如今,春天英偉達的GTC,秋天OpenAI的DevDay,是硅谷最重要的盛會。它們預告了未來。
在剛過去的OpenAI開發者日上,除了發布了ChatGPT Apps SDK、AgentKit、GPT-5 Codex,奧特曼提到的幾組截至2025年的數據,揭示AI行業正在駛向何方:
平台400萬開發者;
8億ChatGPT周活用戶;
API調用每分鐘60億token。
讓我們就此做一點大膽地假設與簡單的計算。
第一,OpenAI整體每月tokens消耗。
基於API的調用,顯然不是OpenAI對外提供AI服務的全部。去年,OpenAI曾披露它的基於ChatGPT的消費者訂閱業務,收入佔比約為75%。而按照OpenAI對未來的收入路線規劃,ChatGPT訂閱收入佔比將逐步下滑,取而代之的是API、Agents與其他新業務佔比。當然,目前OpenAI正在佈局Agents相關產品線,並開始探索廣告與電商業務,但相比其他兩大業務,可以說仍然處於商業化早期階段。
不妨讓我們假定,目前,OpenAI來自API的收入,仍然佔據25%,而且,收入佔比對應着token的消耗數量。
那麼,OpenAI基於API的token消耗量,每周將達到60*60*24*7=60萬億tokens,每月則約為260萬億。相應的,基於ChatGPT訂閱的token消耗量,每周將達到180萬億tokens,每月約780萬億。整個OpenAI每月的token消耗合計約為1040萬億。
這意味着OpenAI與谷歌處於相同烈度的競爭之中。谷歌的AI工廠同樣在瘋狂地生產token,從5月的480萬億tokens,驟增至6月的980萬億。當時,Veo 3發布不久,Nano Banana尚未發布。谷歌目前月均token消耗量肯定已經突破千萬億量級。而OpenAI這次公布的數據應該也沒有統計Sora 2放量所帶來的。
第二,ChatGPT用戶畫像。
OpenAI的ChatGPT目前擁有約8億周活用戶,每周消耗約180萬億tokens,折算下來人均每周使用約22.5萬tokens。一項研究將典型推理任務設定為輸入10k、輸出1.5k tokens,據此估算,平均每位用戶每周大約執行20次此類推理任務,也就是在每個工作日向ChatGPT提出約四個重要問題。
當然,這一抽象的平均值,掩蓋了幾個實際應用場景中的結構性差異:少數中重度用戶貢獻了絕大部分token消耗;不同重要程度的問題,交互深度與輪次並不相同。
第三,開發者用戶畫像。
若將API調用主要視作由開發者生態貢獻,那麼,相對2023年,OpenAI平台上的開發者人數增長了2倍,而API消耗的token數量卻增加了20倍。簡言之,短短兩年間,平均每位開發者消耗的token數量增長了10倍。
促成人均消耗量大幅增長的,也許正是深度推理與智能體在各行各業,尤其首先是編碼行業的滲透。
在演講中,奧特曼宣佈GPT-5 Pro將開放API。它就非常適合協助完成非常困難的任務,在金融、法律、醫療保健等領域,以及更多需要高準確性和深度推理的領域。此外,OpenAI的GPT-5 Codex正式發布,從8月以來,Codex的日使用量增長了10倍以上。
這個趨勢仍在增強。智能體的摩爾定律就預言了它能處理的任務的複雜度每7個月翻倍;多智能體間的協作,至少將推理消耗進一步放大到簡單對話的15倍以上。
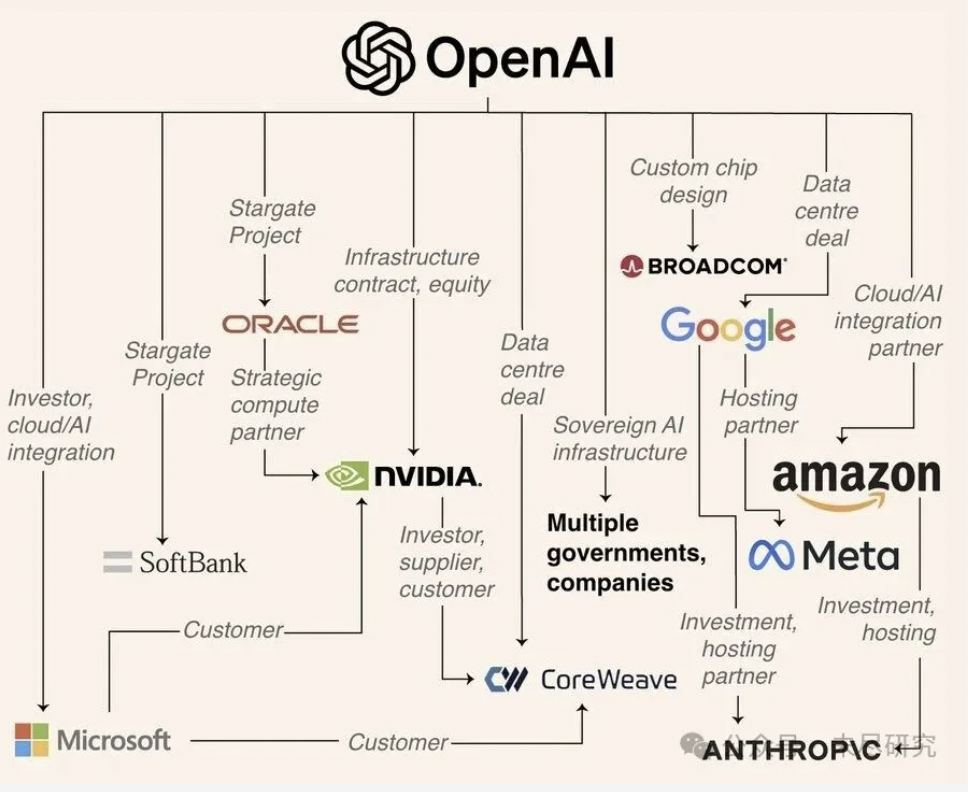
難怪在綁定英偉達10GW的數據中心後,OpenAI又與AMD打得火熱,約定了總計高達6GW的數據中心。奧特曼已經開始營銷它強大10倍的GPT-6,並將數據中心規模提升至2033年得到驚人的250GW。
第四,Sora 2的峯值GPU需求。
從文本推理到多模態生成,算力消耗的曲線將更急劇陡峭。奧特曼還宣佈Sora 2也將開放API。多模態將不斷向現有應用場景滲透,也有望創造出新的應用市場。
但由於OpenAI越來越不透明,不再公開技術細節,對Sora 2算力消耗的估算也不得不建立在一系列大膽而高度敏感的假設之上。總體而言,它與模型與視頻的性能參數,以及工作負荷模式密切相關。
在初代Sora發布的時候,風險投資機構Factorial Funds的Matthias Plappert,就曾基於多重假設估算出,72萬張H100才能滿足它的峯值需求。他假設,初代Sora的參數規模為200億,且以24幀/秒編碼,採樣步數為250步,它與典型的DiT模型類似,即6.75億參數的模型,8倍的壓縮率,以及單幀畫面524×10^9次浮點運算。他還假設Sora在TikTok與Youtube上的滲透率分別為50%與15%。他還考慮了算力實際利用率,峯值需求與候選視頻需求。
可見,模型規模、採樣步數、硬件效率,以及OpenAI在AI社交短視頻上的野心,將是決定Sora 2整體算力需求最關鍵的變量與槓桿。
整體而言,擴散模型仍然滿足擴展定律。年初,對標初代Sora的Step-Video-T2V參數規模達到了300億,也許Sora 2的參數規模也有小幅增長。業界也在探索通過算法改進推動採樣步數的下降。此外,從Hopper架構到Blackwell架構算力性能的提升,以及針對性地推出定製芯片,都在提升算力效率。
不妨先讓我們假定,Sora 2的參數規模增長2.5倍至500億參數;它主要在GB200的FB8精度下推理,約較H100的FP16精度提升了5倍;其他變量此消彼長,整體不變。再讓我們假定,Sora 2繼續向TikTok與Youtube輸出相同體量的內容,且OpenAI最新的獨立應用Sora,將成為短視頻平台的有力競爭者,即每天生成的AI視頻總時長,等同於對外輸出的體量。
換言之,Sora 2的峯值算力需求仍高達約72萬張GPU,只是硬件代際從H100更換為GB200。
這當然只是一個靜態的、片面的估算。隨着AI視頻生成性能的提升,其應用將從社交分享擴展到影視製作等專業領域;社交和短視頻平台也將捲入這場新的軍備競賽,把算力競爭推向新的量級。
難怪奧特曼的目標,是今年底百萬張卡。