炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
(來源:機器之心Pro)

在機器人操作任務中,預測性策略近年來在具身人工智能領域引起了廣泛關注,因為它能夠利用預測狀態來提升機器人的操作性能。然而,讓世界模型預測機器人與物體交互的精確未來狀態仍然是一個公認的挑戰,尤其是生成高質量的像素級表示。
為解決上述問題,國防科大、北京大學、深圳大學團隊提出LaDi-WM(Latent Diffusion-based WorldModels),一種基於隱空間擴散的世界模型,用於預測隱空間的未來狀態。
具體而言,LaDi-WM 利用預訓練的視覺基礎模型 (Vision Fundation Models) 來構建隱空間表示,該表示同時包含幾何特徵(基於 DINOv2 構造)和語義特徵(基於 Siglip 構造),並具有廣泛的通用性,有利於機器人操作的策略學習以及跨任務的泛化能力。
基於 LaDi-WM,團隊設計了一種擴散策略,該策略通過整合世界模型生成的預測狀態來迭代地優化輸出動作,從而生成更一致、更準確的動作結果。通過在虛擬和真實數據集上的大量實驗,LaDi-WM 能夠顯著提高機器人操作任務的成功率,尤其是在 LIBERO-LONG 數據集上提升27.9%,超過之前的所有方法。
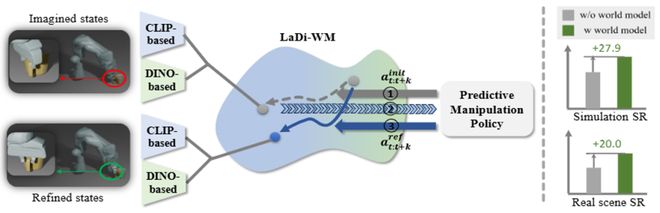

論文創新點:
1.一種基於隱空間擴散的世界模型:使用視覺基礎模型構建隱空間的通用表示,並在隱空間學習可泛化的動態建模能力。
2.一種基於世界模型預測迭代優化的擴散策略:利用世界模型生成未來預測的狀態,將預測的狀態反饋給策略模型,迭代式地優化策略輸出。
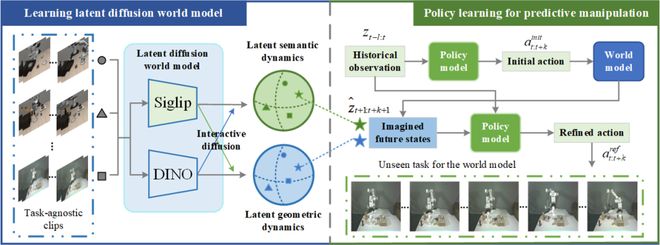 圖 1 :(左)通過任務無關的片段學習隱擴散世界模型;(右)通過世界模型的未來狀態預測來優化策略模型
圖 1 :(左)通過任務無關的片段學習隱擴散世界模型;(右)通過世界模型的未來狀態預測來優化策略模型技術路線
該團隊提出一種利用世界模型優化策略學習的框架,以學習機器人抓取操作相關的技能策略。該框架可分為兩大階段:世界模型學習和策略學習。
A. 世界模型學習:
(a)隱空間表示:通過預訓練的視覺基礎模型對觀測圖像提取幾何表徵與語義表徵,其中幾何表徵利用 DINOv2 提取,而語義表徵則使用 Siglip 提取。
(b)交互擴散:同時對兩種隱空間表示實施擴散過程,並在擴散過程中讓二者充分交互,學習幾何與語義表徵之間的依賴關係,從而促進兩種表示的準確動態預測。
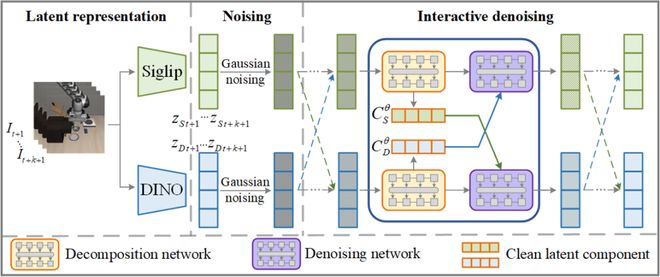 圖 2 : 基於交互擴散的世界模型架構
圖 2 : 基於交互擴散的世界模型架構B. 策略模型訓練與迭代優化推理
(a)結合世界模型的未來預測引導策略學習:將世界模型給出的未來預測作為額外的輸入,引導策略模型的準確動作預測;模型架構基於擴散策略模型,有利於學習多模態動作分佈。
(b)迭代優化策略輸出:策略模型可以在一個時間步多次利用世界模型的未來預測作為引導,從而不斷優化自身的動作輸出。實驗顯示,該方案可以逐漸降低策略模型的輸出分佈熵,達到更準確的動作預測。
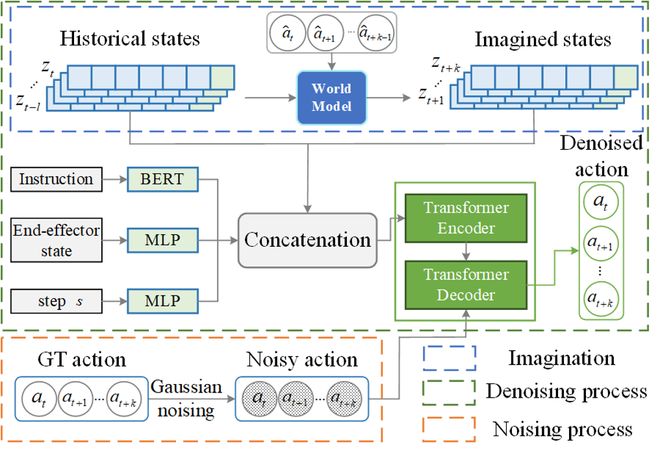 圖 3 : 基於未來預測引導的策略模型架構
圖 3 : 基於未來預測引導的策略模型架構實驗結果
虛擬實驗:
在公開的虛擬數據集(LIBERO-LONG,CALVIN D-D)中,團隊驗證了所提出框架在機器人抓取相關的操作任務上的性能。在實驗中,世界模型的訓練數據會與策略模型的訓練數據區分開,從而驗證世界模型的泛化能力。對於 LIBERO-LONG,給定語言指令,多次執行並統計機器人完成各項任務的成功率。對於 CALVIN D-D,連續給定五個語言指令,多次執行並統計平均完成任務的數量。
在 LIBERO-LONG 數據集,為了驗證世界模型對策略模型的引導作用,團隊僅使用 10 條軌跡去訓練各任務,對比結果如表 1 所示。相比於其他方法,LaDi-WM 能夠提供精確的未來預測,並將預測反饋給策略模型,不斷優化動作輸出,僅需少量訓練數據即可達到 68.7% 的成功率,顯著優於其他方法。
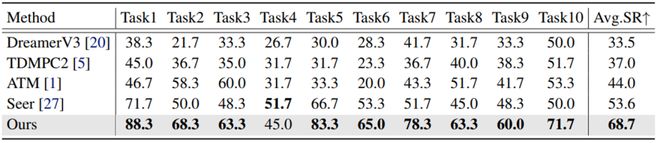
表 1: LIBERO-LONG 性能對比
在 CALVIN D-D 數據集上,LaDi-WM 同樣展示了在長時任務中的強大性能(表 2)。
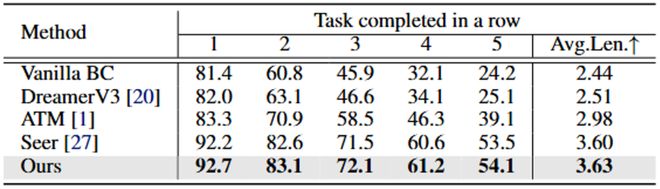
表 2: CALVIN D-D 性能對比
團隊進一步驗證了所提出框架的可擴展性,如圖 4 所示。
(a)逐漸增大世界模型的訓練數據,模型的預測誤差逐漸降低且策略性能逐漸提升;
(b)逐漸增大策略模型的訓練數據,抓取操作的成功率逐漸提升;
(c)逐漸增大策略模型的參數量,抓取操作的成功率逐漸提升。
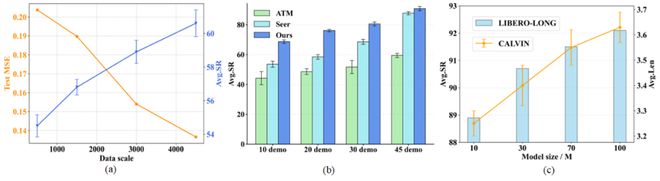 圖 4 : 可擴展性實驗
圖 4 : 可擴展性實驗為了驗證 LaDi-WM 的跨場景泛化能力,團隊在 LIBERO-LONG 上訓練世界模型,並直接應用於 CALVIN D-D 的策略學習中,實驗結果如表 3 所示。若是使用在 LIBERO-LONG 訓練的原始策略模型,直接應用到 CALVIN D-D 是不工作的(表第一行);而使用在 LIBERO-LONG 訓練的世界模型來引導 CALVIN 環境下的策略學習,則可以比在 CALVIN 環境訓練的原始策略的性能高 0.61(表第三行)。這表明,世界模型的泛化能力要優於策略模型的泛化能力。
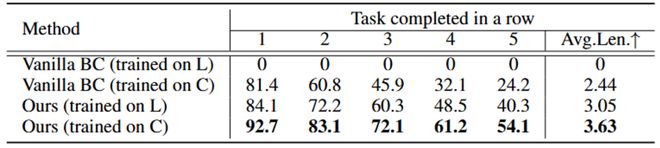
表 3: 跨場景實驗結果。L 代表 LIBERO-LONG,C 代表 CALVIN D-D
團隊進一步探索了利用世界模型迭代優化的工作原理。團隊收集不同迭代輪次下策略模型的輸出動作並繪製其分佈,如圖 5 所示。迭代優化的過程中,輸出動作分佈的熵在逐漸降低,這表明策略模型每一步的輸出動作更加穩定,從而提升整體的抓取成功率。
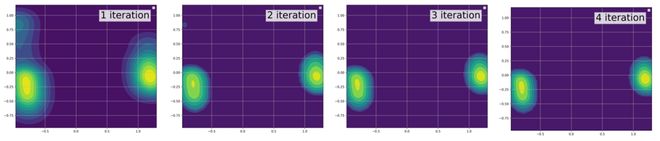 圖 5 : 迭代優化的動作分佈對比
圖 5 : 迭代優化的動作分佈對比真機實驗:
團隊也在真實場景中驗證了所提出框架的性能,具體操作任務包括「疊碗」、「開抽屜」、「關抽屜」以及「抓取物體放入籃子」等,如圖 6 所示。
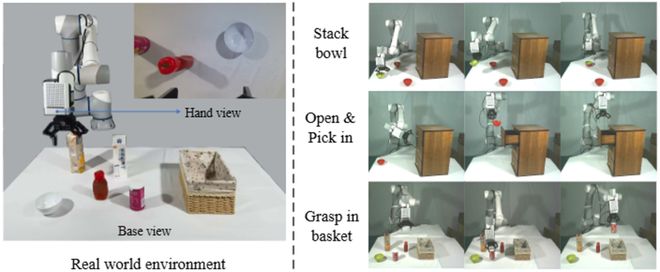 圖 6 : (左)真實場景環境;(右)機器人實際操作樣例
圖 6 : (左)真實場景環境;(右)機器人實際操作樣例在真實場景中,LaDi-WM 將原始模仿學習策略的成功率顯著提升 20%(表 4)。

表 4: 真實場景性能對比
圖 7 展示了最終所得策略模型在不同任務上的執行軌跡,從圖中可以發現,提出的策略能夠在不同光照條件以及不同初始位置的情況下有魯棒的泛化性。
 圖 7 : 真實場景機器人執行軌跡
圖 7 : 真實場景機器人執行軌跡總結
國防科大、北京大學、深圳大學團隊提出了一種隱空間擴散的世界模型 LaDi-WM(Latent Diffusion-based World Models),利用視覺基礎模型提取通用的隱空間表示,並在隱空間學習可泛化的動態建模。同時,團隊提出基於世界模型的未來預測來引導策略學習,在推理階段通過迭代式地優化策略輸出,從而進一步提高策略輸出動作的準確度。團隊通過虛擬與真機上廣泛的實驗證明了 LaDi-WM 的有效性,所提出的方法顯著提升了機器人抓取操作技能的性能。