
編譯 | 陳駿達
編輯 | 雲鵬
讓AI翻譯OG、砍一刀等新詞、網梗,會是什麼畫面?
DeepSeek給出的答案是這樣的:

不僅略顯生硬,還有點驚悚,很可能讓外國友人誤解:「砍一刀」難道是一種針對外國人的暴力活動嗎?
智東西9月1日報道,今天,騰訊混元開源其首批翻譯模型:Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B,給機器翻譯提供了一個新選項。這一模型可對33個語種進行互譯,並處理粵語、維吾爾語、藏語、哈薩克語、蒙古語等少數民族語言或方言。
這一模型還能精準理解網絡用語、遊戲用語等,結合語境進行意譯。對於「砍一刀」,Hunyuan-MT-7B給出瞭如下翻譯。雖然有點喪失了「砍一刀」的神韻,但準確傳達了大義,至少不會讓外國讀者感到驚悚了。
在多個具有代表性的機器翻譯基準測試中,Hunyuan-MT系列模型的表現超越谷歌翻譯等專用翻譯系統和Seed-X-PPO-7B、Tower-Plus-9B等同尺寸翻譯模型,還打敗了參數數十倍於它的DeepSeek-V3等模型,在翻譯場景的表現接近Claude-Sonnet-4。
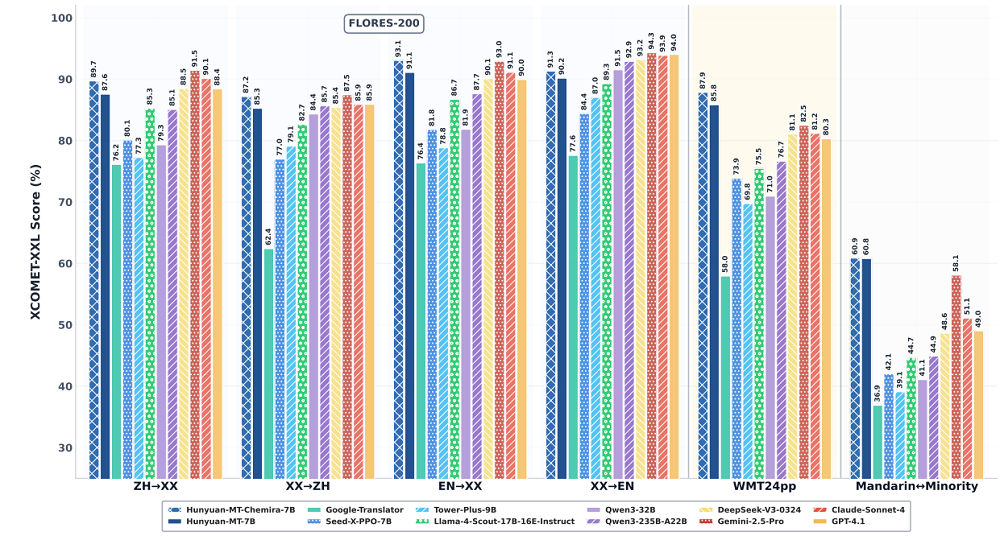
面向國內用戶,Hunyuan-MT重點優化了中文與多種少數民族語言之間的雙向翻譯,採用了針對性的數據整理和優化措施,顯著提升了模型在資源匱乏環境下的翻譯效果。
在ACL(國際計算語言學協會)主辦的WMT 2025(世界機器翻譯大會)通用機器翻譯任務中,Hunyuan-MT-7B在31對語言組合的互譯中,獲得了30項第一。
值得注意的是,這些語言組合既包括中文、英語和日語等資源豐富的語言,也包括捷克語、馬拉地語、愛沙尼亞語和冰島語等資源匱乏的語言。
騰訊混元還打造了翻譯集成模型Hunyuan-MT-Chimera-7B。這一模型使用了「弱到強」強化學習方法,在推理階段能夠整合來自不同系統的多條候選譯文,生成質量超越單一候選譯文的最終輸出。
騰訊混元已將Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B上傳至開源託管平台Hugging Face和GitHub,並基於騰訊自研的AngelSlim大模型壓縮工具對Hunyuan-MT-7B進行FP8量化壓縮,推理性能進一步提升30%。7B的模型尺寸,在不少消費級GPU都能實現流暢運行。
Hunyuan-MT-7B已經在騰訊混元AI Studio中上線,開發者可在這一平台體驗模型,並通過API接口調用模型,但Hunyuan-MT-Chimera-7B尚未上線。
智東西第一時間對Hunyuan-MT-7B模型的能力進行了體驗,並梳理了技術報告中有關這一系列模型的更多細節。
體驗地址:https://hunyuan.tencent.com/modelSquare/home/list
Github: https://github.com/Tencent-Hunyuan/Hunyuan-MT/
HugginFace: https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
AngelSlim壓縮工具:https://github.com/Tencent/AngelSlim
一、精準翻譯遊戲名、網絡梗,但在專業翻譯考試題上翻車了
在技術報告內的多個翻譯案例中,Hunyuan-MT系列模型展現出較強的理解力。
Hunyuan-MT-7B能正確將「小紅薯」理解為社交平台「REDnote」,並將「砍一刀」理解為拼多多的降價機制。而谷歌翻譯僅能直譯,並給出錯誤的譯文(分別為「sweet potatoes」和「cuts」)。

對於英文俚語表達,Hunyuan-MT-7B能準確捕捉慣用意義,例如將「You are killing me」翻譯為表達「好笑、逗趣」的含義,而非字面上的「你要殺我」;谷歌翻譯則未能準確處理。

智東西的實測也驗證了Hunyuan-MT-7B的這一能力。在翻譯「He’s killing it」時,模型不會直接翻譯原文,而是理解了這是一個口語化的表達,並翻譯為「他表現得非常出色」。

此外,該模型在專業術語翻譯上也表現出更強能力,能夠正確翻譯醫學術語,如「blood disorders」和「uric acid kidney stones」,還能成功實現跨語言的完整地址翻譯,而谷歌翻譯往往保持原文不變。

這些例子表明,Hunyuan-MT-7B在語言細微差別、文化背景和領域知識上具有更深刻的理解,從而能夠生成比傳統翻譯系統更準確、更自然的譯文。
對於歐洲語言(意大利語、德語)和亞洲語言(韓語、波斯語),Hunyuan-MT-7B能夠生成更準確、自然的譯文,正確理解上下文特定術語,避免直譯錯誤。
在少數民族語言(如哈薩克語、藏語等)的翻譯中,Hunyuan-MT-7B能夠準確翻譯完整句子,而谷歌翻譯往往輸出無意義的內容(例如哈薩克語)。
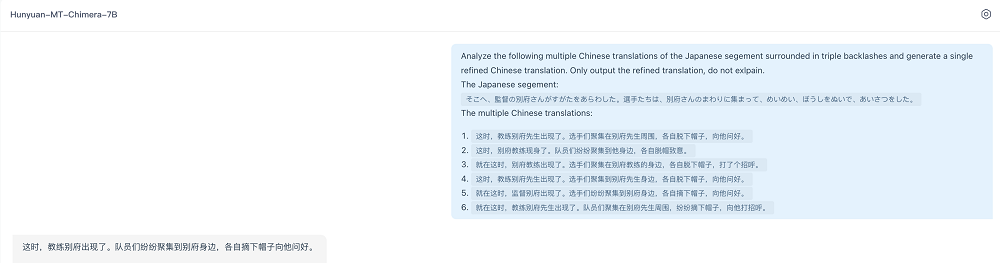
Hunyuan-MT-Chimera-7B能在遊戲等場景,利用其增強模塊提升對上下文、口語表達及領域術語的理解,使譯文更加準確自然。
例如,其他模型未能將縮寫「d2」識別為遊戲《暗黑破壞神 II》,或將「make a game」錯誤理解為遊戲開發,而Hunyuan-MT-Chimera-7B正確識別了遊戲語境及交易術語。

在處理非正式語言時,它能夠恰當地翻譯用於強調的髒話,而非直譯為粗俗用語,顯示出更好的語用理解。

此外,它還展現了更強的上下文感知能力,將「穿過」翻譯為「sped through」,而非含義不當的「drove through」(暗示衝入人群)。

這些案例表明,Chimera增強模塊能夠提升對上下文、口語表達及領域術語的理解,使譯文更加準確自然。
智東西讓Hunyuan-MT-7B翻譯了兩道2025年全國翻譯專業資格(水平)考試(CATTI)真題,這一考試側重對時政、熱點的考察。
在英譯中任務上,Hunyuan-MT-7B準確地處理了專有名詞、術語的翻譯,但是在句式選擇上仍然受到英文原文的影響,讀起來並不順暢,只能說達到了入門級譯者的水平。
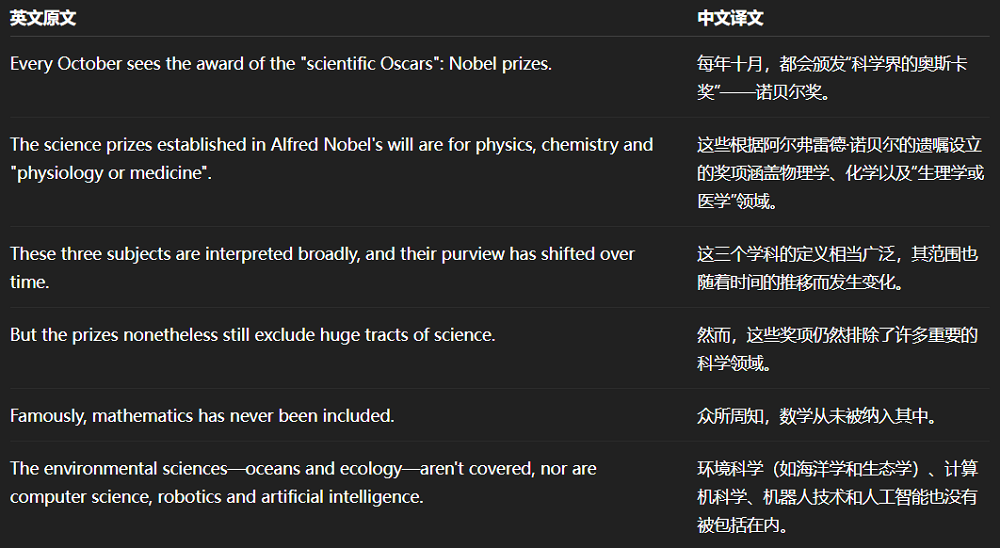
在處理中譯英任務時,Hunyuan-MT-7B對關鍵詞的翻譯基本準確,但是將最重要的會議名稱翻錯了,會議全名中有一個單詞出錯,還將「消博會」的縮寫寫成了「進博會」的縮寫CIIE,屬於較為嚴重的錯誤。這可能是因為模型參數量較小,對此類表達積累不足。

二、預訓練數據包含上百種語言,Base模型已成為同量級SOTA
為什麼要打造Hunyuan-MT?騰訊混元在技術報告中分享了當前機器翻譯模型存在的幾大問題。
雖然如今的大模型已經能在特定語言對上交付超越人類專家譯者的疑問,但機器翻譯系統和大模型在處理網絡新詞、俚語、專業術語以及地名等非書面語言時,翻譯質量仍然有待提升。
同時,對低資源語言(缺乏相關語料的語言)和少數民族語言機器翻譯的研究嚴重匱乏,而中國少數民族語言與普通話之間的翻譯問題尤為突出。
要解決這些問題,不僅需要強大的語言理解能力,還必須能夠生成在文化上契合、表達上地道的譯文,從而超越逐詞對應的直譯。
為訓練這一機器翻譯模型,騰訊混元團隊在通用預訓練階段聯合訓練了中文、英文以及小語種、少數民族語言的數據。
其中,非中文、英文的少數語種數據集規模達1.3萬億個token,涵蓋來自多種來源的112種非中英文語言及方言。
這些數據並不會被一股腦地輸入模型,而是通過多語種數據質量評估模型評估其知識價值、真實性與寫作風格後,得到加權得分,並根據數據源的特徵,動態調整質量評估的權重。例如,在圖書類與專業網站內容中,騰訊混元團隊會優先選擇知識價值得分較高的文本。
同時,為了確保訓練數據的多樣性,騰訊混元團隊還建立了三個數據標註體系,分別為學科標註體系、行業標註體系(24類)和主題標註體系(24類)。
這一體系可用於篩選和比例調節,例如平衡學科分佈,確保跨行業的內容多樣性,或是過濾廣告內容等。
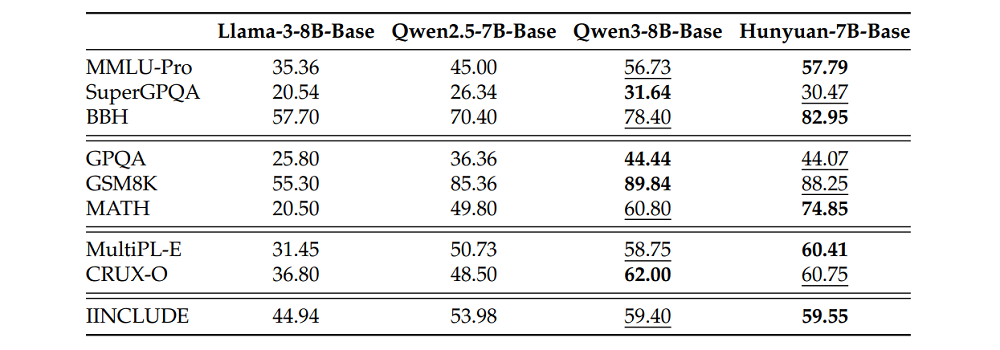
在採用上述數據訓練後,騰訊混元團隊得到了Hunyuan-7B-Base模型,這一模型在通用知識、推理、數學、科學知識、編程和多語言能力上均實現同尺寸模型中的較好表現,在9項基準測試中獲得5個SOTA。
三、針對機器翻譯「定向預訓練」,翻譯能力進一步提升
打造Hunyuan-7B-Base的環節被稱為「通用預訓練」,接下來,模型還需針對機器翻譯任務進行「定向預訓練」。
在這一階段,騰訊混元團隊使用了單語語料與雙語語料的混合數據,這些數據主要來自於開源數據集和公開的平行語料庫(收錄雙語對照數據的數據庫)。之後,這些數據還經歷了語言識別、去重、質量過濾等環節。
為確定合適的數據混合比例,該團隊借鑑了RegMix方法,先在小規模模型上進行實驗,擬合採樣比例與訓練損失之間的函數關係,再通過函數模擬,找到使預測損失最小的比例,並將該比例用於最終翻譯模型的機器翻譯定向預訓練階段。
為防止災難性遺忘(模型學新忘舊),騰訊混元團隊在訓練中保留了20%的原始通用預訓練語料。同時,他們還採用了先升溫至初始預訓練的峯值學習率,再逐步衰減至最小值學習率的調度策略。
為全面評估模型的多語種翻譯能力,Hunyuan-7B★(★代表經過機器翻譯定向預訓練)在業界常用的翻譯能力測評數據集FLORES-200、WMT24pp等和漢語-少數民族語言互譯測試集上進行了測試。
結果顯示,無論是在客觀指標和多語種專家的主觀測評中,這一模型的表現都超過了同尺寸模型,和機器翻譯定向預訓練前的Hunyuan-7B相比,也有明顯提升。

四、採用三種後訓練方法,能融合6種翻譯結果
預訓練之後,騰訊混元團隊通過監督微調(SFT)、強化學習(RL)和「弱到強」強化學習(Weak-to-Strong RL),進一步提升模型翻譯能力。
Hunyuan-7B-Base在SFT環節的第一階段,使用了超過300萬對平行語料,涵蓋了公開數據集、人工翻譯、DeepSeek-V3-0324生成的合成語料,以及精選的指令調優數據。
進入第二階段,Hunyuan-7B-Base的優化重點是更高的精度。騰訊混元團隊選取了約26.8萬對更高保真的語料,經過更加嚴格的篩選與驗證,部分樣本由人工複覈,保證了數據的可靠性。
藉助這一雙階段的微調策略,模型的翻譯表現實現提升,特別是在少數民族語言與漢語的互譯任務中展現出明顯優勢。
RL階段,Hunyuan-7B-Base採用了常見的GRPO算法,並設計了多元化的獎勵函數。
這一獎勵函數包括質量感知獎勵、術語感知獎勵和重複懲罰。
其中,質量感知獎勵包含兩個獎勵信號,一個由客觀機器翻譯質量評估模型XComet-XXL提供,這一模型不像傳統的BLEU評估模型一樣依賴人工譯文,而是直接分析翻譯文本的流暢性、準確性和自然度等特徵。
另一個獎勵信號來自DeepSeek-V3-0324的評分。V3在這裏扮演了類似人工翻譯評審員的角色,並借用了GEMBA翻譯質量評估框架裏的提示詞,讓V3對翻譯結果的語義準確性、語法正確性等進行評分。
能否對關鍵術語進行準確翻譯,也會影響譯文質量。騰訊混元團隊引入基於詞對齊的獎勵機制,通過詞對齊工具提取關鍵術語和信息,計算機器譯文和參考譯文的重合率,重合率高獎勵就越大。
該團隊觀察到,模型在RL後期容易生成重複內容,甚至可能導致訓練崩潰。因此,他們設計了重複檢測機制,一旦發現重複模式則施加懲罰,以保持輸出的多樣性和訓練的穩定性。
騰訊混元團隊還提出了「弱到強」強化學習方法,模型會生成多個翻譯結果,並利用基於Hunyuan-MT-7B的融合模型通過GRPO聚合這些輸出。獎勵函數由XComet-XXL評分、DeepSeek-V3-0324評分和重複懲罰項組成。這種獎勵機制能夠全面評估翻譯質量,同時避免冗餘輸出。最終,Hunyuan-MT-7B-Chimera模型誕生了。
系統提示詞顯示,Hunyuan-MT-7B-Chimera會分析六個不同翻譯結果,生成經過統一優化的最終翻譯結果。

該方法利用多種翻譯之間的互補性,從而顯著提升翻譯質量。
基準測試結果顯示,Hunyuan-MT-7B和Hunyuan-MT-Chimera-7B在XCOMET-XXL和CometKiwi兩項指標上均顯著優於大多數基線模型,顯示出穩定而顯著的改進。
在谷歌等企業推出的WMT24pp基準上,Hunyuan-MT-7B的XCOMET-XXL得分為0.8585,超越了所有基線模型,包括Gemini-2.5-Pro和Claude-Sonnet-4等超大模型。
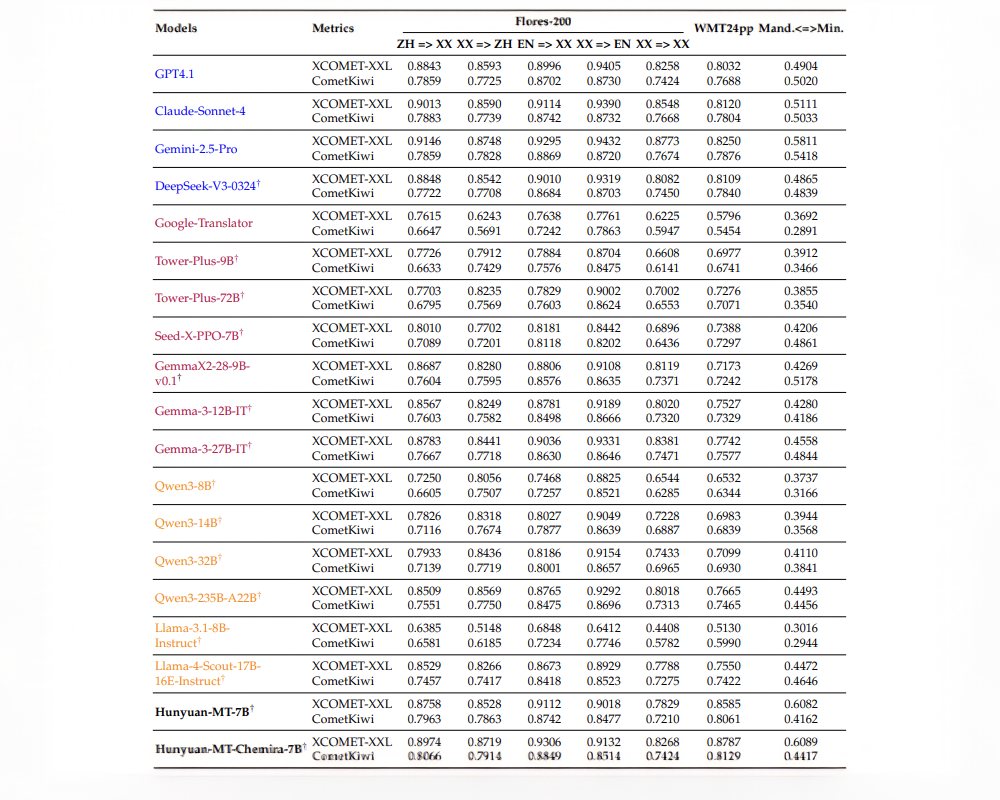
在漢語與少數民族語言的翻譯任務中,Hunyuan-MT-7B(得分0.6082)和Hunyuan-MT-Chimera-7B(得分0.6089)高於所有競品,其中最接近的Gemini-2.5-Pro為0.5811。
結語:生成式AI給機翻帶來新解法,多家大廠已下注
對騰訊、字節、阿里等企業而言,機器翻譯模型有其現實價值:在展開跨國業務的過程中,高質量的機器翻譯模型可以替代或者加速部分人工翻譯流程,實現降本增效。
在生成式AI時代,機器翻譯這一計算語言學的經典話題又迎來了新的解決方案,有越來越多的廠商使用Transformer等新一代模型架構打造機器翻譯模型。未來,我們或許能看到更為成熟、強大的翻譯模型投入使用,