文|極智GeeTech
理想主義者是值得尊敬的,但很少成功。在當下的輔助駕駛領域,尤為如此。
2025年智能輔助駕駛戰場,瀰漫着「短平快」的焦慮。部分車企依賴人工採集「老司機數據」,甚至僱佣數百人實車路測,成本高昂卻效率低下。同時,「端到端+VLM」架構遭遇瓶頸——訓練數據突破1000萬Clips後,性能增長緩慢。實車測試無法復現極端場景,接管里程的數字繁榮背後隱藏着極端場景的未解難題。
面對這些現象,現有端到端模型已給不出更多答案,端到端模型像猴子開車,能夠學習人類行為,但並不理解物理世界。傳統用規則算法「修補」端到端缺陷的方式已然失效,而現在,理想、小鵬等造車新勢力正在推翻現有架構,以全新的VLA大模型重燃新一輪智駕戰火。

新勢力押注VLA
在最近理想和小鵬首發的i8和G7 Ultra中,VLA成為關鍵技術。
理想i8核心亮點就是VLA「司機大模型」,這是理想汽車智駕領域繼去年推出「端到端+VLM」之後的又一新進展。理想VLA的所有模塊經過全新設計,空間編碼器通過語言模型並結合邏輯推理,給出合理的駕駛決策,並通過Diffusion(擴散模型)預測其他車輛和行人的軌跡,進一步優化出最佳的駕駛軌跡。

8月15日,小鵬汽車宣佈,小鵬G7 Ultra的VLA能力再度提前,現已明確8月內可以開啓首批推送。「高速人機共駕」等功能,不僅即將登陸Ultra車型,也會通過OTA推送至Max車型。

據稱,小鵬G7 Ultra車型將搭載本地端VLA模型,具備VLA思考推理可視化、語音控車、主動推薦等功能。這一版本使用了3顆小鵬汽車自研的圖靈AI芯片,綜合算力高達2250TOPS。
「端到端+VLM」被視為區分智能輔助駕駛技術的分水嶺。在此之前,NPN(先驗網絡)輕圖、無圖均是人工時代的技術,而人工時代的最大特點是「規則算法」,需要工程師設計算法並編寫程序,因此提升輔助駕駛性能依賴於工程師的能力和經驗。
然而,從「端到端+VLM」開始,車企不再用傳統的方式做,「端到端+VLM」架構的本質是模仿學習,是用人類駕駛數據訓練模型,數據數量和質量決定性能。
這場智能輔助駕駛的比拼特別像體育界的鐵人三項,要想贏得競賽,需要三個核心要素:技術、工程和產品。智能輔助駕駛要實現好用、愛用,需要關注兩個維度。一個是Scale up(性能提升),即把系統打磨到可以處理各種極端環境和複雜交通流;另一個是Scale out(場景泛化),即系統在全場景下在不同的時間、天氣、環境和不同的城市都可以有很好的表現。
從技術路徑看,無論端到端也好,還是VLM也罷,最後來看都將殊途同歸,就是建立VLA流程,整體系統會更加接近於人的應激反應,(感知)看到什麼,(規控)就能做出相應的駕駛動作。不少智駕行業人士都將VLA視為當下「端到端」方案的2.0版本,認為這是未來確定的技術路線,只是實現的時間快慢問題。
在智能輔助駕駛的發展過程中,VLA和一段式端到端是兩個較為主流的技術路徑。
VLA作為一種融合了視覺(Vision)、語言(Language)和操作決策(Action)的多模態大模型,是介於傳統模塊化和端到端之間的技術架構。它不直接控制車輛,而是先把路況轉化為「語義信息」,比如把感知硬件看到的車道、障礙物、紅綠燈等信息做成語義標註,包括文本描述和視覺關聯,動作生成器綜合視覺和語義信息輸出決策。
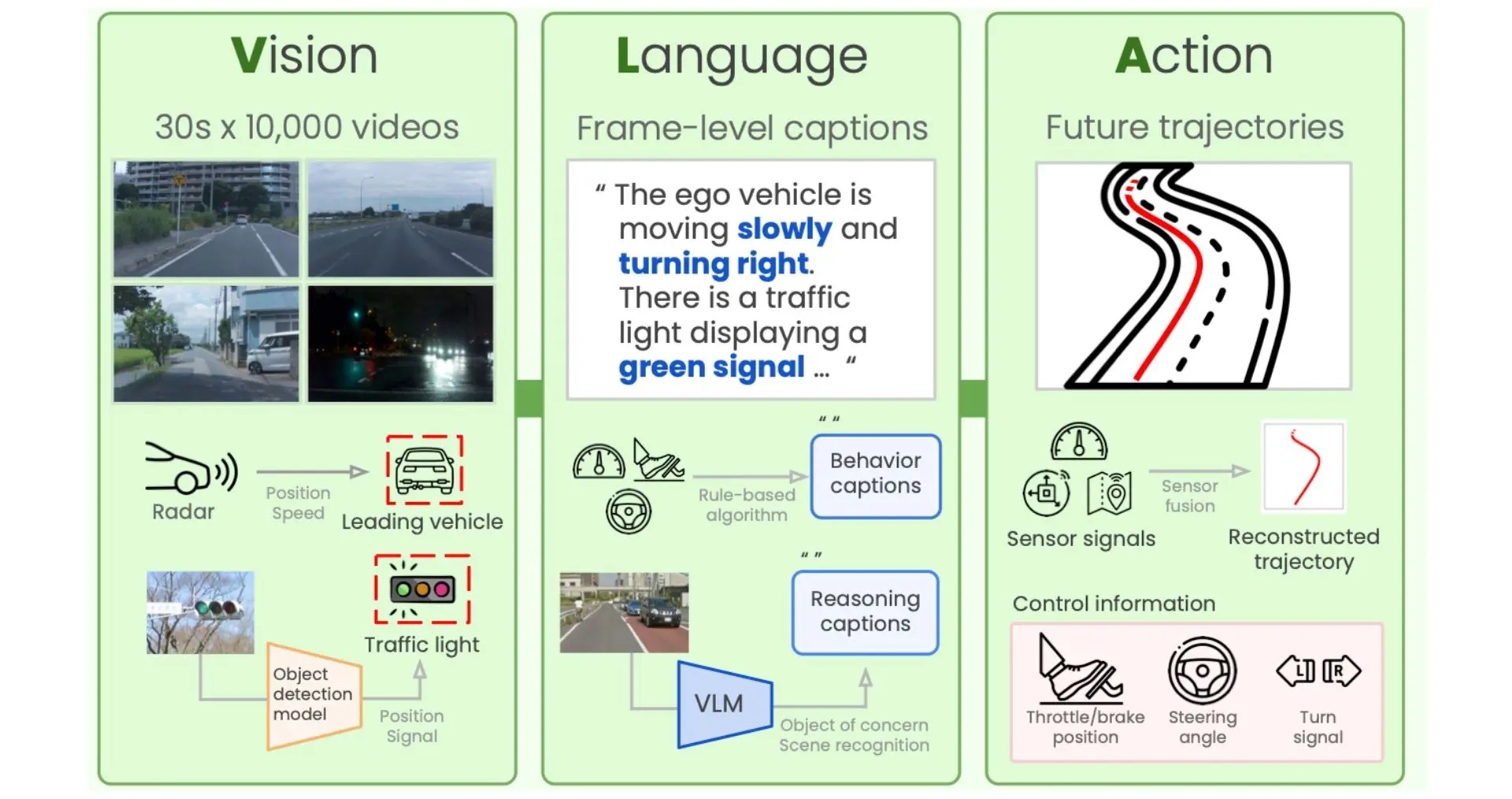
從理論上分析,作為多模態大模型,VLA具有強大的場景推理和語言理解能力,可適應複雜、邊緣情況或動態交通環境。此外,由於融入了「世界知識」和「常識推理」,VLA理論上具備更高上限的智能行為。
比如,VLA可以理解城市中的「潮汐車道」「公交車道」等指示牌的文字信息,甚至可以理解駕駛者的語音指令並做出相應的動作。
VLA架構下,端到端與多模態大模型的結合將會更徹底。但更具挑戰的是,當端到端與VLM模型合二為一後,車端模型參數將變得更大,這既要有高效實時推理能力,同時還要有大模型認識複雜世界並給出建議的能力,對車端芯片硬件有相當高要求。
如何將端到端與多模態大模型的數據與信息進行深度交融,實現軟硬件的無縫融合與協同配合,將考驗着每一個智能輔助駕駛團隊的模型框架定義能力、模型的工程開發能力以及模型快速迭代能力。
在過去一年,幾乎所有主流的車企在輔助駕駛上都更新成了端到端大模型驅動的系統,在短時間內性能和體驗提升都比較明顯。但端到端黑盒的研發模式,導致了部分Corner Case無法追溯產生的原因,這也導致一部分車企很快地從「熱戀期」進入到了「瓶頸期」。
即使是當前TOP級別的端到端系統,在面臨複雜道路結構疊加複雜車流博弈時大多數情況也會崩潰。行業普遍面臨瓶頸,所以很自然地有公司開始探尋上限更高的新架構。
而VLA通過語言模型的引入,很好地解決了研發和用戶兩端黑盒的問題。
不過,這並不意味着端到端不值得投入開發。如果規則算法都做不好,那麼根本不知道怎麼去做端到端;如果端到端沒有做到一個非常極致的水平,那連VLA怎麼去訓練都不知道。換句話說,在端到端上取得大規模成功量產經驗,是探索VLA的一個門檻。
為什麼是VLA?
過去幾年,輔助駕駛經歷了三種架構的迭代:規則算法、端到端、VLA,這是一個從指令控制,到模仿行為,再到理解意圖的過程。每一代技術都在不停地提升算力、平均接管里程,本質上是要不斷接近人類的駕駛方式。
輔助駕駛的人工時代到現在AI時代的分水嶺,是從無圖到端到端。在原來輕圖、NPN 或者無圖的人工時代,輔助駕駛的核心是規則算法。
最早的輔助駕駛採用模塊化架構,由於感知、規劃及執行系統相對獨立,且每個步驟都要佔用一定的計算時間,整體系統的響應較慢,延時較高。
簡單來說,就是需要在既定的規則下,同時依賴高精地圖,類似螞蟻的行動和完成任務的方式。但無法完成更復雜的事情,需要不斷地加限定規則。
人工時代的侷限性在於,單靠人力難以解決所有場景,很多場景是「按下葫蘆起來瓢」,於是輔助駕駛進入了端到端時代。
端到端階段通過大模型學習人類駕駛行為,足以應對大部分泛化場景,但端到端很難解決從未遇到過或特別複雜的問題,此時需要配合VLM。VLM對複雜交通環境具有更強的理解能力,但現有VLM在應對複雜交通環境時只能起到輔助作用。
「端到端+VLM」的核心是模仿學習,用人類駕駛的數據來訓練模型。這個技術階段,決定性的因素就是數據。數據多,覆蓋的場景全,數據質量好——最好是來自老司機,這時訓練模型的性能就會非常好。
但模仿學習終究有上限。相比過去只依賴真實駕駛數據,VLA採用生成數據和仿真環境結合的方式,讓模型能在無風險、可控的虛擬世界中自主進化。這套思路如今也正在被更多車企採納,VLA正成為智能駕駛的新共識。
由於人類駕駛數據存在嚴重的分佈不均,大多集中在白天、晴天、正常通勤等常規場景,真正複雜或危險的工況數據稀缺且難以採集。而訓練具備真實決策能力的模型,恰恰需要這些邊緣與極端場景。
這就要求引入合成數據和高質量仿真環境,用生成式方法構建覆蓋更全、分佈更廣的數據集,同時不斷評測模型表現。最終決定模型性能提升速度的關鍵,不是收集了多少真實數據,而是仿真迭代的效率。相比傳統的數據驅動方式,這是一種更具主動性的訓練方式。
事實上,VLA並不是一套跳級的打法,而是端到端之後的自然發展。如果沒有經歷過端到端階段對模型感知、決策、控制等環節的完整訓練,就無法一步跨入VLA。
在VLA階段,利用3D視覺和2D的組合構建更真實的物理世界,此階段系統可實現看懂導航軟件的運行邏輯,而非VLM階段僅能看到一張圖。
同時,VLA不僅能看到物理世界,更能理解物理世界,具有自己的語言和思維鏈系統,有推理能力,可以像人類一樣去執行一些複雜動作,能夠更好的處理人類駕駛行為的多模態性,可以適應更多駕駛風格。
在海量的優質數據的加持下,VLA模型在絕大多數場景下能接近人類的駕駛水平;隨着偏好數據的逐步豐富,模型的表現也逐步接近專業司機的水平,安全下限也得到了巨大的提升。
VLA雖然給自動駕駛行業提出了新的可能,但實際應用依舊面臨很多挑戰。
首先是模型可解釋性不足,作為「黑盒子」系統,很難逐步排查在邊緣場景下的決策失誤,給安全驗證帶來難度。
其次,端到端訓練對數據質量和數量要求極高,還需構建覆蓋多種交通場景的高保真仿真環境。另外,計算資源消耗大、實時性優化難度高,也是VLA商用化必須克服的技術壁壘。
為了解決上述問題,車企也正在探索多種技術路徑。如有通過引入可解釋性模塊或後驗可視化工具,對決策過程進行透明化;還有利用Diffusion模型對軌跡生成進行優化,確保控制指令的平滑性與穩定性。同時,將VLA與傳統規則引擎或模型預測控制(MPC)結合,以混合架構提高安全冗餘和系統魯棒性也成為熱門方向。
智能輔助駕駛接近決戰時刻
理想、小鵬並不是智能輔助駕駛領域的先行者,當技術方向清晰後,它們迅速通過投入大算力和海量的數據,快速驗證路徑,追上了對手。這種路徑適用於車輛保有量大、且駕駛數據可有效回傳的車企。但隨着時間的推進,落後者的機會窗口逐漸縮窄。
從端到端到「端到端+VLM」再到VLA,其中需要面臨很多現實難題,比如多模態對齊工程龐大,成熟度亟待提升,多模態數據的獲取和訓練也十分困難,對於算力需求更是水漲船高。
目前,行業應用的主流英偉達Orin芯片單顆算力254TOPS,且不支持直接運行語言模型。而英偉達Thor芯片由於存在設計缺陷和工程問題,實際算力與宣傳數據相比大幅縮水,其中Thor S、Thor U版本的算力約為700TOPS,而Thor Z基礎版算力約為300TOPS,對於端到端+VLM的算力需求而言,都依然緊張。
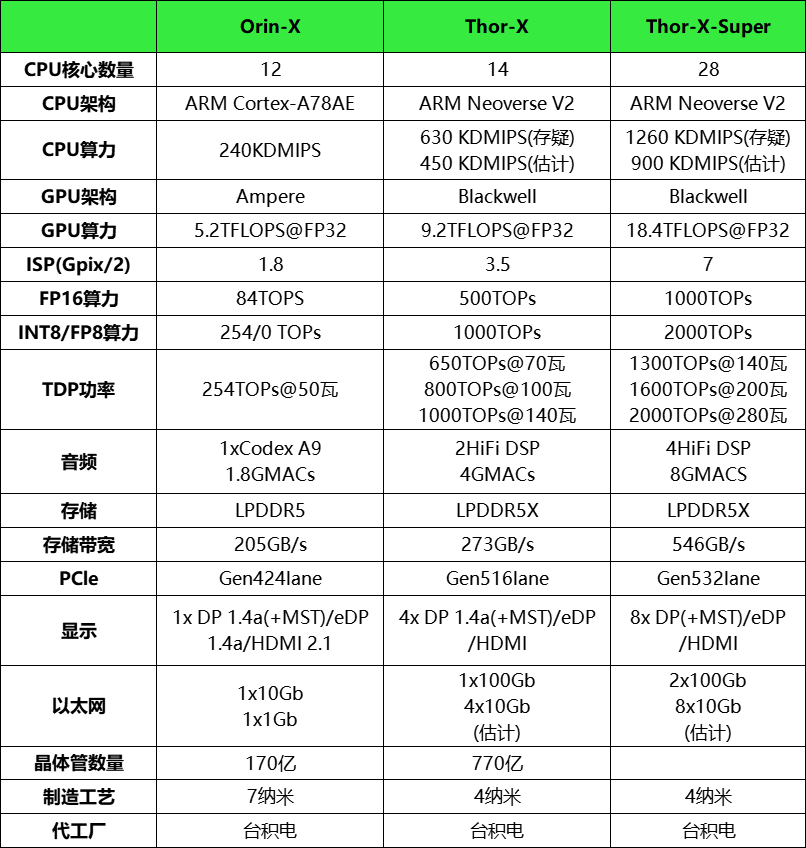
算力不足會導致大模型在推理過程中可能出現時延超過200毫秒的問題,而自動駕駛系統對於緊急制動等操作的響應時間要求是控制在100毫秒以內。
正因如此,目前行業內的芯片算力大戰正在逐漸升溫。除了英偉達,高通推出的8797艙駕一體芯片最高支持350TOPS算力,也已成為車企的選擇之一。
而車企,尤其是新勢力企業自研AI芯片已經逐漸成為潮流,其中,理想汽車自研的馬赫(原名「舒馬赫」)100大算力AI芯片,儘管尚未透露參數,但今年5月已經流片成功,計劃2026年量產。
特斯拉下一代全自動駕駛(FSD)芯片AI 5已進入量產階段,單顆算力或達到2500TOPS,較AI 4提升4~5倍,據稱最快在今年年底啓用。
此外,多模態對齊使得VLA需要依賴海量的標註數據來實現,然而在實際應用場景中,雨天反光、夜間弱光等並不常見的極端場景相關數據積累不足,將影響VLA的決策準確率及可靠性。所以,VLA要實現大規模落地,至少需要3~5年時間甚至更久。
VLA的大規模落地,本質是算法、算力、數據技術革命的交匯。短期(2025~2026年)具備VLA功能的車型將在高速公路、封閉園區等特定場景運行,典型應用包括自動泊車、高速領航等。
中期(2027~2029年),隨着算力達2000TOPS及以上新一代AI芯片量產,VLA將覆蓋城市道路全場景,平均無接管里程將顯著提升,或突破100公里,接管率或降至0.01次/公里以下。
長期(2030年後),將出現如光計算架構等專用AI芯片,並與腦機接口技術融合,或將使VLA實現類人駕駛的直覺決策能力,如準確預判行人突發行為的概率等。
多模態對齊成熟度、訓練效率提升、芯片能效比革命等一些關鍵因素,都可能在未來3~5年迎來新的突破,為VLA大規模落地提供更好支持。
然而,技術路線的驟然升級與競賽變奏,為還沒發力端到端的玩家設定了更高門檻,後發制人的機會更加稀少,距離智能輔助駕駛的決戰時刻已經越來越近。