從魔改PTX到使用 UE8M0 FP8 Scale 的參數精度,DeepSeek先榨取英偉達GPU算力,再適配國產芯片,可能會在軟硬件協同方面帶來新的突破,進一步提高訓練效率,最多可以減少 75% 的內存使用,從而在實際應用中減少對進口先進GPU芯片的依賴。
DeepSeek 正在與下一代國產GPU芯片廠商一起,走向算力自主又邁進一步。正是這樣一種令人激動的前景,激活了科技色彩愈發濃厚的中國資本市場。
V3.1,邁向Agent時代
DeepSeek 發布了 V3.1,而不是廣受期待的V4或者R2,連R1也消失了。DeepSeek變成了一個混合推理架構,即一個模型同時支持思考模式和非思考模式。這是一個趨勢,在V3.1發布一周之前,GPT-5發布了,是一個」統一的系統」,包括一個對話模型,一個思考模型,和一個實時路由用來決定如何結合對話與思考。
這次升級提高了DeepSeek的思考效率,即答對同樣的問題,消耗更少的token,花費更短的時間。這既是經濟上的考慮,也產品和用戶體驗上的考慮,避免了過度思考,讓回答也更簡潔一些。
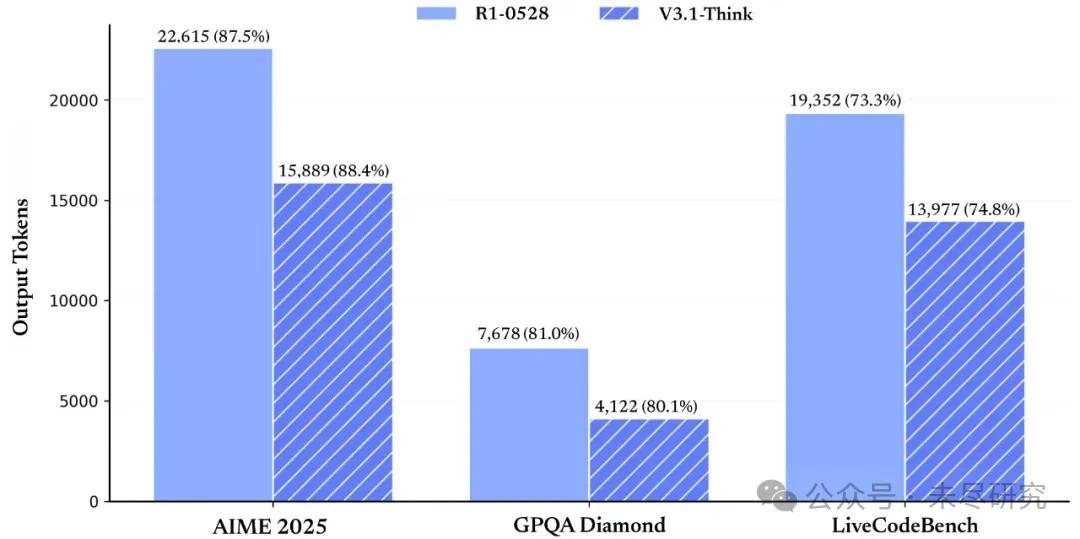
V3.1展示出更強的 Agent 能力,通過後訓練的優化,新模型在工具使用與智能體任務中的表現有較大提升。
V3.1的基礎模型在V3的基礎上重新做了外擴訓練,增加訓練了840B token。它的上下文長度,思考模式和非思考模式均達到了128k。性能提升,價格下降,再次秀出它所擅長的的性價比創新。
這次升級讓DeepSeek在最近中國AI企業的開源熱潮中奪回領先優勢,但不僅僅是想用來做科研和展示,而是要在企業服務能力上向國際前沿AI企業看齊。
DeepSeek的API Beta 接口支持了strict模式的Function Calling,以確保輸出的Function 滿足schema 定義。這其實是大模型API在工程化能力上的一個重要升級。OpenAI、Anthropic、Mistral 等都在逐步推出 strict function calling,向企業級生產環境對齊。Strict模式提升了V3.1的工程可靠性和企業易用性,更容易在企業服務中替代GPT/Claude。
同樣的思路,DeepSeek增加了對Anthropic API格式的支持,「讓大家可以輕鬆將 DeepSeek-V3.1 的能力接入 Claude Code 框架。」目的是為了讓使用Claude Code的用戶,更容易切換到DeepSeek。這樣可以直接滲透Anthropic已經打開的企業市場。最近Anthropic的企業服務收入,已經超過了OpenAI。
這次升級,對於DeepSeek來說的里程碑意義,是邁向Agent時代的第一步。
對中國的AI芯片生態,也具有里程碑意義。
深度求索的深水炸彈
DeepSeek在中文官微刻意強調、而在其英文X賬號上沒有提及的是,V3.1使用了 UE8M0 FP8 Scale 的參數精度。它還在留言處置頂:

這年頭,越是低調話少讓人有點看不懂,信息量越大。
在Hugginface 的模型卡中,DeepSeek又放出了一點信息:DeepSeek-V3.1 使用 UE8M0 FP8 縮放數據格式進行訓練,以確保與微縮放數據格式兼容。
簡單解釋下,FP8=8-bit floating point(8位浮點數),是一種超低精度表示方式。可以顯著減少顯存/帶寬需求,大幅提升推理和訓練效率,但需要精心設計縮放(scaling)來避免數值不穩定。
UE8M0是FP8的一種數字表示格式。U表示沒有符號,E8表示8位指數,M0表示沒有尾數。相比之下,英偉達在 H100、Blackwell GPU 上提供硬件級 FP8 支持,主推E4M3/E5M2格式,也是大多數模型採取的英偉達官方FP8格式。
所謂「微縮放數據格式」(Microscaling data format),即業界的Microscaling FP8 (MXFP8)標準。英偉達Blackwell GPU支持MXFP8。而V3.1訓練所用的數值體系與MXFP8兼容,模型在推理/部署時,可以直接在任何支持MXFP8 + UE8M0 的硬件(包括英偉達Blackwell、未來的國產GPU)上跑,不需要額外轉換,能降低內存流量、提升矩陣乘法吞吐。
對比一下E4M3/E5M2,UE8M0是一個變體,全指數,無尾數,能覆蓋極寬的動態範圍,是一種低算力環境下的工程優化。單就UE8M0而言,因為沒有尾數,也沒有精度,只用來存scale。高精度在內部計算中使用,過程是這樣的:輸入FP8,存儲時用scale調整,計算時自動轉換FP16/BF16/FP32,做乘加運算,輸出時再量化回FP8存儲,保證了訓練、推理的穩定性。
V3.1在訓練中使用UE8M0 FP8,並且兼容MXFP8,通過軟件定義與更多芯片適配,能讓超低精度訓練/推理在在中國自研芯片上更容易實現。
目前和即將採用FP8精度的國產GPU芯片,有寒武紀、沐曦、燧原、升騰等,還有更多主動適配DeepSeek的芯片廠商。
英偉達的低精度之路
值得一提的是,英偉達多年來一直用低精度數字表示法提升推理和訓練效率。例如在所謂的「黃氏定律」中,過去十年GPU實現的千倍效能提升,新的數字格式起到了最重要的作用。
英偉達的首席科學家戴利(Bill Dally),曾經把數字表示概括為GPU算力」黃氏定律「的精髓。
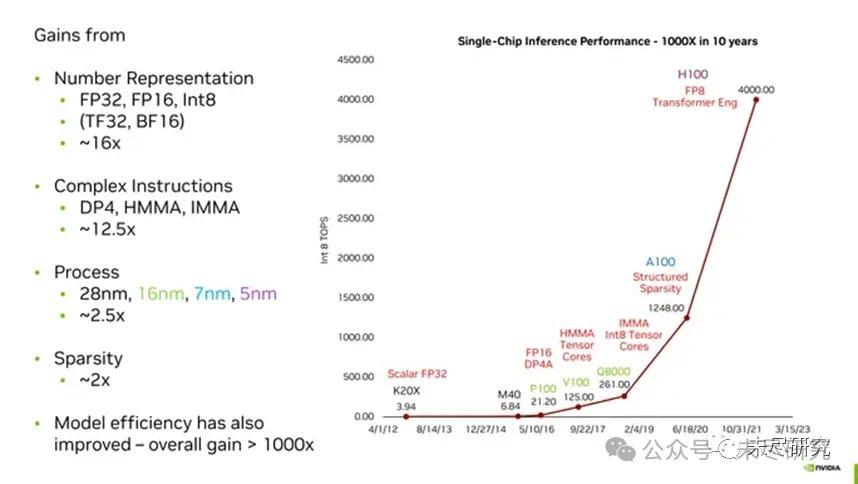
在P100之前,英偉達的GPU使用單精度浮點數表示這些權重。根據IEEE 754標準,這些數字長度為32位,其中23是尾數位,8是指數位,還有一位是符號位。
但是,機器學習研究人員很快就發現,在許多計算中,其數字可以不必有那麼高的精度,而神經網絡仍然可以給出準確的答案。這樣做的明顯優勢在於,執行機器學習的關鍵計算(乘法和累加)的邏輯可以更快、更小、更高效地完成。如果需要,就處理更少的位數(如戴利所解釋的,乘法所需的能量與位數的平方成正比)。因此,使用FP16,英偉達將該數字減少了一半。Google甚至推出了自己的版本,稱為Bfloat16。(兩者的區別在於分數位的相對數量,這影響精度;以及指數位的相對數量,這影響範圍。Bfloat16與FP32具有相同數量的範圍位,因此更容易在這兩種格式之間切換。)
到了H100這一代,可以使用8位數字執行大規模transformer神經網絡的某些部分,例如ChatGPT和其他大型語言模型。然而,英偉達發現這並不是一種大小適合所有情況的解決方案。例如,英偉達的Hopper GPU架構實際上使用兩種不同的FP8格式進行計算,一種具有更高的精度,另一種具有更大的範圍。英偉達的竅門,在於知道何時使用哪種格式。
英偉達對超低精度的一項研究
加州理工教授、英偉達前研究員Anima Anandkumar指出,V3.1在訓練中使用的UE8M0 FP8 scale數據格式,實際上是一種對數數值系統(LNS),來自她當年參與的一個研究項目。
英偉達和加州理工的研究人員,在2021年時曾經發表過一篇論文《LNS-Madam:在對數數值系統中採用乘法式權重更新的低精度訓練》(LNS-Madam: Low-Precision Training in Logarithmic Number System using Multiplicative Weight Update),探討如何以低精度表示深度神經網絡(DNN),實現高效加速並減少內存佔用。
如果直接用低精度權重進行訓練,會因低精度數值系統與學習算法之間的複雜交互而導致精度下降。為了解決這一問題,研究人員設計了對數數值系統(Logarithmic Number System, LNS)和乘法式權重更新算法(Madam)。他們證明了 LNS-Madam 在權重更新過程中能保持較低的量化誤差,即使在精度受限的情況下也能獲得穩定性能。他們還進一步提出了一種 LNS-Madam 的硬件設計,解決了實現高效 LNS 計算數據通路中的實際挑戰,有效降低了由 LNS-整數轉換和部分和累加(partial sum acculmlation) 帶來的能耗開銷。
實驗結果表明,在計算機視覺和自然語言等主流任務中,LNS-Madam 僅使用 8 位精度就能實現與全精度相當的準確率。與FP32和FP8相比,LNS-Madam能分別降低超過90% 和 55%的能耗。
DeepSeek的超低精度創新
UE8M0實際上等價於 LNS 的一個極簡實現,因此可以說UE8M0是LNS的一種特化(只保留log值的整數部分,沒有小數精度),所以Anandkumar教授纔會把UE8M0縮放數據格式稱作一種LNS。
如果說LNS-Madam 一種學術探索,是重新設計數學體系+算法,是硬件和算法一體化的設計思路,UE8M0+FP8是一種在現有浮點體系上結合縮放的工程技巧。二者低精度訓練的目標一致,但路線完全不同。
UE8M0並不是用來直接存權重,而是用來存縮放因子(scale factor),幫助其它 FP8(E4M3/E5M2)穩定表示數據,讓 FP8能夠覆蓋更廣的數據分佈,從而在硬件上更高效。
追求算力自由
回顧一下DeepSeek兩個階段的突破點。
首先是先榨乾現有硬件的潛力。DeepSeek V3直接修改英偉達GPU的虛擬機指令集架構 PTX,繞過英偉達編譯器的保守策略,手工調度寄存器、warp、訪存和Tensor Core指令。把GPU算力利用率提升到極限,降低硬件受限下的訓練/推理成本。在DeepSeek手中,A100/A800等英偉達 GPU上的現有算力都得到最大化利用。
第二階段降低算力的物理需求。DeepSeek V3.1引入UE8M0 FP8格式,讓中國國產 AI 芯片(帶寬/算力較弱)也能高效運行大模型。採用更緊湊的低精度浮點格式,大幅壓縮內存/帶寬佔用,減少計算負擔,可以期待下一代國產GPU芯片能進行前沿大模型訓練推理。
DeepSeek在工程實踐中走出了一條算力自主之路:先榨取英偉達,再適配國產芯片,最終走向算力自主。長期來看,DeepSeek將沿着軟硬件協同優化的路線,構建一個 「算力無關」的模型生態。
中國還需要H20/B30嗎
由於技術與安全等原因,已經傳出英偉達停止生產H20的消息。目前依然存在懸念的,是黃仁勳是否向中國提供B30。
回顧一下,英偉達定製H20 / B30給中國市場,因為美國出口管制禁止向中國出售H100/H200/B100/B200等高端GPU。黃仁勳的策略,是推出縮水版芯片,為中國定製了H20(基於 Hopper)和B30(基於 Blackwell),在算力、互聯、帶寬上降低配置,但仍保持 CUDA 生態兼容,以保住中國市場,避免中國廠商快速完全轉向國產芯片。同時遵守美國出口管制。
即使DeepSeek魔改PTX,一時造成了英偉達股價暴跌,也並沒有影響黃仁勳的策略,老黃反而一直想見梁文鋒。因為它心裏明白,也公開表達過,以中國的人才,尤其是軟件人才,實現AI芯片與模型生態的自主閉環,只是時間問題。
沒想到的是UE8M0+ 超低精度的衝擊,以如此低調的方式釋放。它意味着中國廠商對於H20/B30的需求,正在發生微妙的變化。如果國產下一代GPU芯片近期推出,而且支持UE8M0+FP8 跑通大模型,英偉達的縮水卡在中國市場上的競爭力下降。一旦國產芯片生態完善,CUDA 生態的鎖定效應會逐漸削弱。
中國市場還需不需要B30?有一種業內觀點認為,短期依然需要,因為國產GPU產能、軟件生態還在追趕。大部分企業,尤其是互聯網大廠和科研機構等,仍依賴CUDA工具鏈和現成框架。H20/B30在推理與訓練上仍然比國產芯片更穩健。也許B30本身的相對先進性,即弱於最先進的GPU、但仍強於國產GPU,才能決定它能否得到中美兩國有關部門的接受。
隨着國產芯片+超低精度訓練將逐漸跑通並規模化部署,中長期來看對於B30們的需求會明顯下降。國產AI軟件棧(升騰CANN、寒武紀 Neuware、壁仞 BIRENSUPA)逐步成熟,逐漸減少對 CUDA 的依賴。成本敏感的中國企業會更傾向國產方案,同時避免美國找麻煩。
英偉達的優勢何在
UE8M0+FP8,好像是DeepSeek接過了英偉達近十年來的低精度數字表示技術的大旗,結合中國的實際進行工程創新,它將加快中國下一代芯片的推出,加快以國產芯片解決中國大規模訓練和推理的需求,從而形成中國AI芯片與模型的技術路線。
使用UE8M0 FP8 Scale的參數精度,適配國產下一代芯片,兼容MXFP8,並不意味着英偉達失去了優勢主導地位,因為 G200 不只是 FP8,還帶來更大帶寬、更強互聯(NVLink 5)、更大顯存。軟件生態(CUDA、PyTorch 插件)也牢牢綁定 FP8,遷移到 UE8M0 需要額外工程適配。大部分國際大廠(OpenAI、Anthropic、Meta)還是會首選 G200 來追求極致性能。「黃氏定律」已經推進至FP4精度,英偉達還曾親自下場發布了優化版的DeepSeek-R1-FP4,內存需求大幅降低,基準測試成績幾乎不變。
如果 UE8M0+FP8 在社區和國產硬件上普及,低成本訓練路徑會弱化英偉達的必選性。這對中國廠商尤其重要,即使沒有 G200,也能在國產 GPU 上穩定訓練大模型,形成去英偉達化的路線。