IT 之家 9 月 13 日消息,百度於 9 月 10 日在 Hugging Face 發布新一代文字識別解決方案 PP-OCRv5。
百度介紹稱,PP-OCRv5 是一個為緩解大型視覺語言模型(VLMs)侷限性而設計的專用 OCR 模型,它提供了一種高效、準確且輕量級的解決方案。
PP-OCRv5 通過保持模塊化、兩階段的流程,專門針對高速、精確的文本檢測和識別,解決了大型 VLMs 的精確文本定位和邊界框精度侷限性問題。
PP-OCRv5 的亮點如下:
效率:該模型參數量僅為 0.07B,能夠在 CPU 和邊緣設備上實現更高性能,其移動版本在英特爾 Xeon Gold 6271C CPU 上每秒可處理超過 370 個字符。
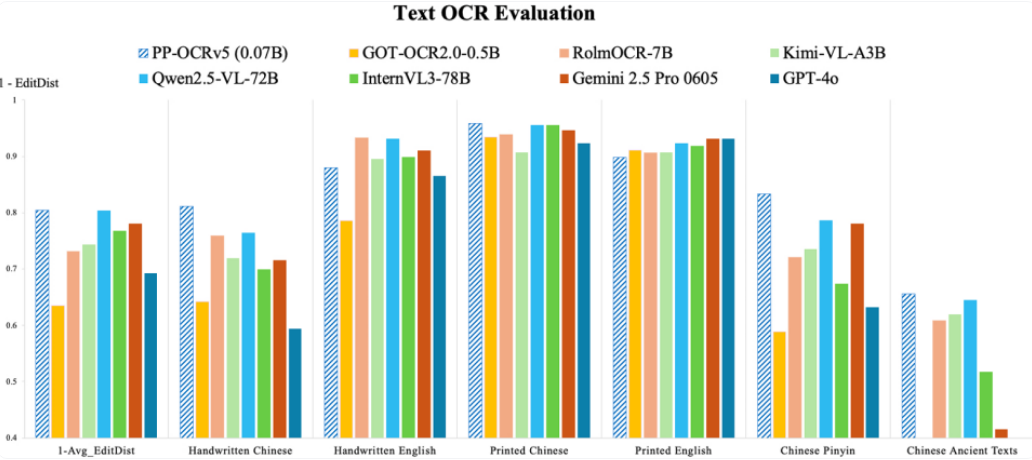
性能:PP-OCRv5 在 OCR 特定基準測試中優於通用型 VLM 模型,如 Gemini 2.5 Pro、Qwen2.5-VL 和 GPT-4o,包括手寫和印刷的中英文以及拼音文本。
定位:PP-OCRv5 旨在提供精確的文本行邊界框座標,這對於結構化數據提取和內容分析是關鍵要求。
多語言支持:該模型支持五種文字類型 —— 簡體中文、繁體中文、英文、日文和拼音,並能識別超過 40 種語言。
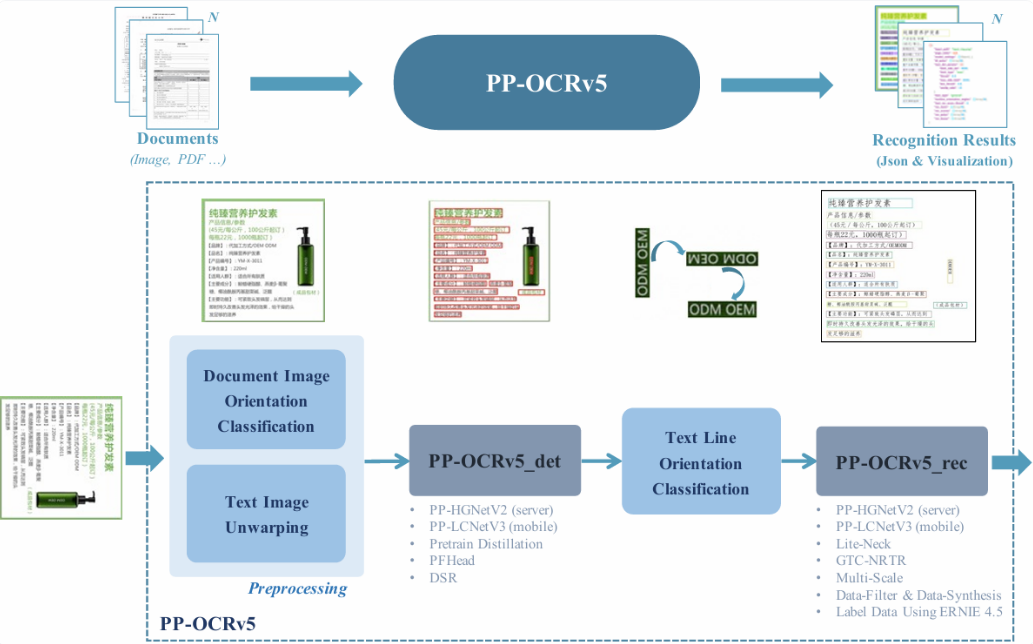
PP-OCRv5 由四個核心組件構成:
圖像預處理:處理圖像的旋轉和畸變,以標準化輸入。
文本檢測:識別圖像中文本行的精確位置。
文本行方向:分類檢測到的文本方向,以確保其正確對齊以進行識別。
文本識別:將每行文本中的字符解碼為文本字符串。