
作者 | 陳駿達
編輯 | 李水青
智東西8月28日報道,近日,知名華人AI科學家,普林斯頓大學計算機科學系副教授,NLP小組負責人陳丹琦更新了自己Github主頁上的郵箱,郵箱後綴已經變為「thinkingmachines.ai」。
這是前OpenAI首席技術官Mira Murati、前安全副總裁翁荔(Lilian Weng)等人聯合創辦的明星AI獨角獸Thinking Machines Lab的郵箱域名,或許意味着陳丹琦已經加入這家公司。
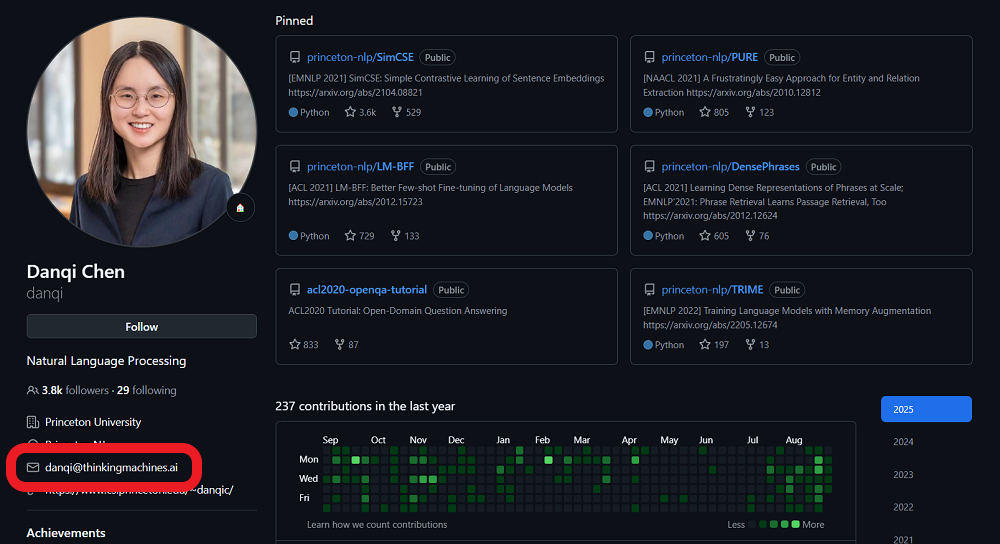
▲陳丹琦GitHub主頁
在開源模型平台Hugging Face上,陳丹琦也成為了Thinking Machines Lab團隊的成員之一。
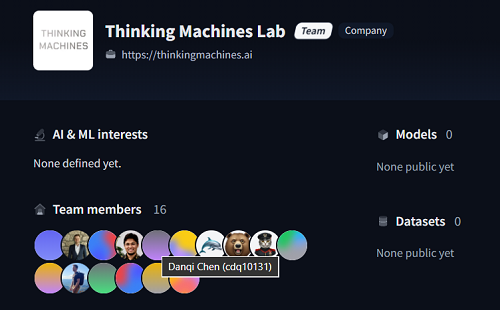
今年7月,啱啱成立5個月的Thinking Machines Lab完成了20億美元(約合人民幣143.46億元)的全球史上最大種子輪孖展,投後估值達120億美元(約合人民幣857.87億元)。這家創企陣容豪華,多位成員曾在OpenAI擔任要職,如OpenAI聯合創始人、前後訓練團隊負責人John Schulman,以及前GPT-4o-mini團隊負責人Kevin Lu等。
陳丹琦於2008年保送進入清華大學計算機科學實驗班(姚班),2012年獲計算機科學學士學位,隨後赴美國斯坦福大學攻讀博士,2018年獲計算機科學博士學位,導師為原斯坦福大學AI實驗室主任、NLP領域的領先專家Christopher Manning。
陳丹琦曾兩次獲得計算語言學領域頂會ACL的優秀論文獎,也曾獲得谷歌、亞馬遜、Meta、Adobe等機構給學者頒發的獎項。
2016年,陳丹琦作為第一作者,憑藉論文「A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task(《對CNN/每日郵報閱讀理解任務的全面評估》)」獲得ACL的優秀論文獎。
這篇論文幫助學界認識到,數據集本身的缺陷回影響模型評估的可信度,是理解早期機器閱讀理解研究侷限性的里程碑式論文。

▲陳丹琦作為第一作者的ACL 2016優秀論文
2022年,由她指導並署名的論文「Ditch the Gold Standard: Re-evaluating Conversational Question Answering(《拋棄黃金標準:對話式問答的再評估》)」再次獲得ACL優秀論文獎,這一論文的第一作者為Huihan Li。

▲陳丹琦參與指導的ACL 2022優秀論文
這篇論文提出應當重新審視評估標準,強調在對話問答場景中,單一「標準答案」不足以衡量模型真實的理解與對話能力。研究提供了更合理的評估方法,反映模型在多樣性、語境理解與對話適應性方面的表現。
在斯坦福大學期間,陳丹琦在句法解析、知識庫構建、問答和對話系統等領域做出了貢獻。
她2014年發表的論文「A Fast and Accurate Dependency Parser Using Neural Networks(《一種快速且準確的基於神經網絡的依存句法分析》)」是第一個成功的神經網絡依存句法分析模型,用於分析句子的語法結構。該工作為谷歌NLP團隊後續解析器的研究奠定了基礎。
陳丹琦2017年發表的論文「Reading Wikipedia to Answer Open-Domain Questions(《通過閱讀維基百科回答開放域問題》)」 開啓了將信息檢索與神經閱讀理解方法結合起來,進行開放域問答研究的方向。
2018年,陳丹琦完成了題為「Neural Reading Comprehension and Beyond(《神經閱讀理解及其拓展》)」的博士論文,長達156頁。
該論文重點研究閱讀理解和問答任務,在斯坦福大學正式公開後,迅速成為近十年來最受歡迎的博士論文之一。後來,它被中國的NLP研究者翻譯成中文,是該領域許多人必讀的著作。

▲陳丹琦博士論文封面
陳丹琦目前引用量最高的論文是「RoBERTa:A Robustly Optimized BERT Pretraining Approcah(《RoBERTa:一種穩健優化的 BERT 預訓練方法》)」,單篇引用量達3.6萬多次。這是她在FAIR期間參與的研究項目之一。
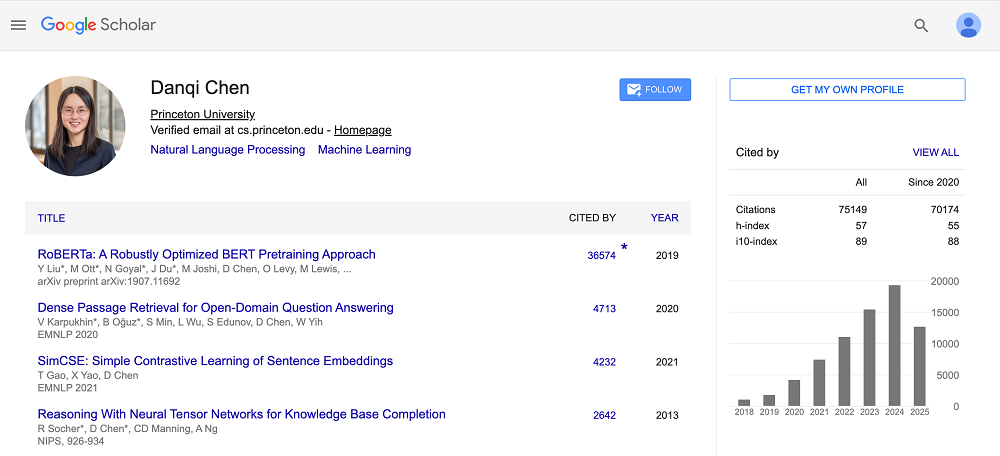
▲陳丹琦谷歌學術主頁(圖源:谷歌學術)
這篇論文讓NLP社區認識到,模型架構並非唯一突破口,訓練策略與數據規模同樣關鍵。此後許多大規模語言模型(如GPT-3等)都在數據與訓練策略上進行了類似優化。

▲陳丹琦參與的RoBERTa論文
從斯坦福大學畢業後,陳丹琦入職普林斯頓大學。她在普林斯頓大學的個人主頁顯示,她擔任該校NLP小組的共同負責人、語言與智能中心副主任,負責大模型相關的基礎研究。陳丹琦還是西雅圖Facebook AI研究院(FAIR)的訪問科學家。
陳丹琦的個人主頁顯示,她近期的學術興趣包括檢索、大預言模型訓練部署民主化等。
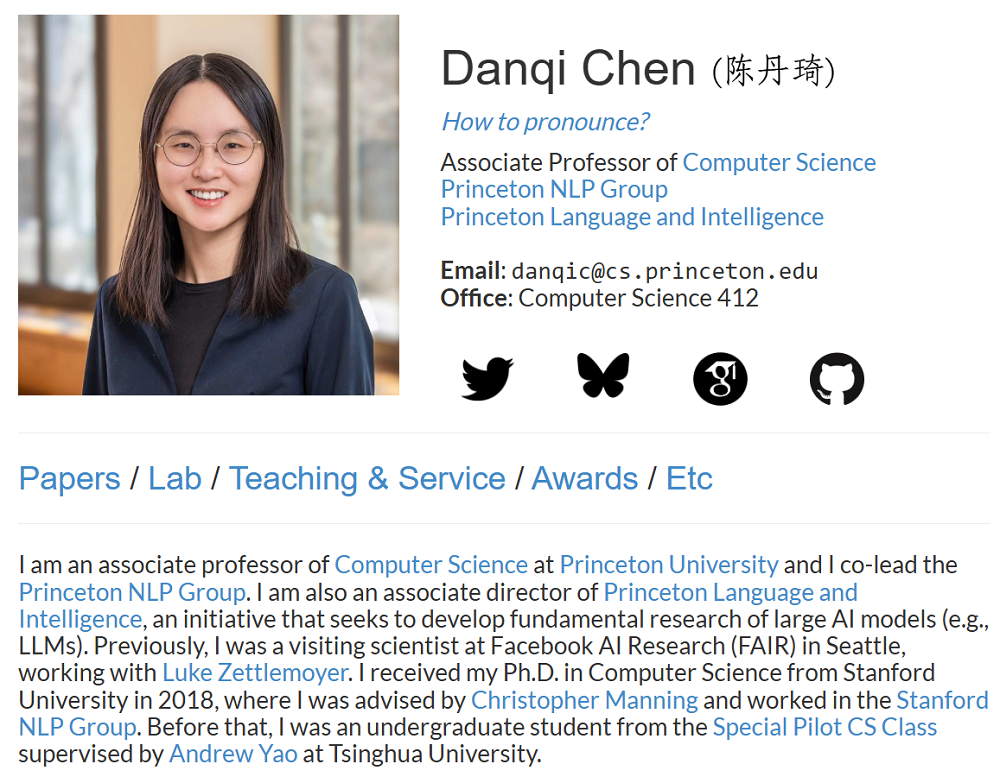
▲陳丹琦在普林斯頓大學的個人主頁
陳丹琦認為,檢索應該在下一代語言模型中發揮基礎性作用,以提高其真實性、適應性、可解釋性和可信度。她的團隊正在積極探索如何構建有效的檢索器,以及如何將檢索與語言模型相結合,以實現最佳權衡。
此外,陳丹琦還希望通過改進訓練方法、數據管理、優化到模型壓縮和下游適配等方式,實現大語言模型模型訓練和部署的民主化,尤其是在學術界。
結語:又一AI學者投身產業界
近年來,越來越多的AI學者選擇投身產業界。從斯坦福大學以人為本AI研究院主任李飛飛休假創業,到MIT教授、計算機視覺領域的領軍人物何愷明加盟DeepMind擔任傑出科學家,再到如今的陳丹琦,已經形成了一種趨勢。
產業界所掌握的海量資金與算力,對頂尖學者無疑具有強大吸引力。隨着高校與企業在研究資源上的差距逐漸拉大,學者們或許能夠在產業界找到更充分的條件去實現科研構想。我們期待這些學者們,在未來實現更多的創新突破。