IT之家 10 月 10 日消息,科技媒體 venturebeat 於 10 月 8 日發布博文,報道稱三星高級 AI 研究院發布了名為微型遞歸模型(TRM)的開源 AI 模型,僅包含 700 萬個參數,不過在數獨、迷宮等特定的結構化推理任務上,表現媲美甚至超越了參數量為其 10000 倍的谷歌 Gemini 2.5 Pro 等頂尖大模型。
該 AI 模型由三星高級 AI 研究院(SAIT)高級 AI 研究員 Alexia Jolicoeur-Martineau 發布,成為 AI 領域「小模型」對抗「大模型」的趨勢的重磅新案例。
該模型僅有 700 萬參數,設計理念是極致簡化複雜性。在架構方面,摒棄了分層推理模型(HRM)所依賴的雙網絡協作架構,轉而採用一個僅有兩層的單一模型。
其核心機制在於「遞歸推理」:模型對自身輸出的預測進行反覆迭代和修正,每一步都糾正前一步的潛在錯誤,直至答案收斂穩定。
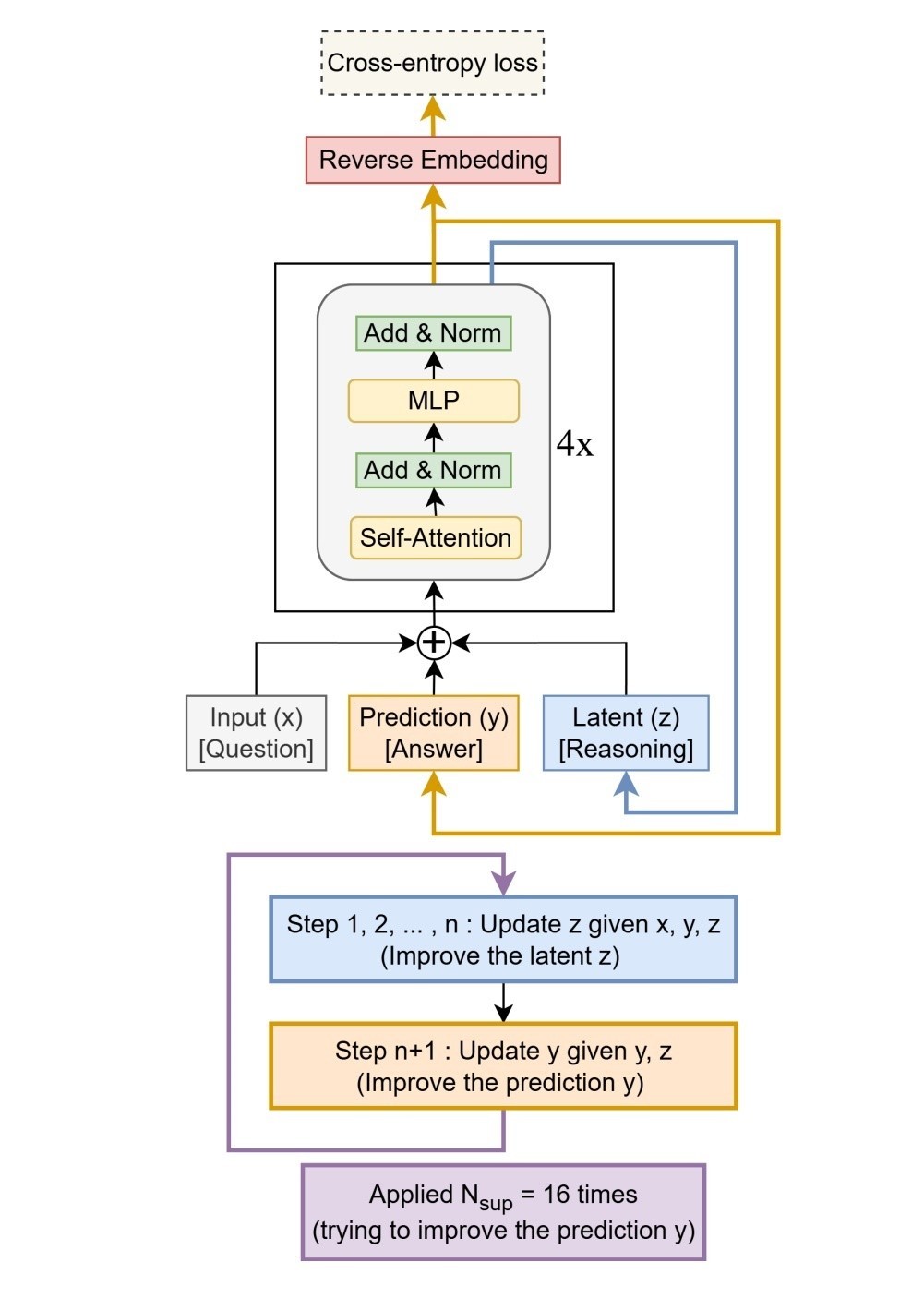
TRM 通過這種方式,用迭代計算的深度模擬了龐大網絡的複雜推理過程,實現了「以遞歸替代規模」的目標,從而在不犧牲性能的前提下,大幅降低了計算和內存成本。
儘管模型極小,TRM 在多個基準測試中展現了「以小博大」的驚人實力:
在 Sudoku-Extreme(極限數獨)測試中,其準確率達到 87.4%;
在 Maze-Hard(困難迷宮)中達到 85%;
在衡量抽象推理能力的 ARC-AGI 測試中準確率為 45%;
ARC-AGI-2 的準確率為 8%。
儘管 TRM 使用的參數不到 0.01%,但這些結果仍然超過或接近幾種高端大型語言模型的性能,包括 DeepSeek R1 、 Gemini 2.5 Pro 和 o3-mini 。
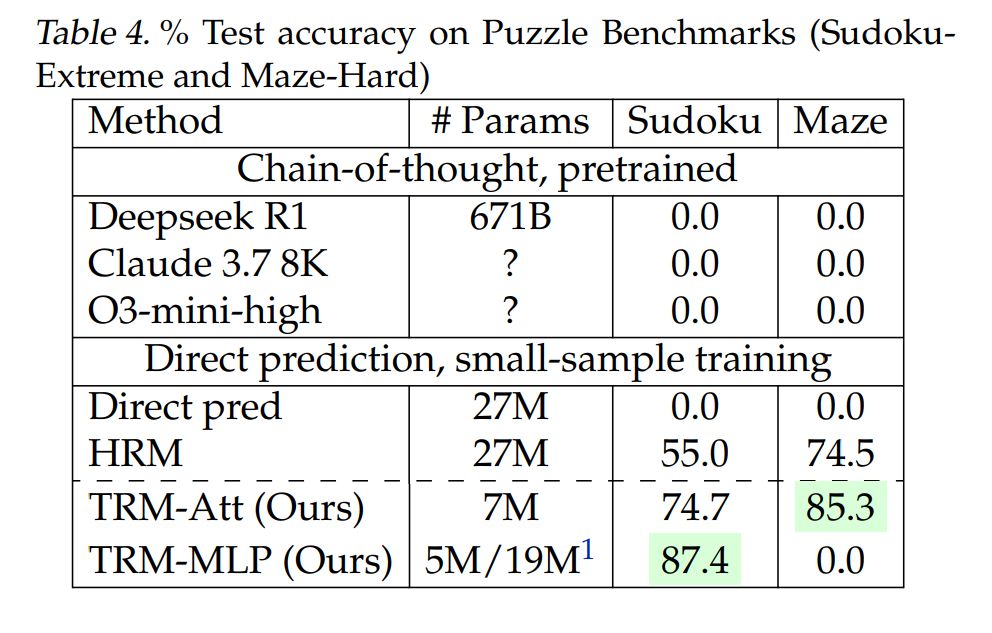
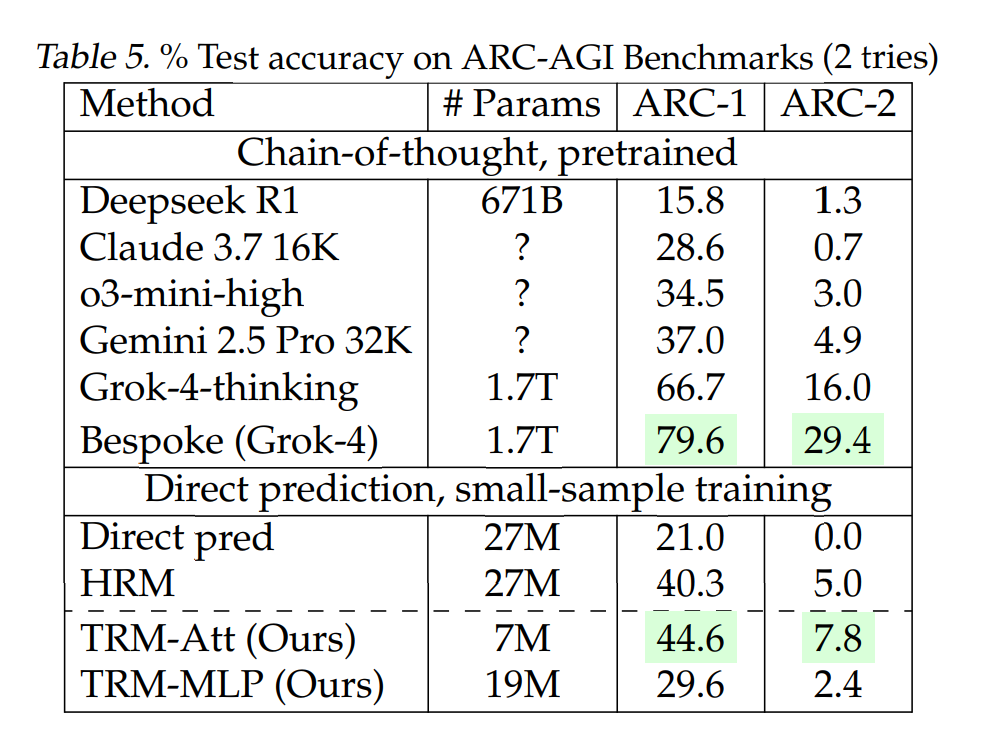
然而,一個重要的前提是,TRM 是專門為解決結構化、可視化的網格類問題(如數獨、迷宮和特定解謎任務)而設計的,並非通用的語言聊天模型,它擅長在有明確規則的封閉環境中進行邏輯推理,而非開放式的語言生成。
TRM 的成功源於其刻意追求的「少即是多」極簡主義設計。研究發現,增加模型層數或大小反而會導致在小數據集上出現過擬合,性能下降。其精簡的雙層結構與遞歸深度相結合,實現了最佳效果。
TRM 的代碼、訓練腳本和數據集目前已在 GitHub 上根據 MIT 許可證完全開源,企業和研究人員均可免費使用、修改和部署,甚至用於商業應用。