
「VLA只是一個過渡方案。」
作者|劉楊楠
編輯|王博
2021年底,商湯科技在港交所敲鐘上市。這個時刻像整個計算機視覺行業的一次成人禮,意味着此前數年的狂歡與爭議,終於有了一個暫時的落腳點。
作為商湯智能汽車事業羣的靈魂人物,時任商湯絕影智能雲研發總經理武偉,見證了十年來商湯從0起步,一路輾轉上市的全部經過。可在商湯上市敲鐘那一刻,他意識到自己正來到新的岔路口。
「我喜歡初創公司的氛圍,大家在一個相對未知的領域快速試錯,去突破新技術,直到它真正在產業落地發展。」武偉說。於是,他開始思考自己的下一站該往何處。或是加入某個初創團隊,或是乾脆自己再創業一次。
直到2022年的CVPR上,武偉碰巧和特斯拉團隊做了一次技術交流。當時他們默契地意識到,世界模型是AGI的新基建。
三年後,武偉做出了選擇。他告別自己一手打造的「絕影」,在2025年5月創辦流形空間(Manifold AI)。他又站上了一個全新的技術風口。

Manifold AI流形空間創始人兼CEO武偉
流形空間成立3個月便連獲種子輪以及天使輪兩輪共億元孖展,成為了世界模型領域一匹「黑馬」。
「Manifold」在數學領域被直譯為「流形」,這是一種又簡單又通用的幾何結構。它在局部簡單到可以被線性化,在全局又通用到足以描述複雜的高維空間。數學出身的武偉,正試圖找到一種「既簡單,又通用」的方案,打造一個能理解並預測物理世界的大腦。
這是一個近乎完美的技術理想,但當下的世界模型賽道實在太過複雜。技術仍在早期,一切尚未收斂,市場熱鬧程度堪比2023年初LLM的「百模大戰」。
就在今天,斯坦福大學教授李飛飛的一篇長文《From Words to Worlds: Spatial Intelligence is AI’s Next Frontier(從詞到世界:空間智能是AI的下一個前沿)》,引發了整個硅谷對空間智能、世界模型的討論。李飛飛提出世界模型要具備的三項能力:Generative、Multimodal、Interactive(生成式、多模態、交互性)。
李飛飛認為,下一代世界模型將使機器在全新的層面上實現空間智能——這將解鎖當今AI 統仍大多缺失的關鍵能力,使用世界模型將為人們構建更美好的世界。
世界模型概念火熱,但押注世界模型的廠商必須給外界一個充分的理由,吸引更多資源湧入這個年輕的領域,纔有可能讓願景成為現實。
而武偉當下要做的,便是在明確的技術理想和不確定的市場環境之間,維持一種微妙的動態平衡。
1.世界模型與VLA之爭

武偉被問過最多次的問題,就是「為什麼世界模型比VLA更優」 。
在當下的具身智能領域,世界模型和VLA(Vision-Language-Action)模型是一對「影子對手」。二者常被相提並論,也各自收穫了大批信徒。但之所以稱之為「影子對手」,是因為這種對比本身難以成立。
在商業世界,脫離場景需求談技術優劣約等於「耍流氓」。再偉大的技術創新,都難免需要通過服務各行各業,來找到其世俗意義上的「產業價值」。
世界模型和VLA本質是在用不同的方式解決同一件事——讓機器理解人類的抽象指令,將其轉化為在複雜現實世界中可以執行的具體物理動作,並完成任務。
武偉認為,VLA本質是將高維度的視頻域降維到語言域,將視頻與文本指令對齊,再通過大量的機器人經驗數據(如軌跡數據、動作數據)進行對齊和訓練,讓機器能夠讀懂語言指令,並基於模仿學習高效、可靠地完成具體任務。其範式本質是基於已有VLM基座模型在做「機器翻譯」任務的「後訓練」。
他認為,這種訓練方式會造成兩個弊端。
一方面,VLA模型在訓練時與特定的機器人本體強綁定。換一個機器人形態,例如從人形機器人換成四足機器狗,甚至是換一種機器人本體構型,模型就需要大量後訓練數據重新適配,部署成本高昂。
另一方面,VLA模型只是「知其然」,但「不知其所以然」。其本質是通過大量模仿學習到某種經驗,並在需要的時候將經驗復刻出來。它只能執行它見過的動作,當遇到訓練數據中從未出現過的、需要推理和規劃的新穎場景(即長尾問題中的長尾),它會束手無策,它無法預測一個動作的連鎖反應。
而世界模型,則是反其道而行,它將語言升維到視覺域 。它是一種可以模擬所有場景的生成式模型 ,通過學習海量世界知識,讓模型理解世界的因果規律,產生「Dreaming(想象)能力」。
在武偉看來,在實際應用場景中,這種預測能力通過兩種路徑體現。
一種是作為Agent Model(智能體模型),通過在線的模擬和推演獲得更優決策。
他舉了一個生動的例子:「我看到一個人在哭,我該怎麼辦?」 VLA可能只會基於模仿學習的經驗回放給出一個模式化回答;但世界模型會進行推演:「如果我去安慰,對方可能會感激我。」這個推演過程,就是世界模型在進行在線模擬,以得到更好的決策。
一種是作為Environment Model(環境模型),通過離線強化學習使得物理智能體獲得更好的泛化能力。武偉希望世界模型成為一個Omni Simulator,即一個可模擬物理智能體交互環境的通用仿真器。
這種通用仿真器與傳統依賴圖形學的物理仿真引擎有本質區別,因為後者是「不可微」的 ,無法成為一個可學習、可持續進化的系統。
因此,在武偉的藍圖中,VLA只是一個過渡方案。
「世界模型是AGI的重要基建。與傳統AIGC不同,世界模型的目標不是還原現實,而是通過預測環境變化來做出更優決策。世界模型讓AI第一次具備了心智推演能力——能在腦中模擬因果、預判後果、優化行動。」武偉告訴「甲子光年」。
總的來說,世界模型的心智推演能力,也就是Dreaming能力,本質上依然是一種強大的預測能力。這種能力讓世界模型在理論上更能夠以更經濟的方式,實現跨本體、跨場景的泛化。這也是現階段,以武偉為代表的一派認為世界模型優於VLA的根本原因。
理論上證明可行性後,接下來的課題,就關於「如何做」。
2.世界模型的技術混戰
世界模型是一個極其年輕的戰場,最早可以追溯到2018年的論文《World Models》。
這篇文章中提出了「Mental Model」的概念,通過一個RNN對世界狀態進行建模,將其編碼進隱空間(latent space),再通過隱空間進行狀態的迭代預測。
到了2024年,這個方向迎來真正的爆發。OpenAI的Sora成為第一個具備文生視頻能力的深度學習模型。自此,AIGC技術路線開始與「視覺世界模型」深度融合。
整體上看,武偉將當下的技術脈絡大致歸納為兩大派系。
一派是顯式物理建模,即用模型復現世界。這一派系的目標是生成與真實物理世界一致的視頻形態的可交互空間。
代表性選手之一就是Google Genie系列,以自迴歸技術路線為主幹,將視頻和動作(latent action)進行tokenize,轉化為離散的token,再通過自迴歸模型訓練。
另一個代表性玩家就是斯坦福大學教授李飛飛創辦的WorldLabs。
今天,李飛飛從空間智能的角度,系統闡述了她對「世界模型」的定義,在業內很受關注。她認為,一個真正具備空間智能的世界模型應具備三項核心能力:生成式(Generative),能生成具有幾何與物理一致性的世界;多模態(Multimodal),能處理並理解圖像、視頻、文本、動作等多種形式的輸入;交互性(Interactive),能根據輸入的動作預測世界的下一個狀態。在她看來,這是讓AI超越語言理解,真正連接想象、感知與行動,從而解鎖創造力、機器人學和科學發現的關鍵。
《From Words to Worlds: Spatial Intelligence is AI’s Next Frontier》,圖片來源:李飛飛博客
而在技術策略上,武偉認為,WorldLabs的方法和Google略有不同,採用了Geometry Forcing(幾何強迫)或「物理注入」的方式。它們在數據標註階段就引入了稠密點雲、三維一致性等顯式物理信息 ,強行將物理約束注入訓練,從而生成更具3D一致性的場景。
一派則是隱空間交互。這一派系的目標不是復現世界,而是訓練出一個能與世界交互的智能體。
Google Dreamer系列是這一派系中最具代表性的工作 。其核心思想是通過世界模型將真實世界壓縮到一個「隱空間」(latent space)。在這個虛擬的隱空間裏訓練智能體。
這條路徑讓Dreamer v3真正擁有泛化能力,其在一個遊戲(如Atari)中訓練後,無需修改參數,就能直接部署到一個全新的、從未見過的遊戲環境裏完成泛化 。
Dreamer系列之外還有另一條路徑,就是Meta的V-JEPA系列。它本質上也是在構建一個空間世界模型,同樣是在隱空間中進行表徵推演。
但與Google的Dreamer依賴強化學習去逼近最優策略不同,V-JEPA系列引入了一個新的思路:通過sampling(採樣)與能量函數評估的方式,去搜索最優的執行狀態。因此,它不再僅僅依賴強化學習去做最優策略逼近,而是在能量空間中尋找最優解,這是一種更「可解釋」、物理一致性更強的智能體建模方式。
這種方法下,V-JEPA2可以利用海量的視頻數據,尤其是第一人稱視角視頻數據,再加上少量的機器交互數據訓練出一個世界模型。
儘管進展迅速,但武偉認為現有路徑存在共同短板,即任務適應性不強,且跨尺度泛化能力弱,也就是一個為自動駕駛訓練的模型,無法用於室內機器人。
流形空間要做的,就是能在不同尺度之間遷移與統一的「具身世界模型」。
武偉告訴「甲子光年」,Google、WorldLabs等國外團隊對世界模型的研發策略更多是「Top-down」(自上而下),甚至很多是出於學術研究,而非產業落地。相比之下,國內尤其初創企業更適合採用「Bottom-up」(自下而上)路徑,這更像特斯拉的路線,即先做領域模型,同時做一些落地應用,通過場景反饋數據不斷完善模型能力,進而訓練基座模型,在循環往復,不斷優化上層的領域模型,形成數據飛輪。
目前,流形空間自稱是全球唯一佈局全域世界模型的團隊 ,團隊成員早期參與研發了自動駕駛世界模型DriveScape,近期又自研了機器人場景的RoboScape和無人機場景的AirScape。
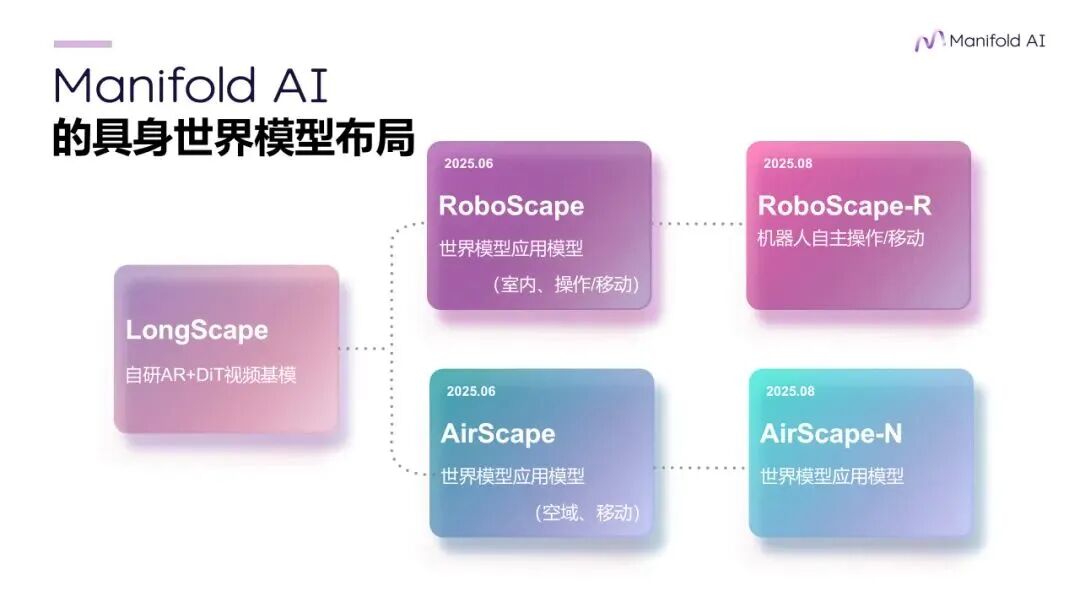
這些領域模型均基於自研的LongScape架構,結合了Auto-regressive+DiT混合建模。因為架構相對同構 ,它們能被方便地用MoE的方式「混合」成一個更通用的基座模型。
武偉坦言,如何用世界模型實現具身智能這件事,目前還沒人想清楚,大家都在自己的技術理解中摸索一些可行路徑。而流形空間最為與衆不同,甚至優於VLA的核心,就在於一個關鍵決策:選擇從預訓練開始做起 。
3.一定要做預訓練嗎?
當下,絕大多數VLA甚至世界模型,都是在已有的視頻或語言模型上做「後訓練」。
「你如果沒有一個很好的預訓練,或者說模型沒有在預訓練中獲得Dreaming能力,那麼它在沒有見過這種樣本的數據之上,它其實並不知道物理世界的運行規律是什麼樣。」武偉解釋道。由此導致的結果就是,模型需要很多的後訓練數據去補充,導致模型的部署成本很高。
流形空間則試圖通過預訓練,讓模型真正學習到物理世界的先驗知識,理解因果規律。
「在我們的方案裏面,世界模型有個比較好的預訓練,它見過幾乎人類所有的動作空間和任務完成的數據。」武偉說 。當這個擁有強大先驗知識的基座模型去適配一個新的機器人本體或場景任務時,後訓練所需要的數據量就會更少,這會大大降低模型的部署成本。
這個選擇實則也是從GPT的成功中汲取了靈感。武偉回憶,在GPT出現前,AI需要為翻譯、客服、QA等不同任務單獨訓練模型。而OpenAI通過海量預訓練讓模型獲得了強大的先驗知識,使其在下游任務上僅需few-shot(少樣本)甚至zero-shot(零樣本)就能完成任務。
為了實現這個目標,流形空間在數據管線、模型架構設計以及訓練方法上均有相應創新。
在數據方面,武偉坦言,由於技術完全沒有收斂,並沒有相關標準明確規定什麼樣的數據更適合訓練世界模型。
流形空間的做法是,整體數據構成是70%的互聯網數據和30%的真機採集。其中,互聯網數據也有嚴格的篩選傾向。流行空間選擇用大量ego-centric(第一人稱視角)數據,因為它和機器人的推理domain差異更小。同時,用於訓練世界模型的數據最好能包含更多任務數量,這對數據的variance(方差)更有幫助。一個值得注意的細節是,流形空間還更傾向於使用帶有失敗狀態恢復的數據,這會增強模型的糾錯能力。
在模型的架構設計和訓練方法上,流形空間提出的具身基座模型強調Reasoning(推理)、Dreaming(想象)、Acting(執行)三位一體的能力。
武偉解釋道:「世界模型通常僅強調Dreaming能力,但對於具身基座世界模型,Reasoning和Acting同樣重要。Reasoning能力代表具身智能體的思維鏈,有助於解決常識問題;Acting是一種特殊的Dreaming模態,是具身智能體優化的最終目標。」
實現這三種能力的協同提升,是目前世界模型面臨最大的技術挑戰。因為三種模態的數據本身是異構的,要讓它們的能力同步提升,就涉及大量架構設計和訓練技巧。這些複雜的工作都需要在預訓練中完成,才能最大程度降低後期模型在實際部署中的難度和成本。
武偉表示,傳統的視頻生成模型雖然也經過大量預訓練,但其對於每一幀畫面中的「主體」關注度不夠,而是會關注每一幀畫面中的所有細節,很難把算力用在最需要的地方。
流形空間則採用創新方案,在視頻生成質量和動作(action)質量之間建立起一種正相關。這使得模型在訓練中,Dreaming能力的提升可以一致的反饋到動作質量的提升上來。
「我們應該是業內首個能做到這一點的。」武偉表示。實現這一點後,流形空間接下來的目標十分明確,就是要同步探索世界模型的產品化。這是一家初創企業為了走得長遠所產生的必然選擇。
4.攀登高峯,沿途下蛋
在公司發展戰略上,武偉的策略非常務實,他將其總結為一句中國創業圈的黑話:「攀登高峯,沿途下蛋」。
「攀登高峯」是做出通用的具身世界模型基座;「沿途下蛋」則是在這個過程中,將RoboScape、AirScape等領域模型(Sub-domain)提前做一些產品化和商業化 ,以產生營收,支撐團隊走得更遠。
在落地場景上,武偉做出了一個出人意料的決定:優先考慮機器人和無人機領域,但不會考慮自動駕駛。
這在外人看來是種反差,畢竟他曾是自動駕駛領域的頂尖玩家 。但武偉的想法異常清醒:「並不是說世界模型在自動駕駛這塊作用不高,反而它作用其實還是比較高的」 。
他放棄的原因在於產業結構。武偉判斷,自動駕駛產業正在產能出清,巨頭正在形成和收斂。在這個階段,算法迭代只是環節之一,差異化有好似更多的是這麼多年的工程化的部署以及和合作伙伴的一些深度的協同。
相比之下,機器人和無人機市場更加碎片化 。武偉認為,「人有多少工種就會有多少工種的機器人」 ,這個市場能容納更多的玩家。
更重要的是,具身智能是一個強調軟硬件綜合能力的賽道,從自動駕駛過往的行業經驗來看,大廠在軟硬件系統的打造上並未體現出太大優勢。
「大廠更擅長ToC、偏軟的事情,而具身是偏軟硬一體的、更碎片化的市場。自動駕駛領先的地平線和Momenta是創業公司,無人配送的新石器也是創業公司,都不是大廠孵化的。具身需要很強的落地部署和軟硬件系統工程能力,這不一定是大廠擅長的,組織大了對新技術反應反而慢,這都是創業公司的機會。」武偉分析道。
具體來看,在無人機和機器人領域,流形空間將重點放在如何讓硬件本體擁有自主推理能力上。

基於RoboScape的機器人預測執行能力

基於AirScape的無人機預測執行能力
武偉表示:「現在機器人和無人機主要還是人類控制階段,無人機出貨量雖大但主要靠人工飛手控制;機器人硬件快速發展,但更多還是用遙控器操作。我們聚焦往智能化、自主推理方向發展。」
不過,武偉預計,長期來看,世界模型產品化還有一個關鍵前提,就是輕量化。流形空間已經將模型量化蒸餾部署到邊緣端的推理系統中,能驅動機器人自主移動操作和無人機自主導航。武偉表示:「我們從算力角度選擇了英偉達的芯片,未來也會考慮國產芯片作為多元化選項。」
事實上,從流形空間目前的業務版圖來看——世界模型的預訓練、不同的領域模型以及世界模型的產品化,每一項都是一個行業級別的複雜課題。從創業公司目前的體量來看,要真正做到「攀登高峯」的同時「沿途下蛋」,十分考驗掌舵者的能力。
5.用數據驅動的方式做事
畢竟,創業不比在大公司做高管,除了思考如何「做事」,更大的挑戰在於如何處理「人」和「錢」的問題。
從千人規模的龍頭高管,到幾十人規模的初創公司CEO ,武偉的心態也在轉變。他的團隊可劃分為兩隊人馬,一隊是工業界老司機,一隊是天才00後。相比砸錢挖人,他更注重人才的密度,而不是數量。
他甚至把AI的訓練思維遷移到團隊管理上,要用「數據驅動」的方式來做事。
傳統的管理像是「監督學習」,而他更傾向於「強化學習」。
「如果這個團隊的同學能夠完成這件事情,得到一個正向的結果,那你其實就應該鼓勵這種成果,要及時地給出一個reward(獎勵),用類似強化學習的方式,讓整個團隊逼向最優解。」 武偉告訴「甲子光年」,「你不能強行讓天才00後都聽‘老司機’的想法,讓他去避坑,這樣有一些閃光點反而會被埋沒掉。」
目前,流形空間已獲得了億元級別的孖展,並計劃在2025年底至2026年初,正式發布其第一代基於WMA路線的基座模型。武偉透露:「我們希望成為產品驅動的公司。整體孖展節奏還是與產品研發節奏匹配。」
對於公司的長期規劃,武偉有着嚴肅的思考。他希望流形空間能「推動Physical AI Agent向前一大步」 ,並希望公司「自研加上賦能的機器人數量超過市場總量的10%」。
正如他引用物理學家費曼的那句名言:「如果我不能創造它,我就無法理解它。」