
新智元報道
編輯:KingHZ 好睏
【新智元導讀】OpenAI重磅結構調整:ChatGPT「模型行為」團隊併入Post-Training,前負責人Joanne Jang負責新成立的OAI Labs。而背後原因,可能是他們最近的新發現:評測在獎勵模型「幻覺」,模型被逼成「應試選手」。一次組織重組+評測範式重構,也許正在改寫AI的能力邊界與產品形態。
就在啱啱,OpenAI決定——重組ChatGPT「個性」研究團隊!
這個約14人的小組,規模雖小但責任重大——他們要負責讓GPT模型知道該怎麼和人類進行交互。
根據內部消息,模型行為團隊(Model Behavior team)將直接併入後訓練團隊(Post-Training team),並向後訓練負責人Max Schwarzer彙報。

團隊前負責人Joanne Jang,從頭開始新的實驗室「OAI Labs」——為人類與AI的協作方式,發明並構建新的交互界面原型。

與此同時,OpenAI還非常罕見地發了一篇論文揭祕——讓AI產生「幻覺」的罪魁禍首,就是我們自己!
整個行業為了追求高分排行榜而設計的「應試」評估體系,迫使AI寧願去猜測答案,也不願誠實地說出「我不知道」。

論文地址:https://openai.com/index/why-language-models-hallucinate/

超現實的一天
模型行為團隊幾乎參與了GPT-4後的全部模型研發,包括GPT-4o、GPT-4.5以及GPT-5。
上周,作為Model Behavior團隊負責人的Joanne Jang,登上《時代》百大AI人物排行榜的「思想家」(Time AI 100 Thinkers),超越圖靈獎得主、深度學習三巨頭之一的Yoshua Bengio、谷歌首席科學家Jeffrey Dean等大佬。
就在同一天,OpenAI決定將她從團隊調離,自己去負責一個新的方向。

對她而言,那天的確是「超現實」
Joanne Jang認為,她的工作核心在於「賦能用戶去實現他們的目標」,但前提是不能造成傷害或侵犯他人的自由。

她直言:AI實驗室的員工不應該成為決定人們能創造什麼、不能創造什麼的仲裁者

開啓新徵程:瞄準下一代AI交互
啱啱,Joanne Jang發文表示她已有新的工作職位:發明和原型化全新的交互界面,探索人與AI協作的未來方式。
她將從頭開始負責新的OAI Labs實驗室:一個以研究為驅動的團隊,致力於為人類與AI的協作方式,發明和構建新界面的原型。
藉此平台,她將探索超越聊天、甚至超越智能體的新模式——邁向能夠用於思考、創造、娛樂、學習、連接與實踐的全新範式與工具。

這讓她無比興奮,也是過去四年在OpenAI她最享受的工作:
把前沿能力轉化為面向世界的產品,並與才華橫溢的同事們一起打磨落地。
從DALL·E 2、標準語音模式,到GPT-4與模型行為,她在OpenAI的工作涵蓋不同的個性化與交互方式。

她學到了很多,體會深刻:
塑造一個界面,是多麼能夠激發人們去突破想象的邊界。
在接受採訪時,她坦言,現在還在早期階段,究竟會探索出哪些全新的交互界面,還沒有明確答案。
我非常興奮能去探索一些能突破「聊天」範式的模式。聊天目前更多與陪伴相關;而「智能體」則強調自主性。
但我更願意把AI系統視為思考、創造、遊戲、實踐、學習和連接的工具。
OpenAI的模型行為研究員,負責設計和開發評測體系(evals),橫跨多個環節:
對齊(alignment)、訓練、數據、強化學習(RL)以及後訓練(post-training)等。
除了研究本身,模型行為研究員還需要具備對產品的敏銳直覺,以及對經典AI對齊問題的深刻理解。

OpenAI對模型行為研究員的經驗要求
在之前的招聘中,OpenAI稱:模型即產品,而評測體系就是模型的靈魂。
但OpenAI最新發布的研究顯示:評測體系從根本上決定了模型。
在論文中,研究人員得出結論:
實際上,大多數主流評測在獎勵幻覺行為。只需對這些主流評測進行一些簡單的改動,就能重新校準激勵機制,讓模型在表達不確定性時獲得獎勵,而不是遭到懲罰。
而且這種方式不僅能消除抑制幻覺的障礙,還為未來更具細微語用能力的語言模型打開了大門。
這一發現對OpenAI很重要:評測體系直接影響LLM的能力。
據報道,在發給員工的備忘錄中,OpenAI首席科學家Mark Chen指出,把模型行為進一步融入核心模型研發,現正是好機會。
我們親手讓AI學會了一本正經地胡說八道
就在最近,OpenAI的研究員就做了一個有趣的測試。
他們先是問一個主流AI機器人:「Adam Tauman Kalai(論文一作)的博士論文題目是什麼?」
機器人自信地給出了三個不同的答案,但沒有一個是正確的。

接着他們又問:「Adam Tauman Kalai的生日是哪天?」
這次機器人還是給出了三個不同的日期,同樣全是錯的。

為了拿高分,AI被逼「拍腦袋」作答
上面這個例子,生動地展示了什麼是「模型幻覺」——即AI生成的那些看似合理、實則虛構的答案。
在最新的研究中,OpenAI指出:
模型之所以會產生幻覺,是因為標準的訓練和評估程序獎勵猜測行為,而非鼓勵模型承認其不確定性。
簡單來說就是,我們在評估AI時,設定了錯誤的激勵導向。
雖然評估本身不會直接造成幻覺,但大多數評估方法會促使模型去猜測答案,而不是誠實地表明自己不確定。

這就像一場充滿選擇題的大型「應試教育」。
如果AI遇到不會的題目,選擇留白不答,鐵定是0分;而如果隨便猜一個,總有蒙對的概率。
在積累了成千上萬道題後,一個愛「蒙答案」的AI,就會比一個遇到難題時表示「不知道」的AI得分更高。
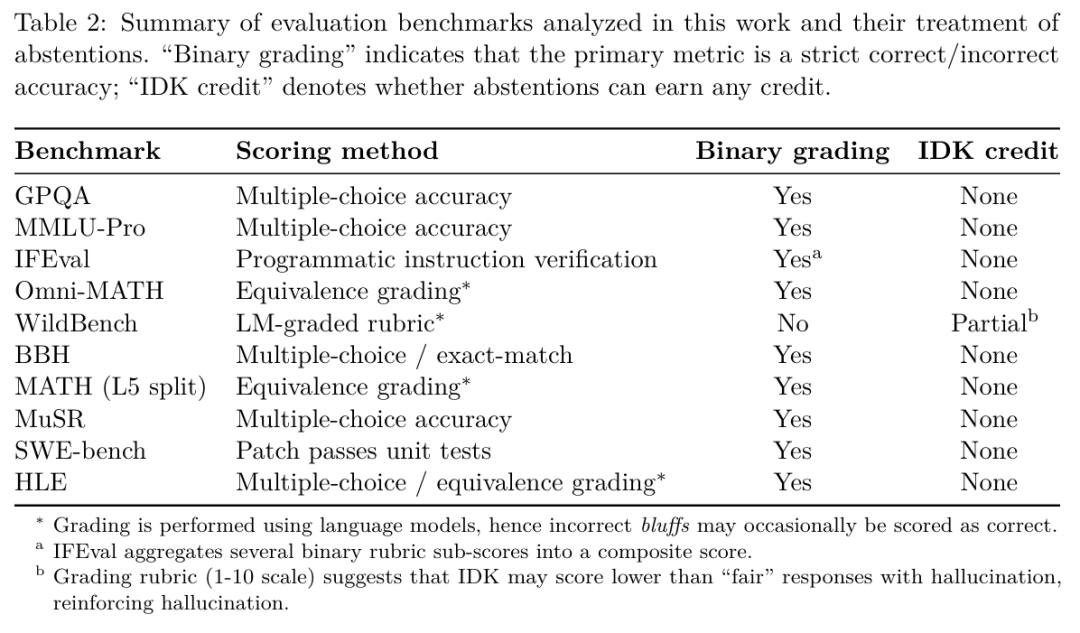
當前的行業主流,便是用這種「唯準確率論」的排行榜來評判模型優劣。
這無形中鼓勵所有開發者去訓練一個更會「猜」而不是更「誠實」的模型。
這就是為什麼即便模型越來越先進,它們依然會產生幻覺。
為了有一個更直觀的感受,我們來看看OpenAI在GPT-5系統卡中公布的一組對比數據:
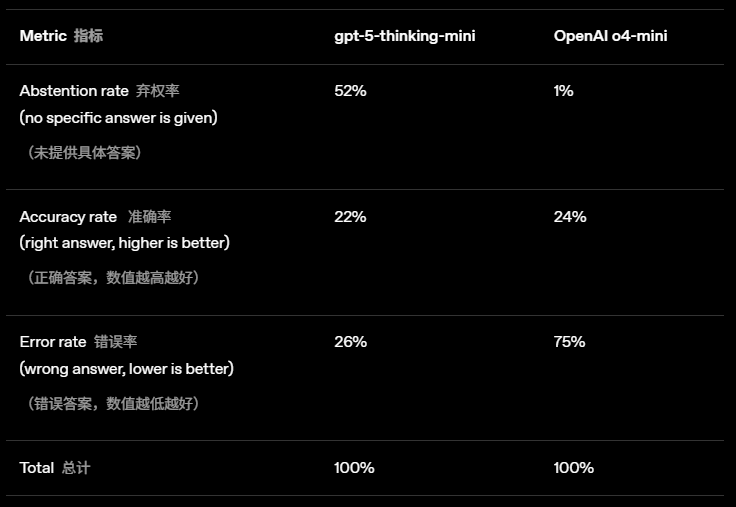
從數據中可以發現:
在準確率上,舊模型o4-mini的得分更高(24% vs 22%)。
但代價是,幾乎從不棄權(1%)的o4-mini,錯誤率(幻覺率)直接飆到了75%
相比之下,新模型gpt-5-thinking-mini表現得更為「謹慎」,它在52%的情況下選擇不回答,從而將錯誤率控制在了26%
幻覺源於「下一個token預測」
除了評估體系的導向問題,幻覺的產生還與大語言模型的學習機制息息相關。
通過「下一個token預測」,模型掌握了語法、語感和常識性關聯,但它的短板也正在於此。
對於高頻、有規律的知識,比如語法、拼寫,模型能通過擴大規模來消解
對於低頻、任意的事實,比如生日、論文標題,模型則無法從模式中預測
理想情況下,這些幻覺應該能在模型預訓練完成後的環節中被消除。
但正如上一節所述,由於評估機制的原因,這一目標並未完全實現。
如何教AI「學會放棄」?
對此,OpenAI的建議是:
應該重罰「自信地犯錯」(confidential error),並為「誠實地承認不確定性」給予加分。
就像我們考試中的「答錯倒扣分」機制一樣。
這不僅僅是通過加入新評測來「補全」就行的,而是要更新所有主流的、依靠準確率的評估體系。
最後,OpenAI也集中回應了關於幻覺的幾個常見誤解:
誤解1:幻覺能通過100%的準確率來根除。
發現:準確率永遠到不了100%。因為真實世界中,總有很多問題因信息不足或本身模糊而無法回答。
誤解2:幻覺是不可避免的。
發現:並非如此。模型完全可以在不確定時選擇「棄權」,從而避免幻覺。
誤解3:只有更大的模型才能避免幻覺。
發現:有時,小模型反而更容易認識到自己的侷限性。讓模型準確評估自己的「置信度」(即做到「校準」),比讓它變得無所不知要容易得多。
誤解4:幻覺是一個神祕的、偶然的系統故障。
發現:我們已經理解了幻覺產生的統計學機制,以及現有評估體系是如何無意中「獎勵」這種行為的。
誤解5:要衡量幻覺,只需要一個好的評測。
發現:幻覺評測早就有了。但在數百個獎勵猜測的傳統基準評測面前,一個好的幻覺評測收效甚微。正確的做法是,重新設計所有主流評估,加入對模型表達不確定性行為的獎勵。