IT之家 11 月 16 日消息,科技媒體 golem 昨日(11 月 15 日)發布博文,報道稱谷歌通過其 AI Studio 平台,正測試一款尚未命名的 AI 模型,在破譯難以辨認的歷史手稿方面已接近人類專家的水平。
IT之家援引博文介紹,歷史學家 Mark Humphries 使用一套專門開發的基準數據集,系統性地測試了該模型的性能。結果表明,在處理五份高難度歷史手稿時,該模型的整體字符錯誤率約為 1.7%,其中大部分錯誤涉及標點符號和大小寫,而非單詞本身。
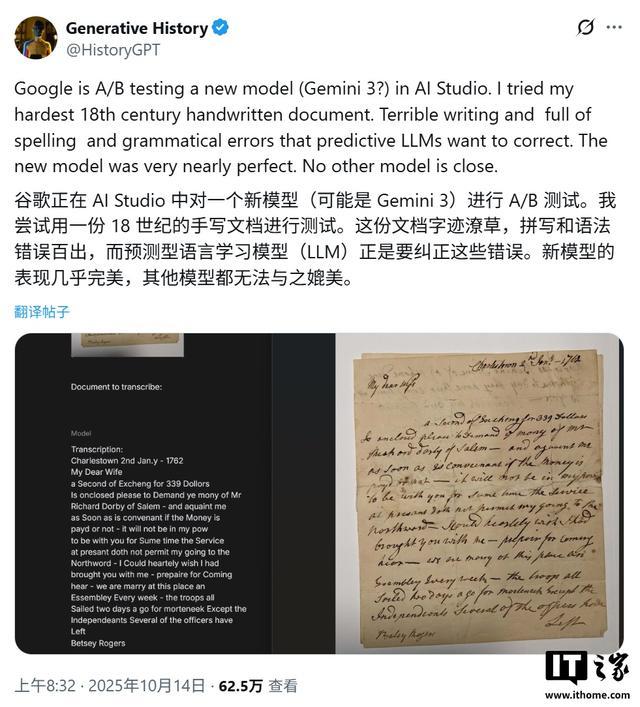
Humphries 的評估進一步指出,如果排除模糊的標點符號和大小寫錯誤,該 AI 模型的字符錯誤率將驟降至約 0.56%,相當於每轉寫 200 個字符纔出現一個錯誤。

根據新發現的未知 Gemini 型號轉錄的奧爾巴尼賬簿頁面
這一驚人的準確度,讓其性能足以與從事歷史文獻轉寫的專業人類工作者相提並論。此次測試的文檔涵蓋了 18 至 19 世紀的多種手寫風格,其中不乏字跡潦草、拼寫錯誤和語法不一致的複雜樣本,進一步凸顯了該模型的強大能力。
該模型最令人意外的表現,是其超越了簡單的文字轉寫,展現出複雜的推理能力。在處理一份 18 世紀商人的日記時,原文中有一條關於購買糖的記錄,僅標記了數字「145」,並未註明計量單位。
谷歌的 AI 模型並未直接轉寫為「145」,而是輸出了「14 磅 5 盎司」。研究人員發現,AI 是通過反向計算賬本中記錄的總價,並結合當時英國的貨幣(磅、先令、便士)與重量單位關係,才成功推斷出這一結果。

儘管初步結果令人振奮,但 Humphries 也強調了當前評估的侷限性。由於該模型通過 A/B 測試形式零星出現,系統性地進行大規模測試存在困難,目前僅評估了基準數據集中約 10% 的樣本。
