華人 95 後「叫板」谷歌搜索,聯合創辦 AI 搜索公司孖展 6 億多元!2021 年,美國哈佛大學華人校友 Jeffrey Wang 和室友威爾·布萊克(Will Bryk)創辦了一家名為 Exa 的 AI 搜索公司。經過幾年的發展,其於當地時間 2025 年 9 月 3 日宣佈已籌集到 8500 萬美元的 B 輪孖展(約等於 6.16 億人民幣),公司估值達到 7 億美元。本輪孖展由 Benchmark 領投,Lightspeed、英偉達和 YCombinator 參投。與此同時,Benchmark 的合夥人彼得·芬頓(Peter Fenton)也將加入 Exa 公司董事會。目前,該公司表示其已經為數千家公司提供網頁搜索服務,用戶涵蓋私募股權公司、諮詢公司以及 Cursor、Databricks、Notion 等科技公司。

圖 | Jeffrey Wang(來源:資料圖)
如前所述,該公司成立於 2021 年,可以說是在「AI 需要搜索引擎」、即在 ChatGPT 面世之前就已經成立。對此,該公司在官方新聞稿中寫道:「我們相信,世界需要一個比谷歌更好的搜索引擎,而我們能夠做到。」其形容自己的產品定位是:「谷歌搜索之於人類,正如我們之於 AI。」
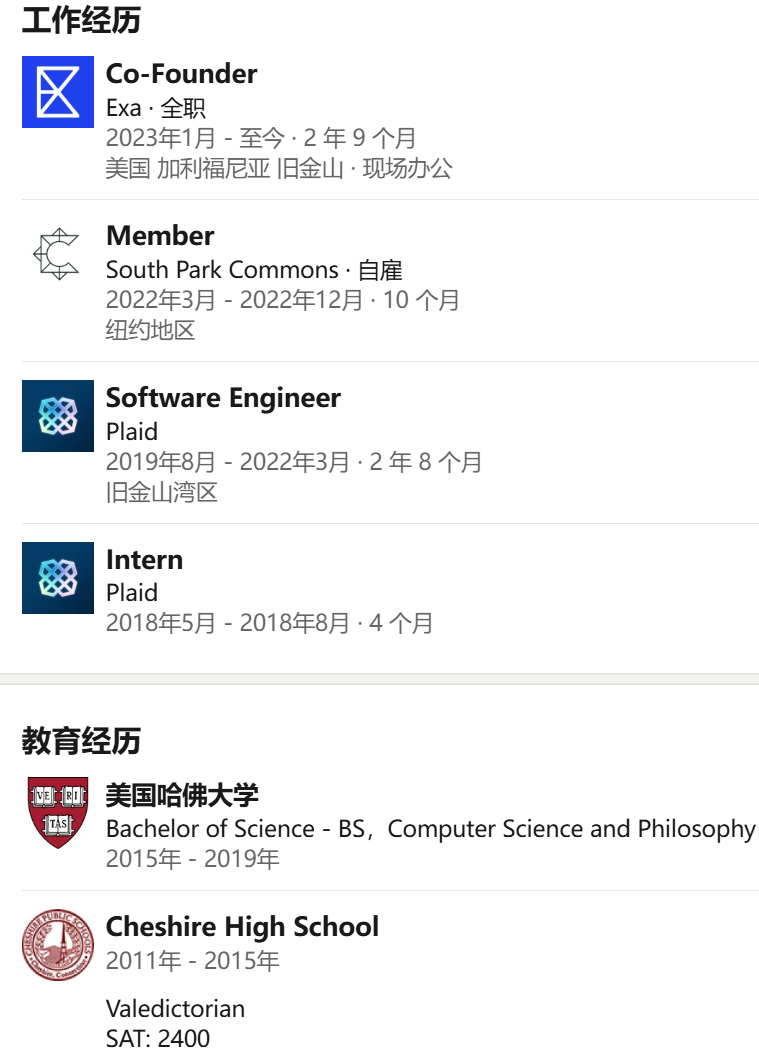
圖 | Jeffrey Wang 的學習經歷和工作經歷(來源:資料圖)
公司成立之後,Jeffrey Wang 等人先是購買了一個 GPU 集羣,藉此構建出一個大規模的索引系統,並嘗試了多個新型網絡搜索技術。旨在開發一個讓用戶能以「谷歌無法做到的方式」來控制網絡的搜索引擎。比如,用戶可以提出這樣一個搜索請求:「給我找出所有擁有博客的在紐約的機器學習工程師,並按照經驗年限排序。」
2022 年 11 月,該公司推出了第一款搜索引擎產品。兩周之後,ChatGPT 橫空出世。很快,該公司就收到訪問器搜索引擎 API 的請求。之所以會受到這些請求是因為,當時很多公司都開始研發 AI 應用,而這需要先從網絡上獲取信息。這時,Jeffrey Wang 等人意識到 AI 也需要網絡搜索。其還意識到,AI 的網絡搜索需求頻率很快就會高出人類。
那麼,什麼是 AI 搜索引擎?和人類一樣的是,AI 的「大腦」中也不可能存儲世界上所有的信息。無論是了解新聞、代碼、論文還是公司數據,它都需要通過網絡搜索來獲取最新、最全面的信息。但是,AI 畢竟和人類有着本質區別,因此 AI 需要一種新型的搜索引擎。「搜索引擎」這個詞語大家並不陌生,人類使用的搜索引擎早在幾十年前就已誕生。但是,該公司表示其和公司名字同名的產品 Exa 是一款專門為 AI 設計的搜索引擎。
它具有六個專有特點。
第一個特點是能幫助 AI 獲取高質量的知識。AI 要搜索的是最高質量的知識,而不是 SEO 內容或廣告內容,否則 AI 就會變得「輸入的是垃圾,輸出的也是垃圾」。為此,Exa 的排名算法能對高質量知識進行優化。由於這款搜索引擎不會接受外部廣告投放,因此不會採取任何不正當的激勵措施,故能為 AI 儘可能提供高質量的搜索。
第二個特點是其能讓 AI 獲得所有需要的內容。AI 所需要的不僅是一篇文章的鏈接和標題,而是需要儘可能地獲得每個結果的信息。而 Exa 能為每個信息都提供完整的頁面內容,以便 AI 處理所有必要的信息。
第三個特點是更快速。相比人類,AI 需要更快的搜索速度。與此同時,AI 語音助手等 AI 產品對於延遲非常敏感,甚至說每一毫秒都至關重要。AI 在工作時通常會在單個請求中調用多個工具,而搜索引擎只是其調用的工具之一。那麼,在調用多個工具的時候就會積累延遲。Jeffrey Wang 等人認為,要想構建全球最快的搜索 API,就不能成為包裝器,即不能在搜索 API 的底層封裝谷歌,因為這意味着服務器集羣中的瀏覽器會接受用戶查詢,並通過在谷歌搜索中進行處理來提供結果。而這需要超過 700 毫秒的中位數延遲(P50,The 50th Percentile Latency),因此其指出任何封裝谷歌的搜索 API 的 P50 時間至少為 700 毫秒。AI Agent 會進行大量的搜索調用,如果一個 Deep Research 代理進行 50 次搜索調用,每當每次調用的速度快 200 毫秒,那麼就能為真人用戶節省 10 秒時間。為了構建「全球最快的搜索 API」,Jeffrey Wang 等人爬取了網絡數據,並訓練模型進行搜索,以及開發了自己的矢量數據庫。通過掌控整個技術棧的每個部分,從而能夠緩解延遲。通過此,其構建了一款名為 Exa Fast 的搜索 API,Jeffrey Wang 等人表示其速度低於 450 毫秒。在一項實驗中,他們針對美國北加州數據中心的數千次隨機查詢進行了基準測試,結果發現其網絡延遲約為 50 毫秒。
(來源:資料圖)
第四個特點是高計算。對於 AI 來說它並不關心延遲,而是只想進行最全面的搜索,對於那些異步應用程序來說更是如此,為此 Jeffrey Wang 等人打造了一款名為 Websets 的高計算搜索產品,並稱其是「迄今為止全球最全面的搜索引擎」,能讓 AI 獲取海量的人員信息、公司信息或其他信息。
第五個特點是可定製。由於每個 AI 應用都有特定的用例,因此如能針對特定應用程序進行搜索定製,效果無疑會更好。而 Exa 這一 AI 搜索引擎基於定製化的理念,可以做到通過排除數千個域名來獲取數百個結果,同時也能創建自定義分類器以便在每次搜索時運行。
第六個特點是零數據保留。來自企業的查詢數據往往非常敏感,因此企業更傾向於擁有具備零數據保留特點的搜索 API,這意味着 AI 的查詢內容永遠不會被存儲在任何地方。對於實現完全的數據隱私保護的企業來說,零數據處理是一個黃金標準。對於搜索服務商來說,要想提供零數據處理,無論在主服務器還是子處理器中,都絕對不能存儲用戶的查詢數據。Jeffrey Wang 等人在一篇博文中指出,大多數搜索提供商實際上無法提供零數據處理,並指出這也是搜索領域中一個鮮為人知的祕密。之所以會出現這種情況,是因為絕大多數搜索服務商都會在後台抓取谷歌數據。當查詢達到搜索服務商時,查詢會被路由到全球某個在瀏覽器中運行谷歌搜索的匿名服務器,然後谷歌搜索結果會被髮回給搜索服務提供商。由於谷歌搜索是一個基於用戶查詢進行訓練的消費級搜索引擎,所以它並沒有零數據處理。因此,任何以子處理器身份在後台抓取谷歌搜索數據的搜索服務提供商都無法擁有零數據處理能力。而由於 Exa 是從頭開始構建的搜索引擎,因此該公司表示它可以為所有產品端點提供零數據保留。為了煉就這一能力,其通過爬取網絡數據,訓練了專門的 AI 搜索引擎,並通過設計海量數據庫來為模型提供服務。這讓其不僅能為客戶提供準確的搜索結果,還能確保每個查詢都保留在零數據處理系統中,當搜索結束之後查詢數據就會被刪除。
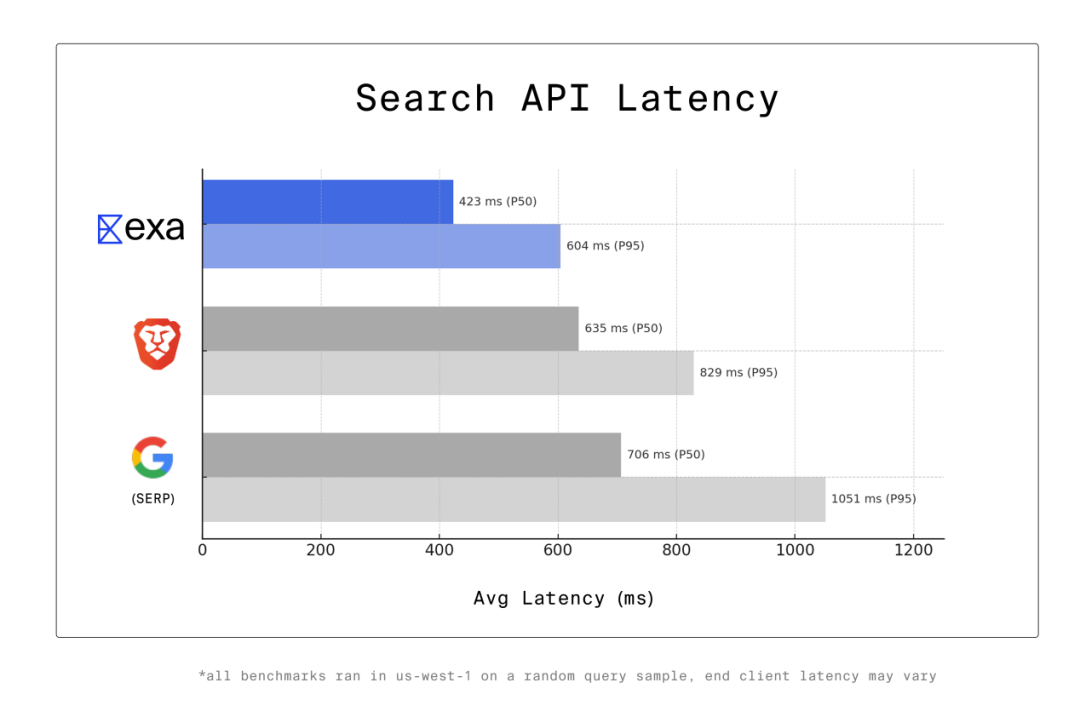
(來源:資料圖)
而在未來,Exa 還有着更加遼闊的野望,它希望通過擴大索引能力和處理能力,以便能夠收集全球範圍內的絕大多數信息。同時,它還計劃建設一個比當前大出 5 倍的 GPU 集羣,以便開發出來能將全球信息組織起來的新技術,最終它的目標是超越谷歌搜索。

(來源:資料圖)
資料顯示,作為 Exa 公司聯合創始人的 Jeffrey Wang 會說中文,如前所述其本科畢業於美國哈佛大學。畢業之後他曾在美國金融科技公司 Plaid 工作了三年,在那裏他主要負責構建數據和網絡基礎設施。後來,他和大學室友威爾·布萊克(Will Bryk)聯合創辦了 Exa 公司,並由布萊克擔任 CEO。

(來源:資料圖)
與此同時,Exa 還有多位華人技術人員。比如,畢業於哈佛大學的 Benjamin Chen、畢業於清華大學姚班的 Hubert Yuan、畢業於美國卡內基梅隆大學的 Zixi An、畢業於美國加州大學伯克利分校的 Felicia M. Tang、博士畢業於美國康奈爾大學的 Benjamin Y Chan 等。

圖 | 該公司部分員工(來源:資料圖)
未來,Exa 能否實現超越谷歌的夢想?還需讓時間來證明一切。