
還記得之前大家熱議的神祕 AI 圖片編輯模型「nano-banana」嗎?
前幾天,我們在 LMArena 大語言模型競技場裏面用它進行了多輪測試,結果表現都非常出色。
現在,Google 終於揭開了它的神祕面紗。
▲ Google AI Studio 負責人 Logan Kilpatrick 發推文宣佈正式推出 Gemini 2.5 Flash Image 模型
Google 正式推出了其最先進的圖像生成與編輯模型——Gemini 2.5 Flash Image。
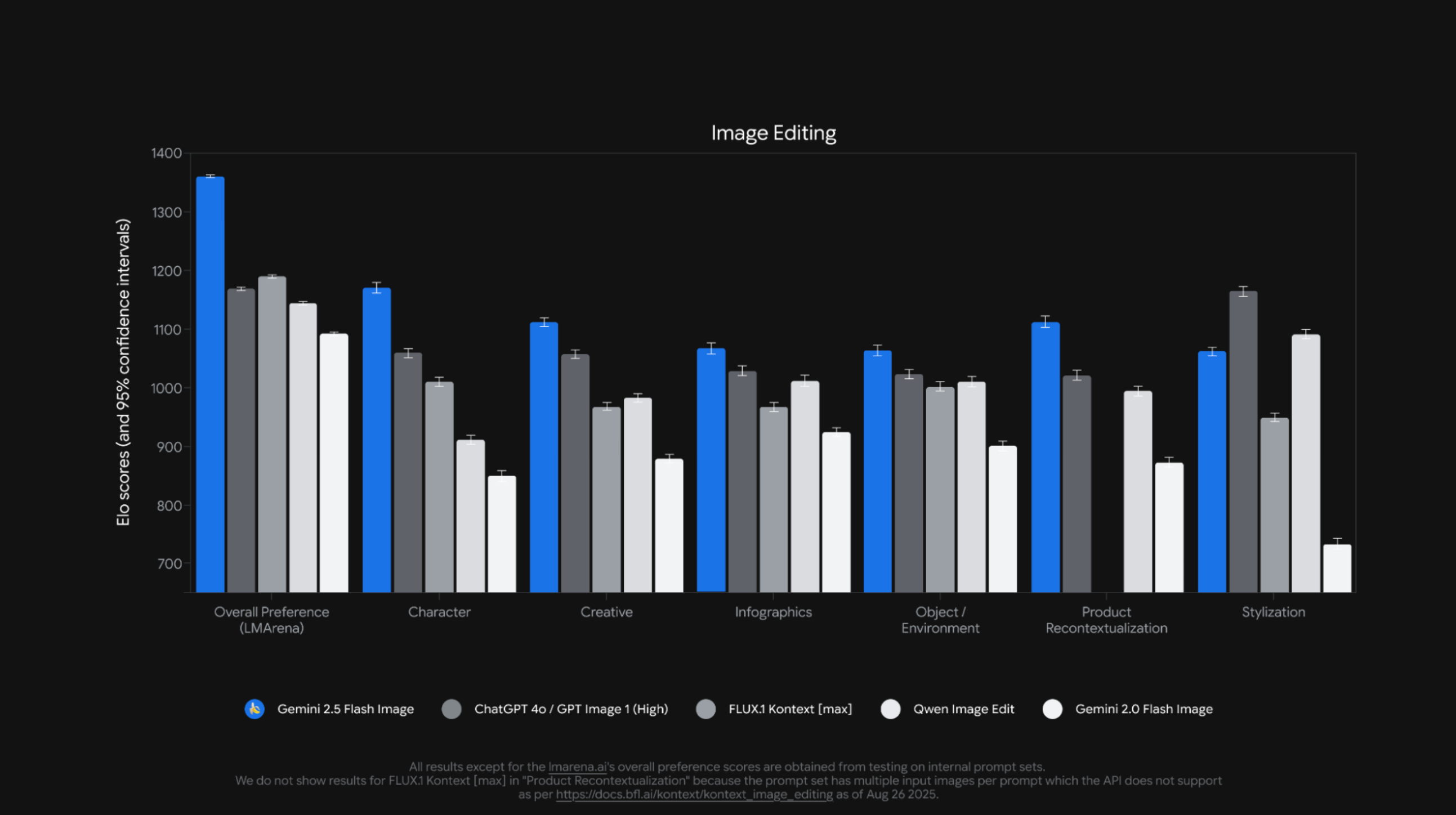
▲ 在多個排行榜上都是第一名,尤其是 LMArena 排行榜幾乎是遙遙領先
在更新的技術博客裏面,Google 提到此前的 Gemini 2.0 Flash 已經在圖像生成方面,以其低延遲和高性價比受到了開發者的喜愛,但用戶們也一直期待更高質量的圖像和更強大的創作控制功能。
Gemini 2.5 Flash Image 就是帶着一系列的重磅更新,來強勢回應這些期待。
和我們之前的體驗效果一樣,Gemini 2.5 Flash Image 的主要特點包括下面幾點
充分保持角色的一致性
基於提示的圖片編輯
利用 Gemini 的現實世界知識
多幅圖像融合
一張圖講一個故事:角色、場景隨心換
以往的 AI 繪圖工具,最大的痛點之一就是難以保持角色或物體的一致性。我們都曾經經歷過,想讓同一個角色出現在不同場景中,結果卻常常畫風突變,每一次生成都像換了個人。
Gemini 2.5 Flash Image 徹底解決了這個問題。

▲ 圖片來源 X@geminiap
它可以輕鬆地將同一個角色置於不同的環境中,或者從多個角度展示同一款產品,同時完美地保持其核心主體不變。Google 提到這對於需要講述連續故事、生成品牌系列資產或製作產品目錄的場景來說,無疑是一項革命性的功能。
為了展示這項能力,Google AI Studio 中還提供了一個模板應用,讓開發者可以快速上手,甚至在其基礎上進行二次開發。
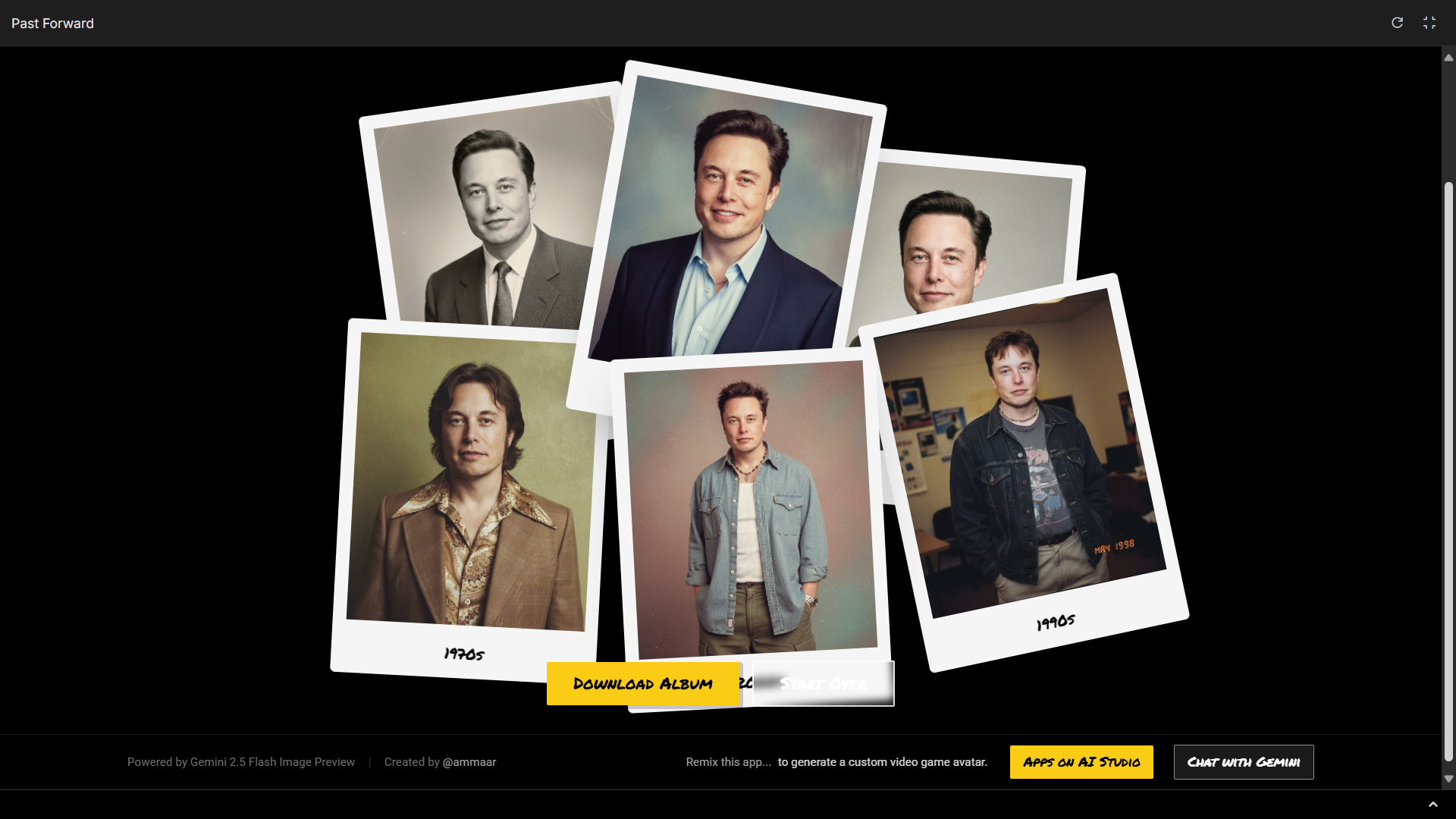
▲ 體驗地址:https://aistudio.google.com/apps/bundled/past_forward
在這個體驗項目裏,我們不需要輸入任何的提示詞,只用上傳一張人像照片,它就會調用這個最新的圖像模型,為我們生成從 1976 年 到 1990 年等各個年份的照片。
馬斯克看到自己這麼帥心裏一定在想,我的 Grok 也可以。
一句話修圖,用自然語言精準編輯
除了這種保持好高度一致的角色生成,精準的編輯也是一大亮點。Gemini 2.5 Flash Image 允許我們通過簡單的自然語言指令,對圖片進行精準的局部修改 。
像是模糊圖片背景、消除 T 恤上的污漬、從合照中移除某個人、改變人物的姿勢、為黑白照片上色……
這一切,都不再需要複雜繁瑣的專業軟件操作,我們只需要像聊天一樣,用一句話告訴 AI 想做什麼即可。
這跟我們之前在 LMArena 中的體驗是一樣的,像是我們也轉換過照片的風格,從黑白到彩色;以及對照片進行細微的調整等。

▲ 圖片來源 X@geminiapp
Google 同樣設計了一個簡單的應用,來方便我們更好的體驗這種基於提示詞的圖像編輯,但是完全媲美 PS 軟件的效果。
▲ 體驗地址:https://aistudio.google.com/apps/bundled/pixshop
不止會畫,更「懂」世界
過去的圖像模型雖然能創造出精美的圖片,但往往缺乏對現實世界的深層語義理解 。
Gemini 2.5 Flash Image 藉助 Gemini 強大的世界知識庫,讓圖像生成變得更加「智能」。
這意味着,模型不僅能看懂我們潦草手繪的圖表,還能回答與現實世界相關的問題,並一步到位地執行復雜的編輯指令。
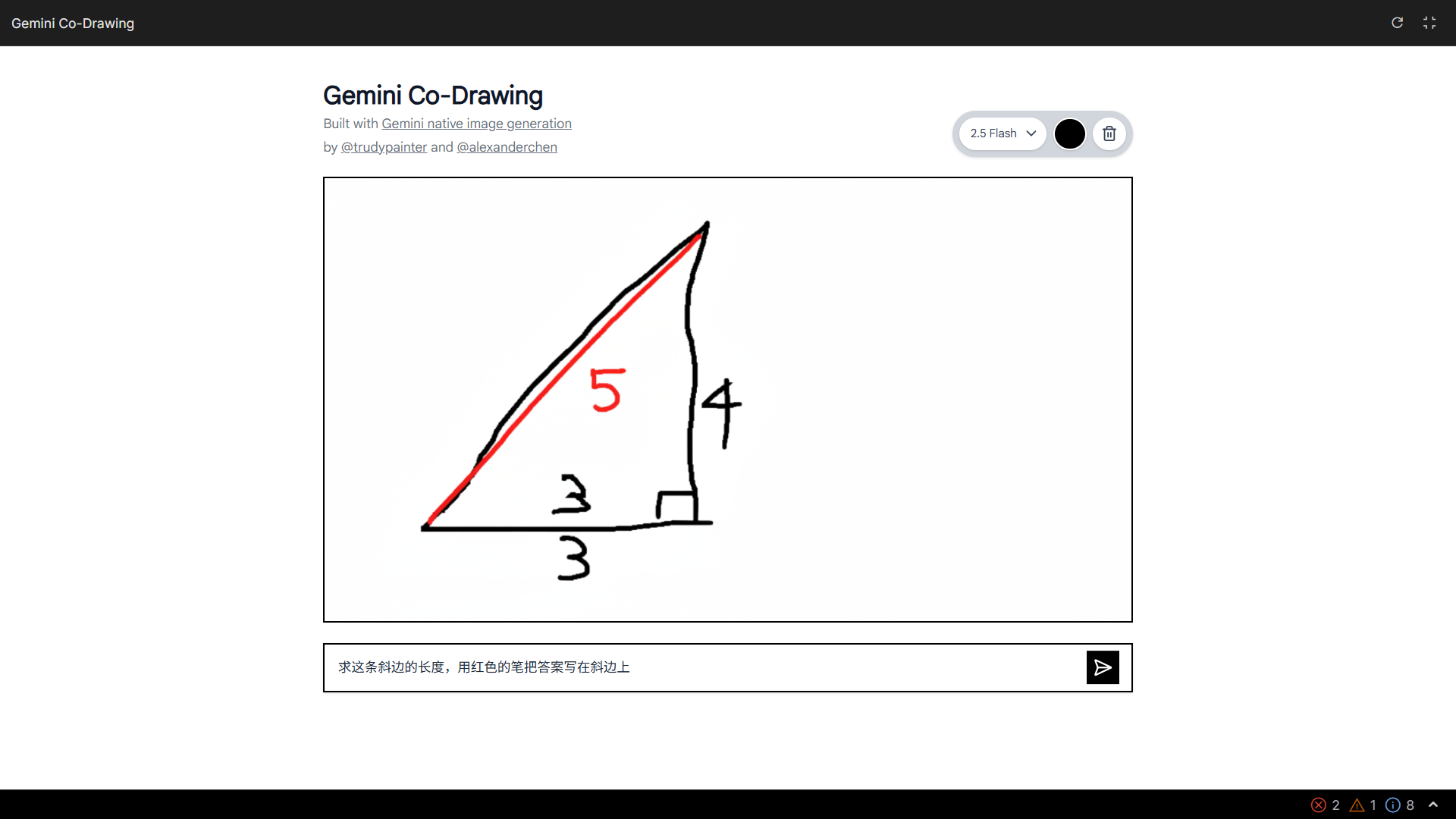
▲ 體驗地址:https://aistudio.google.com/apps/bundled/codrawing
聽起來很有多模態推理的感覺,Google 在 AI Studio 中展示了一個互動教育應用,將一塊簡單的畫布變成了可以答疑解惑的智能導師,我由衷的感嘆這個模型是真的厲害。
圖像融合:輕鬆實現「無縫」拼貼
新模型還帶來了一項酷炫的功能——多圖像融合。我們可以將一張圖片中的物體「放」進另一張圖片的場景裏,或者用一張圖的風格去渲染另一間屋子,整個過程只需一條提示指令就能完成。
同樣是 Google AI Studio 裏面的模板體驗應用,我們只需要把產品拖拽到新場景中,就可快速生成一張毫無違和感的、真實照片般的融合圖像。
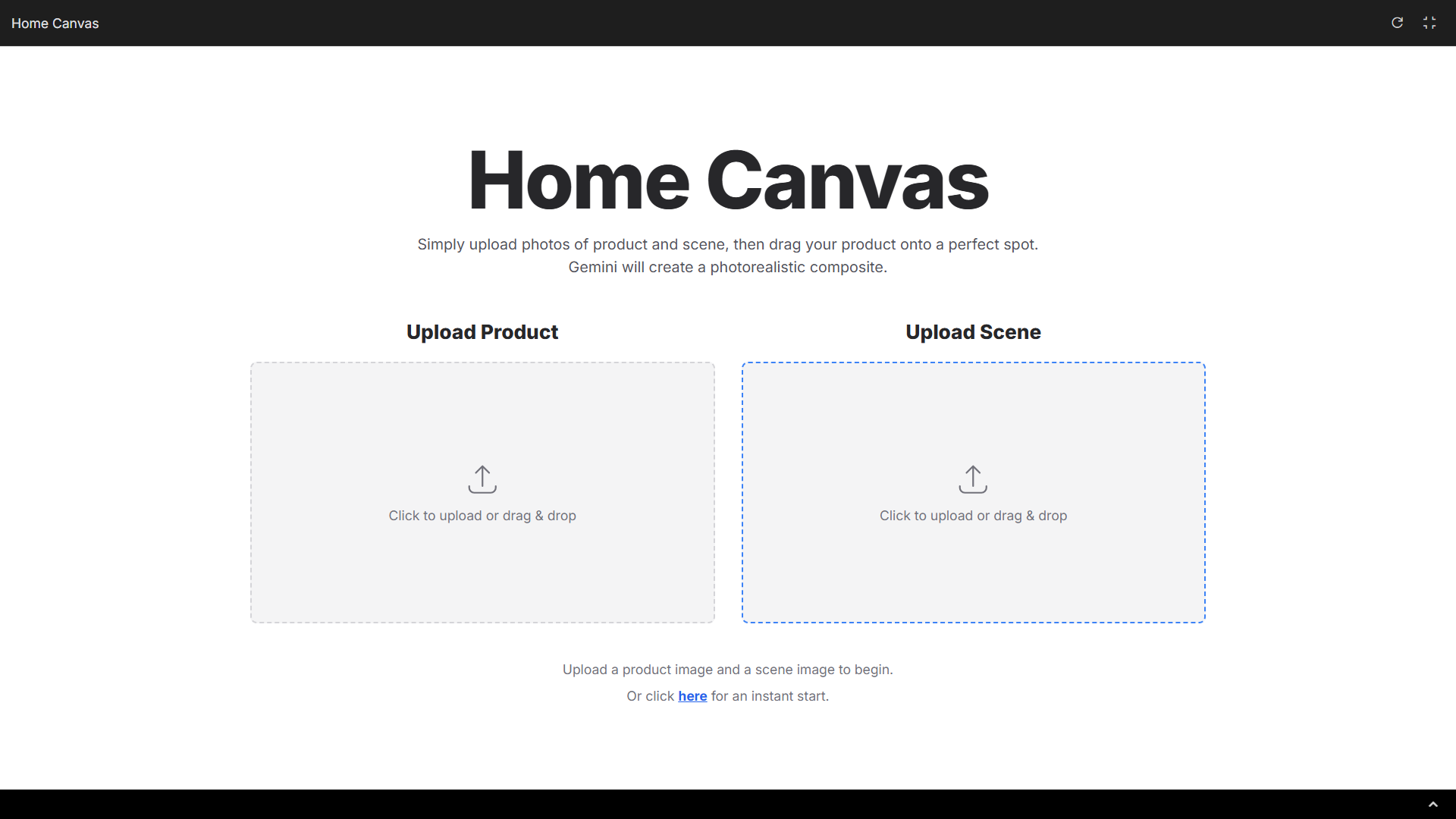
▲ 體驗地址:https://aistudio.google.com/apps/bundled/home_canvas
在這個模板應用裏面,我們甚至不需要輸入任何提示詞,可以直接拖動某個物體,到場景圖片上的具體位置,然後它會自動生成融合的圖片。
如何上手體驗?
除了我們在前面提到的那些 Google AI Studio 裏面的模板應用。
目前,Gemini 2.5 Flash Image 已經可以通過 Gemini APP、Gemini API、Google AI Studio 和 Vertex AI 進行訪問。
關於調用 API,具體的定價是每百萬輸出 token 30 美元,官方介紹,生成一張圖片大約消耗 1290 個輸出 token,也就是說,每張圖片的成本約為 0.039 美元,換算下來人民幣不到 3 毛錢。
值得一提的是,所有通過 Gemini 2.5 Flash Image 創建或編輯的圖片,都會包含 SynthID 隱形數字水印,以便識別其為 AI 生成或編輯的內容。
這跟前些天 Google 發布 Pixel 10 系列手機時,講到 AI 圖片編輯 Ask Photo 工具時,使用的 C2PA(內容來源和真實性聯盟) 內容憑證是一樣的。
最後,Google 還提到正在努力提升模型在長文本渲染、角色一致性穩定度和圖像細節真實性等方面的表現。
總而言之,Gemini 2.5 Flash Image 的發布,讓 AI 圖像工具從一個單純的繪畫玩具,向一個真正實用的創意與生產力工具邁出了一大步。
它不僅解決了我們過去使用 AI 繪圖時的諸多痛點,還帶來了更多有趣、實用的新玩法。
之前 4o 生圖能力出來,看到很多 App 開始主打用一張圖每天生成一首詩,還有像是拿到了今年 Apple 設計大獎的 CapWords,拍一張生活裏的照片,來實景學習一門新的語言……
我現在已經迫不及待想看到基於 Gemini 2.5 Flash Image 模型,又會有哪些新應用誕生了。