在7000多種人類語言中,只有少數被現代語音技術聽見,如今這種不平等或將被打破。Meta發布的Omnilingual ASR系統能識別1600多種語言,並可通過少量示例快速學會新語言。以開源與社區共創為核心,這項技術讓每一種聲音都有機會登上AI的舞台。
你或許很難想象,在世界上7000多種活躍語言中,只有幾百種享受過現代語音技術的「寵愛」。
絕大多數人類語言的使用者——從非洲部落的土著、亞馬遜雨林的族羣,到鄉野小鎮仍講着古老方言的老人—— 一直生活在數字時代的旁白之外。

語音助手、自動字幕、實時翻譯,這些AI帶來的便利彷彿只為少數「主流」語言而生,其餘的語言社區仍被擋在技術大門之外。
這種數字鴻溝如今迎來了破局者。
Meta人工智能研究團隊日前發布了Omnilingual ASR系統,一個可自動識別轉錄1600多種語言語音的AI模型族,讓幾乎所有人類語言都能被機器「聽懂」。

這套系統以開源方式共享給全世界,並能由社區親手拓展新的語言,讓每一種聲音都有機會登上AI的舞台。

1600種語言,只是開始
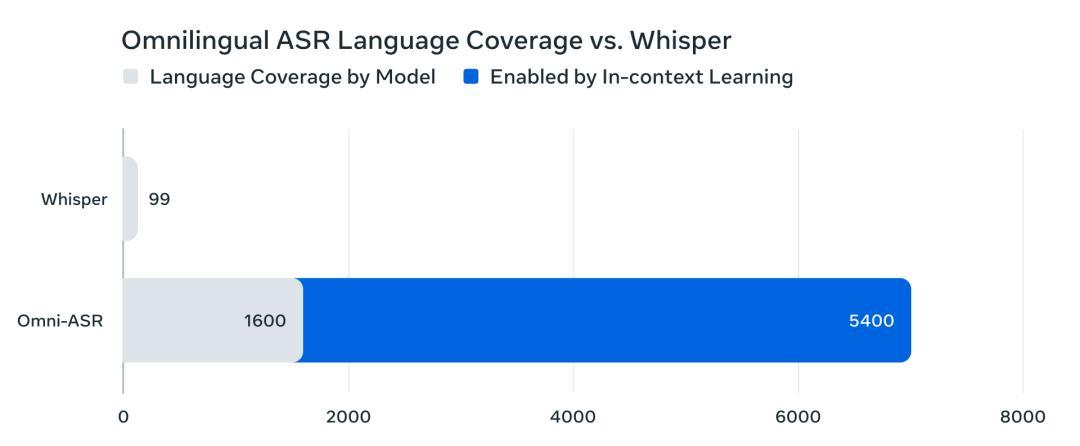
Meta此次推出的Omnilingual ASR創造了語音識別覆蓋語言數量的新紀錄,支持超過1600種語言,其中包括500種此前從未被任何AI系統轉錄過的語言。
相比之下,OpenAI開源的Whisper模型只支持99種語言,而Omnilingual ASR幾乎將這一數字提升了一個數量級。
對於全球衆多使用小語種的人來說,這無疑是一次「數字雪恥」:他們的母語第一次有了被AI流利聽懂的可能性。
這套系統的識別性能在很多語種上已達到領先水平。
據Meta提供的數據,在所測試的1600多種語言中,有78%的語種其識別錯誤率(CER)低於10%,若以10小時以上語音數據訓練的語種來看,這一比例更是達到95%。
即使對於訓練語料極其稀少的低資源語言,仍有36%實現了CER低於10%的效果。

這些數字意味着,Omnilingual ASR不僅覆蓋面廣,而且在大多數語言上都能給出實用且高質量的轉錄結果。
然而,1600種語言還不是Omnilingual ASR的終點。
更大的意義在於,它打破了以往ASR模型支持語言範圍固定死板的侷限,讓語言覆蓋從「定量」走向「可擴展」。
Omnilingual ASR借鑑了大語言模型(LLM)的思路,引入了零樣本的「上下文學習」機制。
這意味着即便某種語言最初不在支持列表中,用戶也可以通過提供幾段該語言的音頻和對應文本作為示例,在推理過程中即時讓模型學會一種新語言。
無需耗費數月收集大型語料、無需專業深度學習訓練,只需簡單的少樣本學習(few-shot)即可學會新語言。
憑藉這種革新性的範式,Omnilingual ASR的潛在語言覆蓋能力驟然擴張。
官方表示,理論上該系統可以擴展到超過5400種語言,幾乎涵蓋所有有文字記錄的人類語言!
無論多冷門的口語,只要有對應的書寫體系和幾句示例,它就有機會被Omnilingual ASR捕捉記錄。
在AI語音識別領域,這是從靜態封閉走向動態自適應的範式轉變——模型不再束縛於訓練時預設的語言清單,而成為一個靈活開放的框架,鼓勵各地社區自行加入新語言。
對於那些長期缺席於技術版圖的族羣來說,這無異於掌握了一把可以隨時親手「解鎖」新語言的大門鑰匙。
開源與社區,打破語言鴻溝
Omnilingual ASR的另一個顯著特點在於其開源和社區驅動的屬性。
Meta選擇將這一龐大的多語種ASR系統在GitHub上完全開源,採用Apache 2.0許可發布模型和代碼。

無論是研究人員、開發者還是企業機構,都可以免費使用、修改、商用這套模型,而無需擔心繁瑣的授權限制。
對比此前一些AI模型帶有附加條款的「半開源」模式,Omnilingual ASR的開放姿態可謂十分坦蕩,為技術民主化樹立了榜樣。
為了讓各語言社區都能受益,Meta不僅開放了模型,還同步釋放了一個巨大的多語言語音數據集——Omnilingual ASR語料庫。
該語料庫包含了350種語料稀缺的語言的轉錄語音數據,覆蓋了許多以前在數字世界中「失聲」的語言。
所有數據以CC-BY協議開放提供。
開發者和學者可以利用這些寶貴資源,去訓練改進適合本地需求的語音識別模型。
這一舉措無疑將幫助那些缺乏大規模標註語料的語言跨越數據門檻,讓「小語言」也有大作為的機會。
Omnilingual ASR能夠囊括前所未有的語言廣度,離不開全球合作的支撐。
在開發過程中,Meta與各地的語言組織和社區攜手收集了大量語音樣本。
他們與Mozilla基金會的Common Voice項目、非洲的Lanfrica/NaijaVoices等機構合作,從偏遠地區招募母語人士錄製語音。
為確保數據多樣且貼近生活,這些錄音往往採用開放式提問,讓說話人自由表達日常想法。
所有參與者都獲得了合理報酬,並遵循文化敏感性的指導進行採集。
這種社區共創的模式賦予了Omnilingual ASR深厚的語言學知識和文化理解,也彰顯了項目的人文關懷:技術開發並沒有也不應該居高臨下地「拯救」小語種,而是與當地社區合作,讓他們自己成為語言數字化的主角。
技術規格上,Meta提供了一系列不同規模的模型以適配多樣化的應用場景:從參數量約3億的輕量級模型(適合手機等低功耗設備)到高達70億參數的強力模型(追求極致準確率)一應俱全。
模型架構採用自監督預訓練的wav2vec 2.0語音編碼器(拓展到70億參數規模)提取通用音頻特徵,並結合兩種解碼器策略:一種是傳統的CTC解碼,另一種則是融入Transformer的大模型文本解碼器,後者賦予了模型強大的上下文學習能力。

龐大的模型需要海量數據來支撐——Omnilingual ASR訓練使用了超過430萬小時的語音音頻,涵蓋1239種語言的素材。
這是有史以來最大規模、多樣性最高的語音訓練語料之一。如此大體量的數據加上社區貢獻的長尾語言語料,確保了模型對各種語言都學到穩健的語音表示,甚至對完全沒見過的語言也有良好的泛化基礎。
正如研究論文所指出的,「沒有任何模型能預先涵蓋世界上所有語言,但Omnilingual ASR讓社區能夠用自己的數據持續拓展這份清單」。
這標誌着語音AI從此具備了自我生長的生命力,能夠與人類語言的豐富多樣性共同進化。
當技術放下傲慢,以開源姿態擁抱多元,當每一種語言的聲音都有機會被聆聽和記錄,當沒有任何一種語言被數字世界遺忘,我們離真正消弭語言鴻溝又近了一大步,人類的連接才能真正開始消除邊界。
參考資料:
https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition