Voyager世界模型的發布為多個行業帶來顛覆性變革。在VR/AR領域,它能從單張圖片生成一致的3D點雲,大幅降低開發成本;在遊戲開發中,自動化3D場景生成能力顯著提高效率;影視製作方面,相機可控視頻生成解放了創作自由度;建築規劃領域可快速將設計轉為可探索的3D場景;教育培訓則能提供沉浸式學習體驗。
在人工智能和計算機視覺這個圈子裏,3D場景生成一直是個公認的硬骨頭。
虛擬現實 (VR)、增強現實 (AR)、遊戲開發這些熱門領域,哪個不嗷嗷待哺,等着高質量、能互動的3D場景投餵?需求一天比一天大,但技術瓶頸卻始終卡在那裏。
騰訊混元團隊甩出了一張王牌——混元世界模型-Voyager(HunyuanWorld-Voyager)。號稱業界首個支持原生3D重建的超長漫遊世界模型,聽上去就是要給3D場景生成領域來一次徹底的「改朝換代」。

咱們先聊聊,這事兒為什麼這麼難?
一直以來,搞3D場景生成的技術路線都挺糾結的。一條路是純搞視頻生成,優點是畫面能連續動起來,給你一種沉浸感。但缺點也致命,你看的只是個「影像」,沒法真正跟場景互動。想在裏面搞個物理仿真或者VR體驗?那基本沒戲,因為它壓根沒有真實的3D結構。
另一條路就頭鐵一點,直接上手生成3D世界。這條路聽起來很美好,空間結構一致性強,後續應用拓展性也好。可問題是,高質量的3D訓練數據去哪找?又貴又少。而且3D表徵那巨大的內存佔用,讓模型很難泛化到更多樣、更宏大的場景裏去。兩條路,似乎都有點走不通。
混元世界模型-Voyager打破了傳統視頻生成在空間一致性和探索範圍上的天花板,不僅能生成超長距離、全局都對得上的漫遊場景,最牛的是,它還能把生成的視頻直接導出成3D格式。這一下,就給虛擬現實、物理仿真、遊戲開發這些領域送去了最需要的高保真3D場景漫遊能力。可以說,Voyager的出現,正式宣告3D場景生成技術進入了下一個時代。
用騰訊混元團隊自己的話說,Voyager是混元世界模型1.0的官方擴展。要知道,距離他們發布HunyuanWorld 1.0 Lite版才過了短短兩周。這種迭代速度,只能說騰訊在AI領域的研發實力和投入確實有點「恐怖」。
所以,這玩意兒到底是怎麼做到的?
混元世界模型-Voyager的背後,是兩個「神仙打架」級別的核心組件在協同工作。正是它們的設計,才讓長距離、世界一致的視頻生成和3D重建從理想照進了現實。
第一個組件叫「世界一致的視頻擴散」(World-Consistent Video Diffusion)。你可以把它理解成一個既懂藝術又懂物理的「導演」。傳統的視頻生成模型,大多是「文藝青年」,只管畫面好不好看(生成RGB視頻),完全不管物理世界的深度信息。
但Voyager這位「導演」不一樣,它在生成視頻的時候,創新性地把場景深度預測也給加了進來,相當於同時搞定了視頻生成和3D建模兩件事。它能根據你給的初始畫面和指定的相機移動軌跡,合成出可以自由控制視角、空間上完全連貫的RGB-D視頻。這個「D」就是深度(Depth)的意思,意味着視頻的每一幀都自帶了3D點雲信息。

這一招的厲害之處在於:
首先,它是多模態聯合生成,RGB視頻和深度視頻同步產出,而且保證精確對齊,直接省去了後期處理的麻煩,數據質量還高。
其次,它通過一個基於現有世界觀測的條件生成機制,確保你生成的視頻不管拉多長,從頭到尾在視覺上和幾何結構上都是統一的,不會出現走着走着牆歪了、桌子沒了的詭異情況。
最後,它還是端到端生成,不像老辦法那樣需要COLMAP這類額外的3D重建工具來「打補丁」,天生就保證了跨幀的一致性。
第二個組件叫「長距離世界探索」(Long-Range World Exploration)。如果說第一個組件是「導演」,那這個組件就是個擁有無限精力的「勘探隊」。它解決的是傳統模型跑不遠、跑着跑着就迷路的問題。
它的核心法寶是一個高效的「世界緩存」機制。具體來說,它會先用混元世界模型1.0生成一個初始的3D點雲作為「基地」,然後把這個「基地」的信息投影到你想要去的新視角,給擴散模型當「導航」。
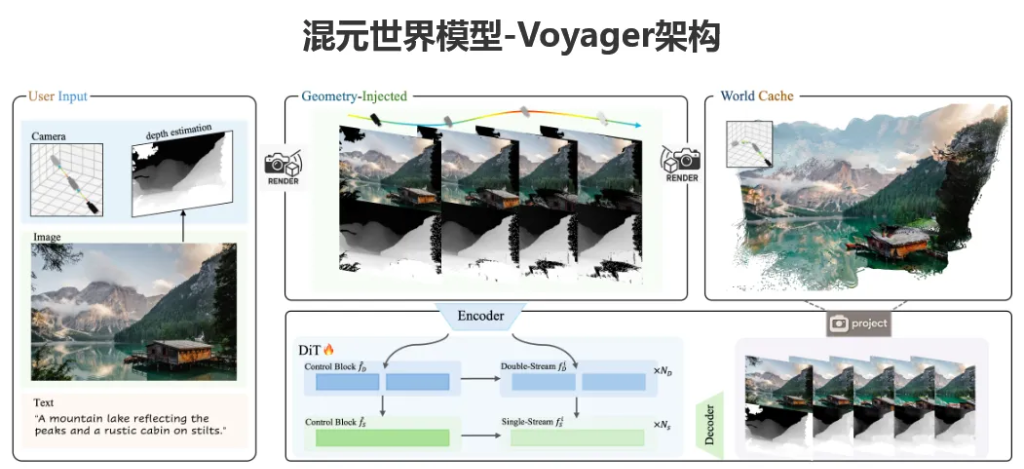
為了應對越來越大的場景,這個「勘探隊」還學會了「點雲剔除」技術,聰明地管理和優化海量的點雲數據,大大提升了計算效率。更妙的是,它採用了一種自迴歸的推理方式,簡單說就是「邊走邊看邊記」。新生成的視頻幀會實時更新那個「世界緩存」,形成一個閉環系統。
這樣一來,無論你的相機軌跡多麼風騷,它都能保持幾何上的一致性,不僅把漫遊範圍拓寬了,還能反過來給混元世界模型1.0補充新的視角內容,讓整體生成質量更上一層樓。再加上一個叫「上下文感知的一致性技術」來保證視頻採樣絲滑流暢,最終給你的就是電影級的沉浸式體驗。
把這兩個組件合在一起,Voyager就能實現從一張靜態圖出發,生成一個全局一致的3D點雲世界,然後讓你拿着「虛擬攝像機」,想怎麼逛就怎麼逛。逛的同時,它還把帶精確深度信息的RGB視頻一起生成了,高質量的3D重建簡直是信手拈來。
用「暴力美學」喂出來的大模型
要訓練出Voyager這麼一個「怪物」,得餵給它多少「精神食糧」?他們搭建了一套堪稱「數據永動機」的引擎——一個全自動的視頻重建流水線。這套系統能把任何輸入的視頻,自動估算出相機位姿和真實的度量深度。這意味着什麼?意味着他們徹底擺脫了昂貴又耗時的人工標註,可以規模化、多樣化地生產訓練數據。
這個數據引擎的工作流程大概是這樣的:
先把視頻扔進去進行預處理,挑出質量好的幀。然後,用上了SLAM (同步定位與地圖構建) 和捆綁調整算法,自動算出每一幀的相機位置和朝向,這是訓練相機可控模型的關鍵。
接着,用深度估計模型預測出每一幀畫面的深度信息,和RGB圖像配對,就成了Voyager最愛喫的「RGB-D套餐」。最後,系統還會自動檢查對齊和驗證數據質量,把不合格的樣本踢出去。
靠着這套自動化流水線,團隊整合了真實世界裏拍的視頻和用虛幻引擎渲染的視頻,硬是攢出了一個包含超過10萬個視頻片段的超大規模數據集。這個數據集不僅量大管飽,而且來源多樣,涵蓋了各種場景和風格,並且每一份數據都自帶了相機位姿和度量深度這些寶貴的「標籤」。
正是這個高質量、多樣化的大數據集,才把Voyager「喂」得如此強大。
在檢驗成果的時候,研究團隊用了一個叫RealEstate10K的公開數據集來當「考官」。這個數據集來頭不小,是從YouTube上大約1萬個視頻裏扒出來的,包含了大約1000萬幀圖像和對應的相機運動軌跡,是評估視頻生成和3D重建任務的黃金標準。Voyager的很多關鍵性能,就是在這個數據集上跑出來的。
光說不練假把式
了測試Voyager到底有多能打,騰訊混元團隊從視頻生成質量、三維場景重建能力和世界生成能力三個維度,對它進行了一次全方位的「大考」。
首先是視頻生成質量。研究團隊把Voyager和四種主流的開源相機可控視頻生成方法放在一起同台競技。他們在RealEstate10K測試集裏隨機挑了150個視頻片段,用PSNR、SSIM和LPIPS這三個業界公認的指標來打分,分別衡量生成畫面和真實畫面的感知相似性與結構一致性。

結果怎麼樣?看錶就知道了。
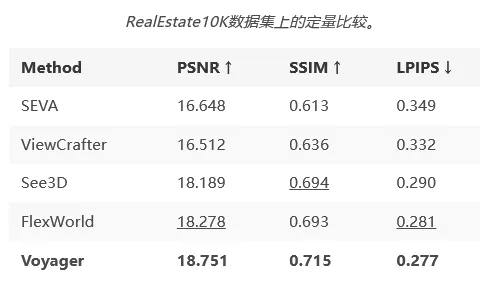
Voyager在所有指標上都實現了全面領先,可以說是毫無懸念地拿下了第一。PSNR指標達到了18.751,比第二名高了將近0.5;SSIM指標是0.715,同樣力壓羣雄;LPIPS指標則是越低越好,Voyager的0.277是全場最低分,說明它生成的內容在人眼看來和真實的視頻最像。
再看看具體的生成效果對比,差距就更明顯了。尤其是在最後一組例子裏,只有Voyager成功地保留了輸入圖像中產品的細節特徵。反觀其他幾個方法,要麼就產生了明顯的瑕疵,要麼就像第一個例子裏那樣,當相機運動幅度一大,直接就「崩了」,生成了完全不合理的結果。

接下來是更硬核的場景生成質量評估。因為對手們都只能生成RGB幀,研究團隊還挺「貼心」地先用一個叫VGGT的工具幫它們估計相機參數,再用它們生成的視頻來初始化點雲。
而Voyager這邊就輕鬆多了,因為它直接生成RGB-D內容,根本不需要任何中間處理,就能直接拿去做高質量的3D Gaussian Splatting (3DGS) 重建。
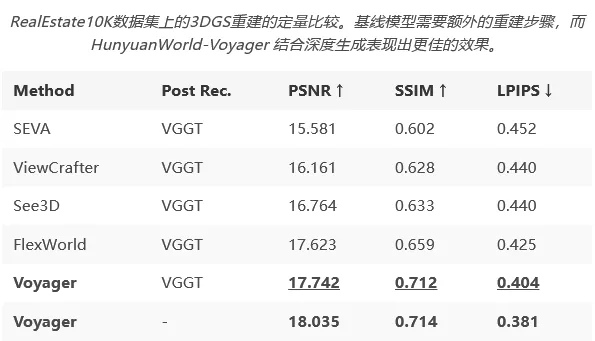
從表格數據可以看到,即便是在對手們都用了VGGT「外掛」的情況下,Voyager的重建結果依然是最好的,這說明它生成的視頻在幾何一致性上確實更勝一籌。而當Voyager使用自己生成的深度信息來初始化點雲時(也就是完全不用後處理),效果還能更上一層樓,這直接證明了它那個深度生成模塊的強大之處。
從定性結果看,比如在最後一組的吊燈例子裏,Voyager很好地保留了吊燈的複雜細節,而其他方法連基本形狀都重建不出來,高下立判。
最後,是世界生成能力的終極考驗。團隊把Voyager拉到了WorldScore這個靜態基準上進行評測。這個基準由斯坦福大學李飛飛團隊提出,是專門用來統一評估世界生成模型的,含金量極高。
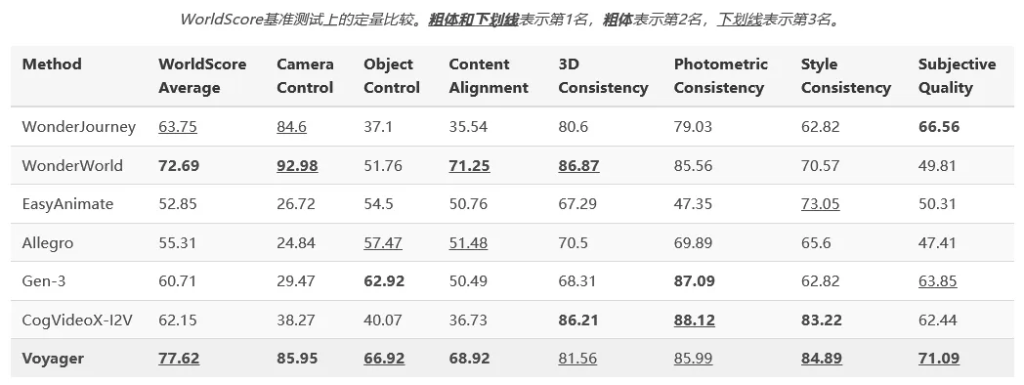
結果再次震驚全場。Voyager以77.62的綜合得分雄踞榜首,把其他模型遠遠甩在身後。在各項細分指標裏,它在物體控制、內容對齊、風格一致性和主觀質量四個方面都是第一,相機控制排第二,3D一致性和光度一致性也表現優異。
這充分說明,Voyager在相機運動控制和空間一致性上,已經具備了和頂級3D方法一較高下的實力。特別是在主觀質量評價上拿到最高分,再次驗證了它生成視頻的視覺真實感。
所以,這將如何改變我們的世界?
Voyager的發布,絕不僅僅是一次技術參數的刷新,它真正開啓的是一片廣闊的應用藍海。作為第一個能打通「超長漫遊」和「原生3D」的的世界模型,它給好幾個行業都帶來了顛覆性的想象空間。
在虛擬現實 (VR) 和增強現實 (AR) 領域,Voyager簡直就是天降甘霖。過去,VR/AR應用裏的3D場景基本靠「堆人力」,建模師們苦不堪言,不僅耗時耗力,還很難搞定大規模場景的實時生成。現在Voyager來了,
從一張圖就能生成一個世界一致的3D點雲,還支持你自定義路徑去探索。這意味着開發者可以光速生成大規模的3D場景,開發周期和成本雙雙打折。而且,它生成的RGB-D視頻可以直接用於渲染,效率直接拉滿。
遊戲開發行業同樣迎來了福音。傳統遊戲開發裏,3D場景建模是個重活、苦活。而Voyager的自動化3D場景生成能力,就是給遊戲開發者送上的一把「神器」。無論是做遊戲原型的快速開發,還是像開放世界遊戲那樣需要超大地圖的場景生成,Voyager都能大大提高效率。它甚至能根據用戶的輸入實時生成動態內容,給遊戲玩法帶來了更多可能。
對於影視製作和動畫領域,Voyager的相機可控視頻生成能力,讓創作變得更自由。過去那些複雜的鏡頭運動,現在可能只需要輸入一張圖和一條相機路徑就能搞定。這不僅是效率的提升,更是創作自由度的解放。
在建築與城市規劃領域,Voyager則是一個強大的可視化工具。設計師們可以快速地將他們的設計草圖或照片,變成可供自由探索的詳細3D場景,與客戶和同事的溝通效率將發生質的飛躍。
甚至在教育與培訓領域,Voyager也能大放異彩。想象一下,醫學生可以在Voyager生成的精細3D人體器官模型裏進行虛擬解剖學習,工科生可以拆解和觀察複雜機械的3D結構,這種沉浸式的學習體驗,效果遠非書本和PPT可比。
混元世界模型-Voyager的發布,漂亮地解決了傳統路線上的核心矛盾,為業界樹立了一個全新的技術標杆。
騰訊混元團隊也表示,Voyager與之前的混元世界模型1.0和1.0 Lite版共同構成了完整的技術體系。
隨着它的開源,更多的開發者和研究者將能站在這位「巨人」的肩膀上,去探索和創造更多可能。