性和操作複雜度之間作出取捨。
一方面,小模型越多,那麼理論上其可以完成的任務就越豐富(功能多樣性高)。
另一方面,功能越多,用戶和系統操作的複雜度也會隨之增加,容易導致難以理解、難以維護或錯誤頻發,到頭來可能還不如一個通用的大模型方便。
到底是「少而精」的小模型更靠譜,還是「大而全」的大模型更穩?你怎麼看?
[1]https://x.com/ihteshamit/status/1957089843382829262
[2]https://cobusgreyling.medium.com/nvidia-says-small-language-models-are-the-future-of-Agentic-ai-f1f7289d9565
[3]https://www.theriseunion.com/en/blog/Small-LLMs-are-future-of-AgenticAI.html
[4]https://arxiv.org/abs/2506.02153