
智東西
作者 | 陳駿達
編輯 | 雲鵬
在大語言模型不斷拉長上下文窗口的競爭中,DeepSeek啱啱提出了一條與衆不同的技術路徑。
智東西10月20日報道,今天上午,DeepSeek開源了DeepSeek-OCR模型,首次提出了「上下文光學壓縮(Contexts Optical Compression)」的概念,通過文本轉圖像實現信息的高效壓縮。
這一方法的可行性已經得到驗證,在10倍壓縮比下,DeepSeek-OCR的解碼精度可達97%,近乎實現無損壓縮;在20倍壓縮比下,精度仍保持約60%。
當把等量的文本token轉化為視覺token(圖像)後,DeepSeek-OCR能用更少的token數表達相近的文本內容,這為解決大語言模型在長文本處理中的高算力開銷提供了新的思路。
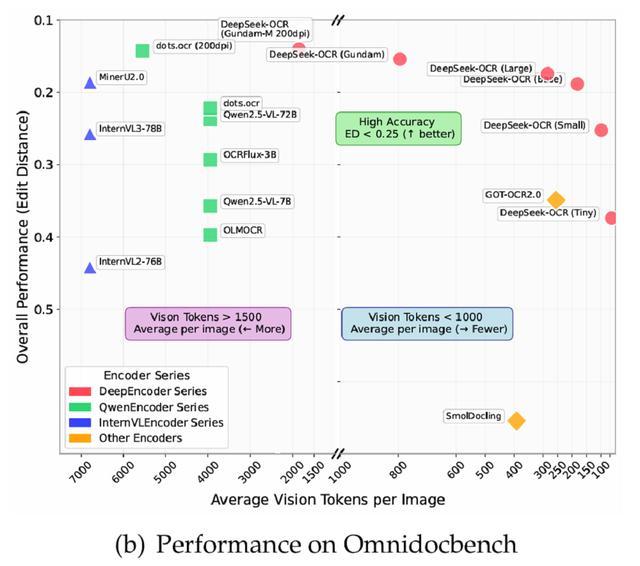
除此之外,DeepSeek-OCR還表現出很高的實際應用價值。在OmniDocBench上,它只使用100個視覺token就超越了GOT-OCR2.0(每頁256個token),並且在使用少於800個視覺tokens的情況下,性能超過了MinerU2.0(平均每頁近7000個token)。
在生產環境中,DeepSeek-OCR可以每天在單個A100-40G GPU上生成20萬頁以上的訓練數據,為大規模文檔理解和多模態模型訓練提供支持。
目前,這一模型已在Hugging Face上開源,而介紹DeepSeek-OCR模型技術細節與背後理論的技術報告也已同步公開。DeepSeek-OCR團隊稱,他們此番開源的模型是對一種潛在解決方案的初步探索,即利用視覺模態作為文本信息的高效壓縮媒介。
值得一提的是,與DeepSeek過往新模型動輒數十人的作者團隊不同,這篇論文的作者僅有3人,分別為Haoran Wei、Yaofeng Sun、Yukun Li。DeepSeek-OCR論文的第一作者Haoran Wei也是GOT-OCR2.0論文的第一作者,GOT-OCR2.0是階躍星辰去年9月發布的一款OCR模型。

開源地址:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
論文鏈接:
https://github.com/deepseek-ai/DeepSeek-OCR/tree/main
一、光學壓縮可實現高壓縮比,解碼到底需要多少視覺token?
過去幾年,AI模型的上下文能力不斷被拉長——從4K到128K,再到上百萬token,但代價是成倍增加的算力與顯存消耗。
但文本其實是一種冗餘的信息形式。DeepSeek-OCR的團隊認為:「一張包含文檔文本(document text)的圖像,可以用比等效數字文本(digital text)少得多的token,來表示豐富信息。這表明,通過視覺token進行光學壓縮可以實現更高的壓縮比。」
目前,業內已經在VLM視覺編碼器和端到端OCR模型上有一定探索。基於此前的研究,DeepSeek-OCR團隊發現了目前尚未解決的一個關鍵研究問題:對於包含1000個單詞的文檔,解碼至少需要多少視覺token?這一問題對於研究「一圖勝千言」的原則具有重要意義。
圍繞這一問題,DeepSeek打造了一個驗證系統——DeepSeek-OCR。該模型通過將文本「光學化」,把原本數千個文字token壓縮成幾百個視覺token,再由語言模型解碼回原文。
DeepSeek-OCR的架構分為兩部分。一是DeepEncoder,一個專為高壓縮、高分辨率文檔處理設計的視覺編碼器;二是DeepSeek3B-MoE,一個輕量級混合專家語言解碼器。
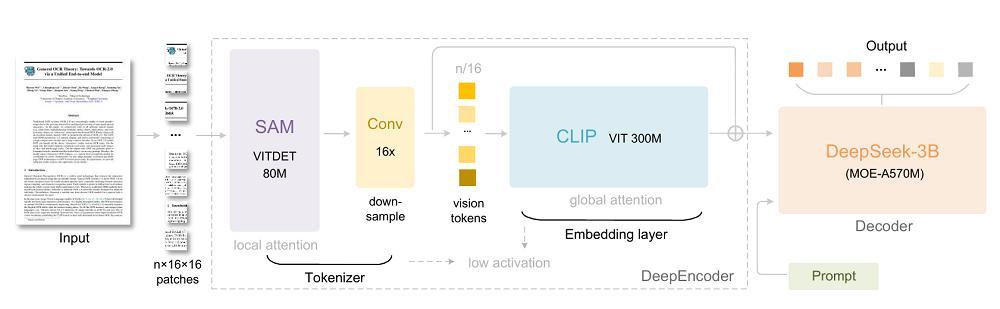
DeepEncoder:顯著壓縮vision token數量
DeepEncoder採用SAM + CLIP的雙結構設計,通過局部窗口注意力結合全局注意力實現高保真視覺理解,並用一個雙層的16×卷積壓縮模塊顯著減少vision token數量。
舉個例子,當輸入1024×1024的文檔圖片時,傳統視覺模型會生成4096個token,DeepEncoder能將其壓縮至僅256個token,讓激活內存的數量更可控。
此外,它支持多種「分辨率模式」。從輕量的Tiny(64 token)到高保真的Gundam(795 token),模型可根據任務複雜度自動選擇壓縮等級。
論文展示了不同分辨率的壓縮效果。對肉眼而言,Tiny模式下圖片中的文字略顯模糊,但基本能看清;而在高保真的Gundam模式下,圖中文字的閱讀體驗基本和原文件的閱讀體驗沒有差別。

實際閱讀效果需參照原論文中的圖片
在實際使用中,一頁普通論文或幻燈片僅需100個視覺token即可精準識別;而密集文本的報紙或科學論文,則可通過Gundam模式實現高精度還原。
DeepSeek3B-MoE:激活參數僅5.7億
在解碼端,DeepSeek採用自研DeepSeek3B-MoE架構,推理時僅激活6個專家模塊,總激活參數量約5.7億。
這種「按需激活」的機制讓模型既具備強表達能力,又能保持低延遲和高能效,極其適合文檔OCR、圖文生成等場景。
數據引擎:從文檔到圖表、化學式、幾何圖
DeepSeek還搭建了一個龐大的數據數據集,包含四大數據類型:
(1)OCR 1.0數據:3000萬頁多語言文檔與自然場景文字等;
(2)OCR 2.0數據:圖表、化學公式、幾何圖形解析等;
(3)通用視覺數據:為模型注入基礎圖像理解能力;
(4)純文本數據:維持語言流暢度與上下文建模。
得益於這一體系,DeepSeek-OCR不僅能識字、斷句,還能看懂圖表、解讀化學式、識別幾何圖形,處理常見的圖文交錯文檔。
二、10倍壓縮效果幾乎無損,數百token表示效果超7000 token
DeepSeek-OCR的訓練流程整體上相對簡潔,主要分為兩個階段:獨立訓練DeepEncoder和訓練完整的 DeepSeek-OCR模型。
此外,所謂的「Gundam-master模式(超高分辨率)」是在預訓練好的DeepSeek-OCR模型基礎上,繼續使用600萬條採樣數據進行微調得到的。由於其訓練協議與其他模式相同,DeepSeek-OCR團隊省略了詳細描述。
DeepEncoder的訓練遵循Vary的做法,使用一個輕量級語言模型,並基於下一token預測框架進行訓練。在此階段,模型使用了前述的OCR 1.0與OCR 2.0數據,以及從LAION 數據集中採樣的1億條通用圖像數據。
當DeepEncoder訓練完成後,DeepSeek-OCR團隊使用多模態數據和純文本數據,採用流水線並行策略來訓練完整的模型。
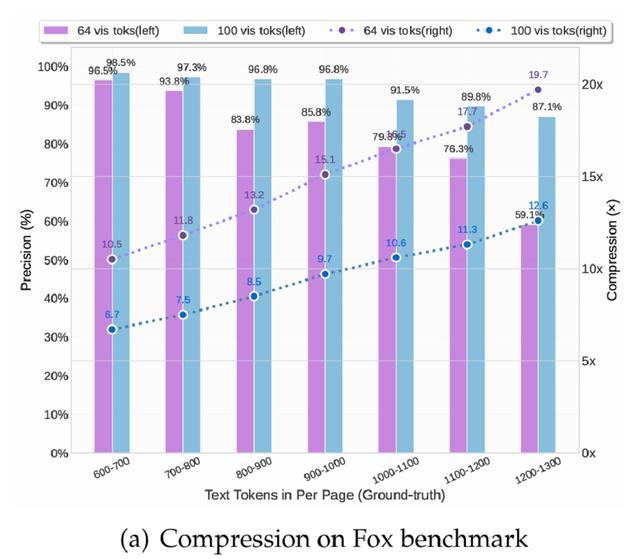
為驗證DeepSeek-OCR在文本密集型文檔中的壓縮與解壓能力,研究團隊選取了Fox基準進行實驗。實驗結果顯示,在10×壓縮率下,DeepSeek-OCR的解碼精度可達約97%。這表明未來有望實現近乎無損的10×文本壓縮。
當壓縮率超過10×時,性能有所下降,主要原因包括文檔版式複雜度的提升,以及長文本在512×512或640×640分辨率下出現模糊。前者可通過將文本渲染為統一版面解決,而後者則可能成為未來「遺忘機制」的研究特徵。
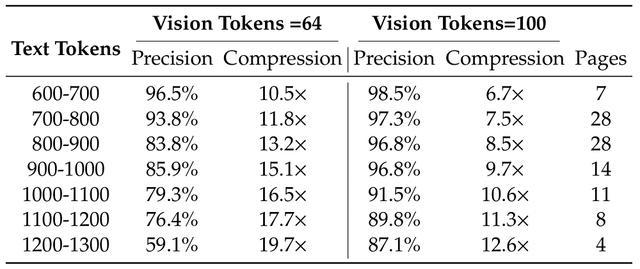
即便在近20×壓縮時,模型仍能保持約60%的精度。這些結果充分說明,光學上下文壓縮是一條前景廣闊的研究方向,且無需額外計算開銷,因為多模態系統本身已具備視覺編碼器結構。
除實驗驗證外,DeepSeek-OCR在實際場景中同樣表現出不錯的能力,可為LLM/VLM的預訓練構建高質量數據。在OmniDocBench上,DeepSeek-OCR僅使用100個視覺toke(640×640 分辨率)的情況下,超越使用256個token的GOT-OCR 2.0。而在少於800個tokens(Gundam 模式)的條件下,DeepSeek-OCR甚至超越了需約7000個視覺token的MinerU 2.0。
進一步分析顯示,不同類型文檔對token數量的需求存在差異:幻燈片類文檔僅需約64個視覺token即可獲得良好效果;書籍與報告在100個視覺token下即可實現穩定性能;報紙類文檔由於文本量龐大,需採用Gundam或Gundam-master模式才能實現可接受的效果。
三、從金融圖表到化學表達式,各類文檔均可深度解析
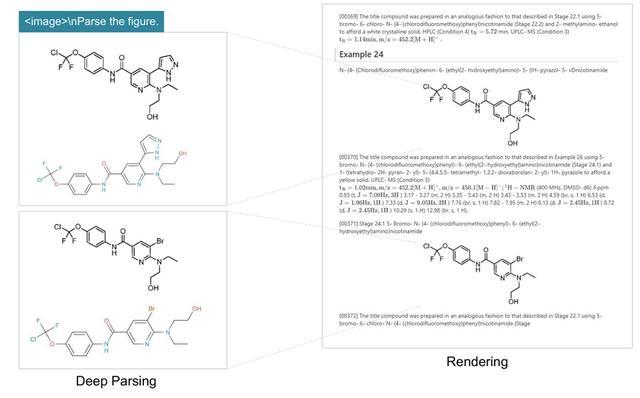
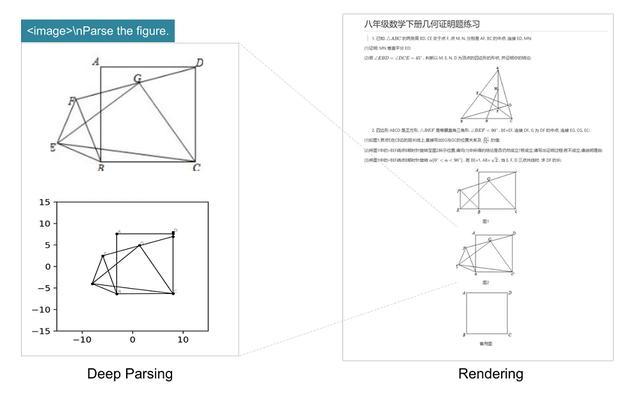
DeepSeek-OCR團隊在論文中展示了DeepSeek-OCR在具體場景的能力。DeepSeek-OCR具備版面識別與OCR 2.0能力,可通過二次模型調用實現文檔圖像的進一步解析。DeepSeek將這一功能稱為「深度解析(Deep Parsing)」。模型可在圖像中識別不同類型的內容,包括圖表、幾何圖形、化學結構式及自然圖像等。
在金融研究報告中,DeepSeek-OCR能自動提取文檔中圖表的結構化信息,這一功能對金融與科學領域尤為重要。
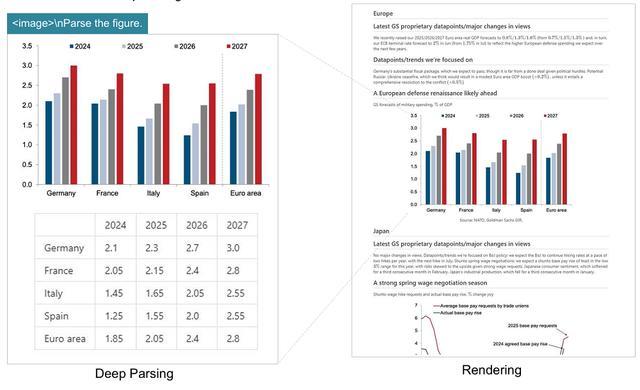
在書籍與論文場景中,深度解析模式能夠生成密集的圖像描述,實現自動化的圖文內容識別與轉寫。

對於化學文獻,模型不僅可識別化學結構式,還能將其轉化為SMILES格式,展現出在STEM(科學、技術、工程與數學)領域的潛在應用價值。
此外,DeepSeek-OCR還能解析平面幾何圖形的結構,儘管當前任務仍具有較高難度,但模型已顯示出對幾何要素與空間關係的初步理解能力。
互聯網上的PDF數據涵蓋多種語言,包括中文、英文以及大量多語種內容,這對訓練具備全球通用性的大語言模型至關重要。DeepSeek-OCR已具備處理近百種語言的OCR能力,支持帶版面與非版面兩種輸出格式。
在多語言測試中,DeepSeek-OCR對阿拉伯語與僧伽羅語等小語種文檔同樣能夠生成高質量識別結果。該能力確保DeepSeek-OCR能在多語言環境下穩定運行,為多語種文檔解析與跨語言知識提取奠定基礎。

除專注於文檔解析外,DeepSeek-OCR還保留了一定的通用視覺理解能力,包括圖像描述、物體檢測、目標定位(grounding)等任務。在提供相應提示詞後,模型能夠詳細描述圖像內容、定位特定對象,甚至在包含文本的圖像中執行OCR識別任務。

此外,由於訓練中融入了大量純文本數據,DeepSeek-OCR也保留了較強的語言理解與生成能力。需要指出的是,DeepSeek-OCR尚未經過監督微調(SFT)階段,因此並非對話模型,部分功能需通過特定提示詞激活。
結語:高效信息表示或成大模型潛在優化方向
「上下文光學壓縮」驗證了視覺模態在文本壓縮中的有效性,為大語言模型處理超長上下文提供了新的解決路徑。DeepSeek-OCR團隊計劃在後續研究中進一步探索數字與光學混合的文本預訓練方式,並通過更細粒度的「needle-in-a-haystack」測試評估光學壓縮在真實長文本環境下的表現。
從行業視角看,DeepSeek-OCR展示了另一種提高模型效率的可能路徑——優化信息表達方式。通過視覺壓縮減少token數量,模型可以在相同算力下處理更長的上下文內容。這一思路為未來在VLM視覺token優化、上下文壓縮機制以及大模型遺忘機制等方向的研究提供了有價值的參考。
DeepSeek團隊在論文最後寫道:「光學上下文壓縮仍有廣闊的研究空間,它代表了一個新的方向。」這項從OCR任務出發的研究,或許已經超越了文字識別本身。