讓LLM扔塊石頭,結果它發明了投石機?
大模型接到任務:「造一個能把石頭扔遠的結構。」
誰成想,它真的開始動手造了,在一個真實的物理仿真世界裏,一邊搭零件,一邊看效果,一邊修改。
最後,它造的投石機,把石頭扔了出去。
這就是來自港中大(深圳)、港中大的研究團隊(Wenqian Zhang, Weiyang Liu, Zhen Liu)帶來的最新研究——《Agentic Design of Compositional Machines》。
他們推出了一個叫BesiegeField的新平台,它就像一個給大模型的「機械工程師訓練場」,專門測試AI能不能像人一樣,從零開始設計並造出能動的、有功能的複雜機器。
這還沒完。BesiegeField支持上百次的並行實驗,一旦引入強化學習(Reinforcement Learning),大模型就能「自我進化」:從反饋中調整策略,逐步學會結構設計的物理邏輯,最終學會如何「造出能動的結構」。
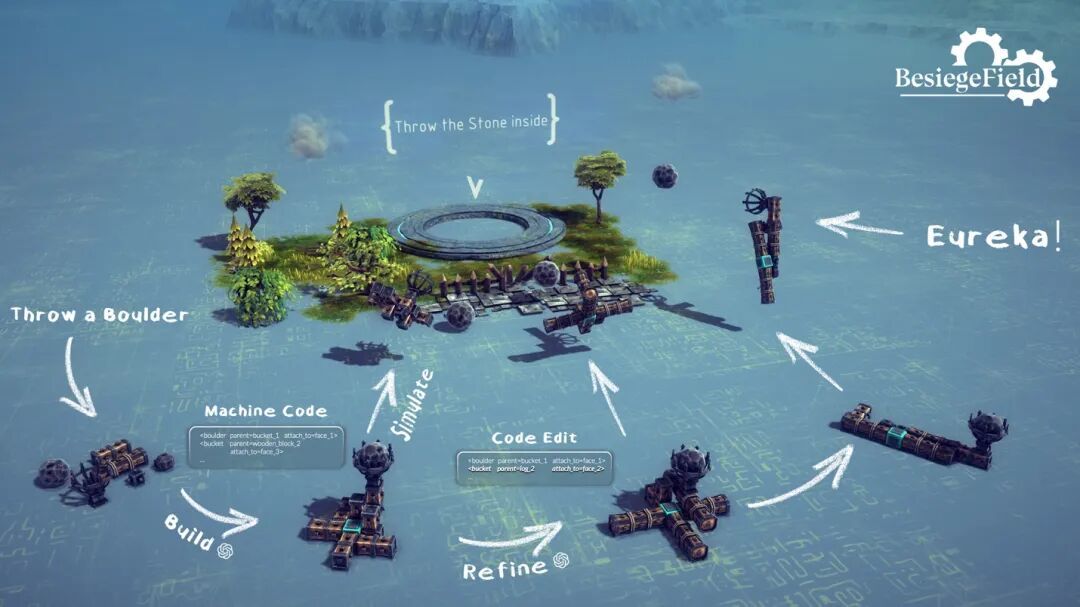
大模型怎麼寫出一個機械結構
首先得明確,這不是讓大模型去畫CAD圖,它也控制不了三維細節。研究者提出了一種叫「組合式機械設計」(Compositional Machine Design)的方法。
說白了,就是把機械結構限定在「用標準零件組裝」這個範圍裏。每個零件(比如支架、關節)都有標準尺寸和接口,大模型只需要決定:
用哪些零件
它們之間怎麼連
這樣,複雜的設計就被簡化成一個「離散結構組合問題」。到底好不好用?能不能動?穩不穩?交給物理仿真去驗證。
為了讓模型好理解和修改,研究者用了一種類似XML的「結構化表示機制」,設計機械就變成了一種語言模型擅長的結構生成任務。

一個自進化訓練場
上面說的這一切,都發生在BesiegeField這個仿真平台裏。它跑在Linux集群上,能同時跑幾百個機械實驗,並給到完整的物理反饋——比如速度、受力、能量變化、投擲距離、穩不穩定、機械損壞度等等。
這些反饋不僅能驗證設計,還能作為強化學習的「獎勵信號」,指導模型改進策略。
在這個平台裏,模型的設計形成了閉環:生成 → 仿真 → 拿反饋 → 調整 → 再來一次。
就算不更新模型參數,它也能靠反饋優化輸出;如果引入強化學習,模型就能通過這些量化的獎勵信號,系統性地提升設計能力和成功率。
平台還設計了一系列從易到難的任務,比如直線行駛、投擲、抓取,甚至還有過障礙、地形坡度、穿環投擲等更復雜的場景,構成了一個多樣化的實驗空間。
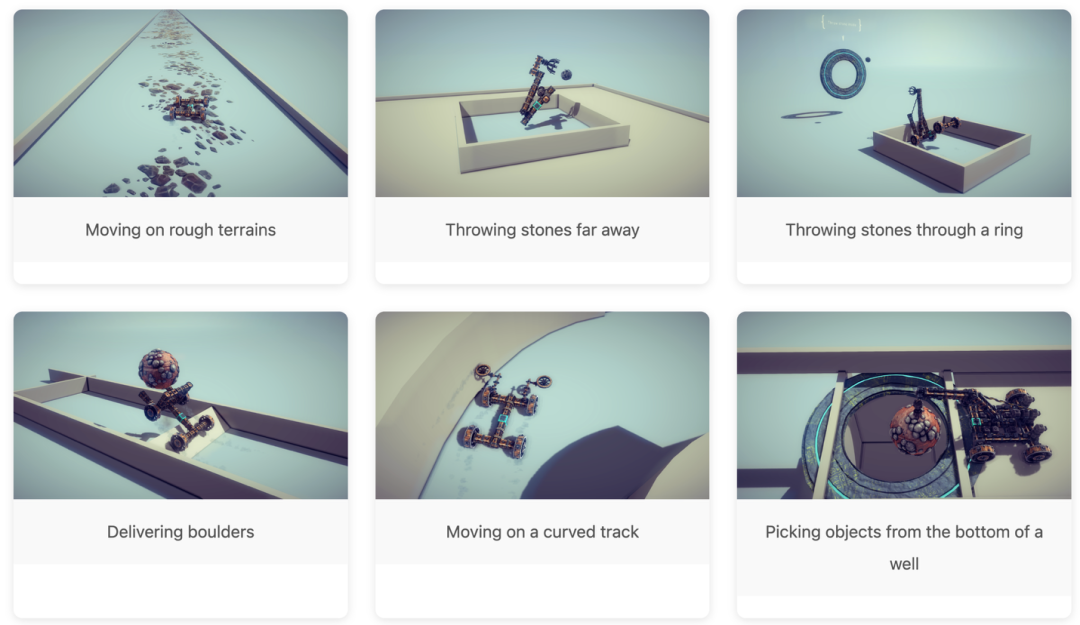
為什麼造機器這麼難
造機器的挑戰,不在於零件多少,而在於它們能不能「在動態中協同工作」來完成複雜功能。
拿投石機來說,配重、支點、發射臂必須在關鍵時刻協同發力,才能把能量精準地扔出去。
只要一個地方偏差,整個機器就可能失效:沒配重,打不出去;缺支點,原地轉圈;少了槓桿,石頭飛不起來。

這些問題,只有在真實仿真中才能被發現,也只有這樣,模型才能一步步搞懂「結構到底是怎麼動起來的」。
差距有多大?人類設計的投石機能投近200米,而大模型設計的,常常連30米都到不了。
這其中,差距就在於對「結構協同」和「發力效率」的理解。
這也是BesiegeField要解決的核心問題——讓它懂得結構之間「如何協同去完成任務」。

模型真學會造結構了嗎
為了解決單個模型「想不明白」的難題,研究團隊構建了一套「智能體工作流」(Agentic Workflow),讓多個AI協作。
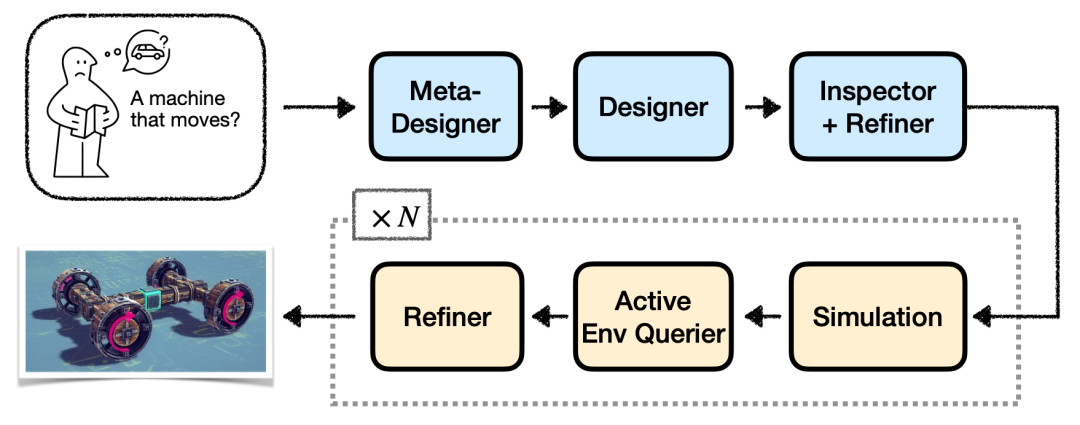
這套系統裏有不同角色:
總設計師(Meta-Designer): 負責拆解任務。
結構設計師(Designer): 搭建初始方案。
審查員(Inspector + Refiner): 檢查結構和連通性。
反饋查詢員(Active Env Querier): 跑仿真並從大量反饋數據內抽取對任務最有用的信息報告。
分析/優化員(Refiner): 解讀反饋,提出修改。
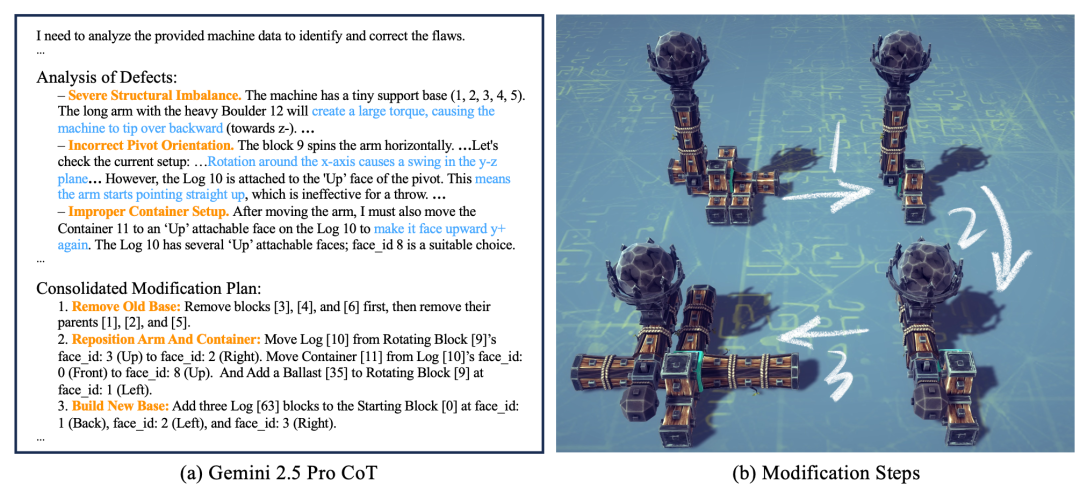
團隊測試了多個主流模型,發現在這套工作流下,Gemini 2.5 Pro的表現很突出。

比如在優化投石機時,Gemini 2.5 Pro能根據仿真反饋,識別出「底座太小導致結構失衡」、「旋轉軸方向錯誤導致無法發力」等問題,並提出「移除舊底座」、「重新定位手臂和容器」、「構建新底座」等修改方案。
對比表格顯示,這套「多角色分層設計」(Hierarchical Design)策略,在投石機(Catapult)和小車(Car)任務上,其平均分(Mean)和最高分(Max)都顯著優於以Gemini為代表的部分「單一模型」或簡單的「迭代修改」策略。
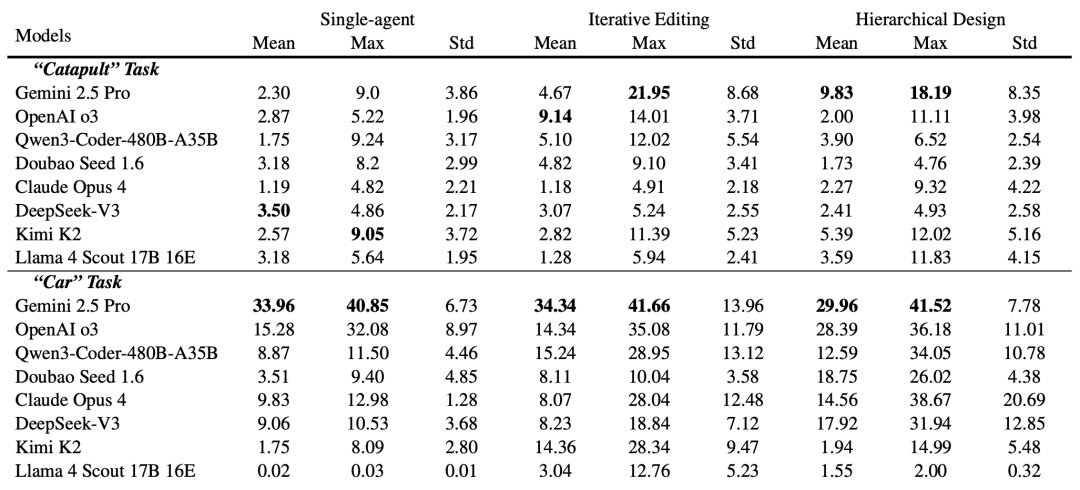
關鍵這些成果是模型自己在真實反饋裏逐步學會調整的。
怎麼讓AI越造越聰明?
有了工作流還不夠,還得讓模型能「自我進化」。研究團隊引入了強化學習(RL),具體用了一種叫RLVR(基於可驗證反饋的強化學習)的策略。
BesiegeField的仿真反饋就是現成的「獎勵信號」(Reward):比如投擲距離多遠?能不能成功執行任務?能運行多久?
研究團隊用了Pass@k Training方法(即在k次嘗試中選獎勵最大的那個樣本作為訓練信號),對Qwen2.5-14B-Instruct這個模型進行持續微調。
效果很明顯。隨着迭代次數增加,模型設計的結構越來越好,投擲距離也越來越遠。

定量數據也顯示,在「Cold-Start + RL」(用少量好例子啓動+強化學習)的策略下,模型在小車任務上的最高分達到了45.72,投石機任務的平均分和最高分也都是最優的。

這是首次證明,LLM確實能藉助RL,在仿真反饋中持續提升機械設計能力。
AI創造力的新邊界
總的來說,BesiegeField帶來的不只是一個仿真平台,更像是一種新的「結構創造範式」。
它把複雜的機械設計,轉變成了一個AI擅長的「結構化語言生成任務」;
它提供了一個閉環,讓模型能在真實的物理反饋中,學會理解力學規律和結構協同;
它支持任務難度可控、流程模塊化、結果可定量評估;
更重要的是,它提供了一個觀察AI如何獲得「空間智能」和「物理智能」的起點。
研究團隊期待,未來AI造的不僅是投石機,而是能奔跑、搬運、協作的各種複雜結構——讓語言模型真正具備「造出會動的東西」的能力。
項目主頁:https://besiegefield.github.io
論文地址:https://www.arxiv.org/abs/2510.14980