文|極智GeeTech
近日,圖靈獎得主、Meta首席AI科學家楊立昆(Yann LeCun)被曝將離職創業,將以「世界模型」(World Models)為技術核心,延續其深耕多年的探索方向,這一動作迅速引發全球AI圈的關注。
「AI教母」李飛飛在自己的社交平台發布萬字長文,直指當下大語言模型(LLM)的算力穹頂與認知侷限。她提出,AI 的未來不在於模型參數的無限擴容,而在於植入 「空間智能」(Spatial Intelligence)—— 這種人類先天具備、嬰兒階段即覺醒的基礎認知能力,纔是通往通用人工智能(AGI)的必經之路。
與此同時,李飛飛創立的 World Labs於11月13日推出首款產品Marble,以多模態世界模型為核心引擎,可從單張圖像、視頻片段或文本描述中,生成具備持久性的三維數字孿生空間,為空間智能搭建起關鍵的三維認知基座。
當AI從純虛擬語境切入物理現實維度,現實世界的複雜約束與動態交互,正呼喚一套顛覆性的認知模型破局。

一場關於AI本質的路線分歧
Yann LeCun在Meta任職12年,其技術願景與扎克伯格主導的大語言模型路徑存在分歧已不是祕密。
他曾公開表示:「大語言模型永遠無法實現人類推理能力。」這句話直指AI發展的核心矛盾:究竟該用文本數據訓練出更會聊天的機器,還是讓AI像嬰兒一樣通過視覺觀察學習物理規律?
一直以來,大語言模型受制於數據質量和數據規模,其認知邊界始終被訓練數據的「無形圍牆」所束縛。
數據偏見會固化模型的認知偏差,噪聲數據直接稀釋推理精度,而時效性滯後則讓模型困於「信息時差」,難以捕捉現實世界的動態演進。即便持續擴容數據規模,參數堆砌也逐漸陷入「規模魔咒」,算力消耗與效果增益呈現非線性失衡,邊際效益持續遞減。
更核心的桎梏在於,大語言模型的認知侷限於文本符號的線性關聯,缺乏對物理世界的三維空間建模能力與動態因果推理能力。它無法精準映射現實世界的空間拓撲、物體屬性與運動規律,也難以理解「行動-反饋」的實時交互邏輯,導致在跨場景落地時頻繁出現認知斷層。
Yann LeCun比如無法通過文本描述精準還原立體場景,亦不能基於現實約束做出符合物理常識的決策。
這種依賴文本數據餵養的模式,終究難以突破「符號牢籠」,無法復刻人類從具象體驗中提煉抽象知識的認知路徑。
當AI需要從虛擬交互走向物理世界的實際應用,從單一任務響應升級為複雜場景的自主決策,純文本驅動的模型架構已難以承載通用人工智能的進化需求,唯有跳出數據規模競賽,轉向對世界本質的結構化理解,才能開啓下一段技術躍遷。
「世界模型派」普遍認為,大語言模型存在根本侷限。李飛飛強調,語言是人類為交流創造的抽象信號,自然界本無文字,AI若僅依賴文本,無法真正理解物理世界規律,易淪為「黑暗中的文字大師」。
Yann LeCun多次批評大語言模型僅為強大文本數據庫,缺乏對現實世界的理解能力。世界模型則致力於通過高維感知數據直接建模,繞開語言轉換,在潛空間內推演物理規律,並輸出行動指令,實現對環境的內在理解與主動推理。
就像人類嬰兒不需要閱讀百科全書就能理解重力——他們通過眼睛觀察杯子墜落,用手觸摸桌面來建立物理世界的認知。這正是LeCun推崇世界模型的關鍵:動態視頻數據包含的時空信息,遠比抽象文本更接近智能的本質。
比如球撞倒積木的瞬間,既包含材質硬度信息,也隱藏着力學規律。而大語言模型從維基百科學到的「牛頓定律」,不過是符號的統計關聯。MIT的研究更證明,大腦處理空間認知時會激活特定神經網絡——這種生物本能,正是當前純文本AI缺失的底層能力。
「Word Models」一詞最早出現在2018年Jurgen在機器學習頂會NeurPS上發表的一篇名為《Recurrent World Models Facilitate Policy Evolution》的文章中,文章以認知科學中人腦的心智模型(Mental Model)來類比世界模型,認為心智模型參與了人類的認知,推理、決策過程,其中最核心的能力在於反事實推理。
該模型使AI具備預測與規劃能力,如理解物體破碎原理、預判車輛轉向軌跡,為具身智能、自動駕駛及人機協作機器人提供基礎支撐。李飛飛將其概括為讓「看見」升級為「推理」,「感知」轉化為「行動」,「想象」落地為「創造」。
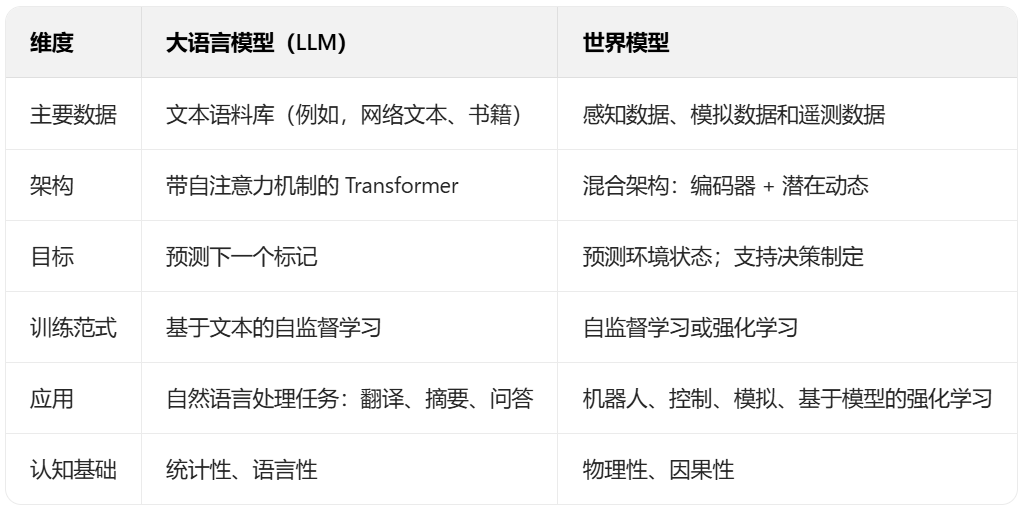
近年來,隨着深度學習技術的不斷發展和計算資源的增加,世界模型的研究取得了顯著的進展。
例如,2019年DeepMind發表的MuZero算法、2022年Yann LeCun提出的JEPA表徵模型、2024年的視頻生成模型Sora和城市環境生成模型UrbanWord等,都推動了世界模型在不同領域的應用探索。
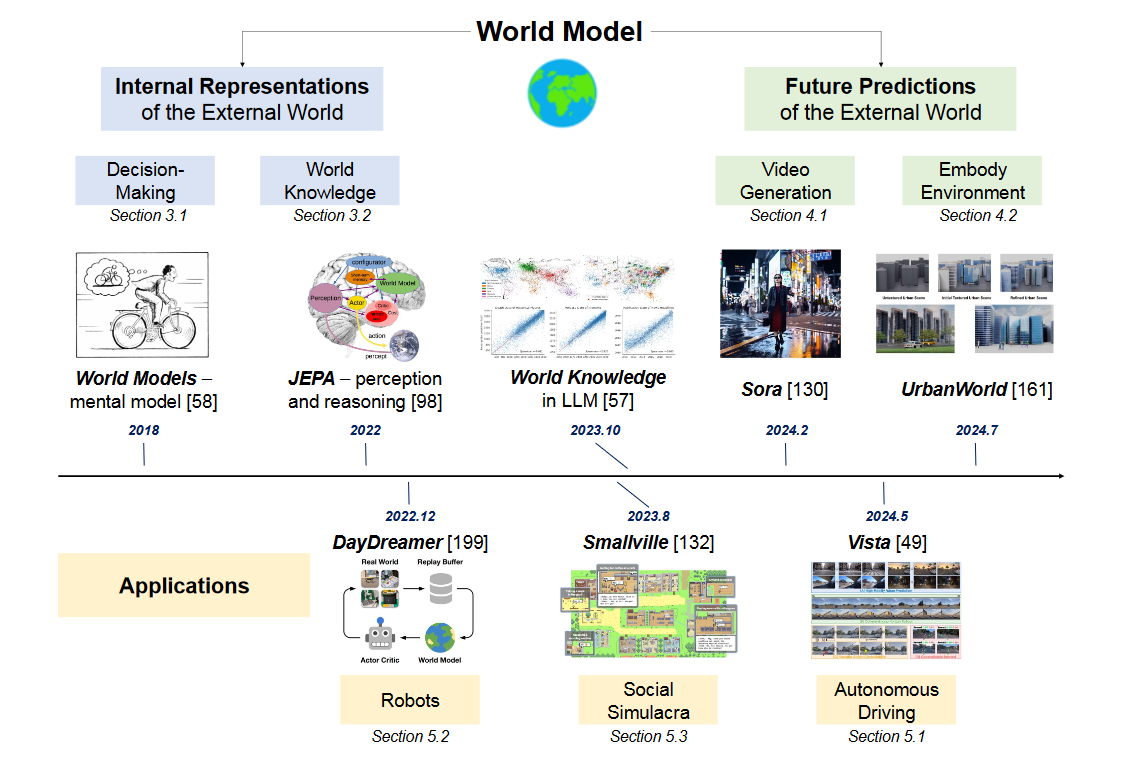
整體來看,世界模型是一種能夠對現實世界環境進行仿真,並基於文本、圖像、視頻和運動等輸入數據來生成視頻、預測未來狀態的生成式Al模型。它整合了多種語義信息,如視覺、聽覺、語言等,通過機器學習、深度學習和其他數學模型來理解和預測現實世界中的現象、行為和因果關係。
簡單來說,世界模型就像是A1系統對現實世界的「內在理解」和「心理模擬」。它不僅能夠處理輸入的數據,還能估計未直接感知的狀態,並預測未來狀態的變化。
這種模型使AI具備了類似人類的認知和推理能力,能夠在一個虛擬的「腦海」中進行模擬和規劃,從而更好地應對現實世界的複雜性。
區別於寬泛意義上的大語言模型,世界模型並非通過可獲取的語言、圖像及視頻來理解現實場景,而是通過大量數據學習現實世界的物理規則,實施因果推理,從而預測、生成合乎現實規律的未來。其終極目的在於,通過訓練讓人工智能適應現實世界而非理論世界,讓AI進化為物理AI。
世界模型具有三大核心特點:
其一,內在表徵與預測。世界模型可以將高維的原始觀測數據(如圖像、聲音、文本等)編碼為低維的潛在狀態,形成對世界的簡潔而有效的表徵。在此基礎上,它能夠預測在給定當前狀態和動作的情況下,下一個時刻的狀態分佈,從而實現對未來事件的前瞻性預測。
其二,物理認知與因果關係。世界模型具備基本的物理認知能力,能夠理解和模擬物理世界的規律,如重力、摩擦力、運動軌跡等。這使得它在處理與物理世界相關的問題時,能夠提供更準確、更符合現實的預測和決策支持。
其三,反事實推理能力。世界模型不僅能夠基於已有的數據進行預測,還能夠進行假設性思考,即反事實推理。例如,它可以回答「如果環境條件改變,結果會怎樣」這類問題,從而為複雜問題的解決提供更多的可能性和思路。
通常,一個完整的世界模型由狀態表徵模型、動態模型、決策模型三大組件構成。
狀態表徵模型的作用是將原始觀測數據(如高維圖像、傳感器數據等)壓縮為低維的潛在狀態,保留關鍵信息,過濾噪聲。常見的實現方法是使用變分自動編碼器(VAE)等技術。這種壓縮和表示方式使得模型能夠更高效地處理和理解複雜的數據輸入。
動態模型是世界模型的核心部分,用於預測給定當前潛在狀態和動作時,環境的下一個狀態分佈。循環神經網絡(RNN)、長短期記憶網絡(LSTM)或隨機狀態空間模型(SSM)等通常被用來學習狀態轉移規律,從而構建對世界物理規律的隱式理解。
動態模型為智能體提供了一個虛擬的「沙盤」,使其能夠在其中進行模擬和試驗,而無需在真實環境中進行昂貴的試錯。
基於狀態預測,決策模型使用模型預測控制(MPC)或深度強化學習等方法,規劃最優的動作序列以達成目標。它根據預測的未來狀態來評估不同動作的價值或獎勵信號,從而指導智能體在環境中採取合理的行動。
AI下一輪飛躍的引爆點
過去十年,AI的每一次躍遷都源自輸入方式的變革:文字帶來了語言智能,圖像催生了視覺智能。而如今,世界模型正在讓AI理解現實世界,一個有時間、有空間、有因果的動態系統。
不僅人工智能的先驅們幾乎一致認為,世界模型對打造下一代人工智能正至關重要,科技巨頭們也將世界模型視為人工智能發展節點上的關鍵。
近幾個月,多家科技公司相繼發布了在世界模型領域的進展,凸顯了這一賽道的升溫。
谷歌DeepMind的Genie系列模型在一年半內從2D升級至Genie 3,該模型可實時生成交互式3D環境。輸入一句話,即可在720p分辨率下創建用戶可自由探索的動態世界,場景細節能在長達一分鐘的記憶中保持連貫。Genie 3項目聯席負責人Shlomi Fruchter表示,通過構建模擬真實世界的環境,可以用更具擴展性的方式訓練AI,且「無需承擔在現實世界中犯錯的後果」。
Meta發布代碼世界模型(Code World Model),探索如何使用世界模型改進AI代碼生成性能。該模型不只會寫代碼,而是能像程序員一樣思考。CWM通過5T tokens的執行軌跡數據訓練,能逐行模擬代碼運行過程,從變量初始化到循環迭代,從函數調用到異常拋出,每一步狀態變化都能精準預測,直接將AI編程從靜態文本生成推向動態執行推理的新紀元。
與此同時,芯片巨頭英偉達的首席執行官黃仁勳斷言,公司的下一個主要增長階段將來自「物理AI」,這些新模型將徹底改變機器人領域。英偉達正利用其Omniverse平台創建和運行此類仿真,以支持其向機器人領域的擴張。
特斯拉CEO馬斯克可以說是最早拋出「世界模型」這一說法的人士之一。特斯拉為了實現全球範圍內所有路況的自動駕駛,在感知跟決策中間,嵌入了一個AI模型,主要是構建一個虛擬環境,以便進行自動駕駛能力的學習和驗證。
這種世界模型方法,其實已經對現實世界產生了潛在的巨大影響。風險投資公司Lightspeed的合夥人兼投資者Moritz Baier-Lentz表示,無人機戰爭、新型機器人和比人類更安全的自動駕駛車輛都正從中受益。
優步前AI業務負責人Gary Marcus指出,無論當今生成式人工智能接受多少數據訓練,它們只能建立世界運作的概率模型。本質上,當前人工智能學習的是輸入數據間的關聯性——無論是文字圖像,還是分子及其功能。這種對世界模糊的近似認知,似乎被混雜地編碼在AI「大腦」中,既包含數據本身,又包含大量關於數據處理的龐雜規則,而這些規則又往往殘缺不全或自相矛盾。
一個很好的例子是:一台運行1979年程序的雅達利2600遊戲機,可以在國際象棋比賽中擊敗最先進的聊天機器人。這些聊天機器人往往會嘗試非法走法,並很快忘記棋子的位置。本質上,當今基於Transformer架構的人工智能是在進行預測,而不是邏輯推理。儘管它們已經通過無數規則手冊的訓練,但仍然如此。
儘管世界模型展現出了巨大的潛力,但也面臨許多挑戰。
首先,是技術和生態層面的挑戰。構建世界模型需要大量的多模態數據,包括視頻、音頻、傳感器數據等,而這些數據的收集、標註和整理往往成本高昂且耗時費力。同時,數據的質量和多樣性也會直接影響模型的性能和泛化能力。
同時,世界模型也缺乏跨平台協同的工程體系配套。目前而言,世界模型沒有標準,缺乏統一的訓練語料、可比的評價指標與公共實驗平台,企業往往各自為戰。如果無法實現跨模型的可驗證性與可複用性,世界模型的生態就很難真正形成規模化創新。
其次,是認知層面的挑戰。世界模型的強大之處,在於它可以在內部推演與預測,但這也讓它的決策過程愈發難以被人類理解。試想一下,當一個模型能在潛在空間中模擬成千上萬種結果時,我們還能否追蹤它的決策邏輯?
從自動駕駛的責任歸屬,到自主智能之間,有沒有可能產生目標漂移(Goal Drift),進而延伸出AI的目標是否仍與人類一致的問題。一旦AI從被動執行轉為主動學習,安全與倫理的議題,也隨之從技術層面上升到價值層面。
第三,是產業和倫理層面的挑戰。世界模型的進一步發展,勢必重新定義產業邊界。AI不僅可能重構交通、製造、醫療、金融等領域的決策體系,也將催動算法主權、智能監管等制度議題。
中美雖然在路徑上各有偏重,美國憑藉資本與開放生態快速試錯,中國依託產業鏈協同推進落地,但雙方都面臨同一問題,當世界模型真正嵌入社會運行系統,它將以何種規則參與人類世界?
就目前而言,世界模型所依託的世界,仍然建立在人類提供的語料、規則與經驗上。但AI的持續進化,有賴於人類持續地在技術、倫理與治理層面為智能設定邊界,這會是一項長期的考驗。
必須承認,目前世界模型的研究仍處於早期階段。相較於適合快速迭代、短期內易於落地的VLA路線,世界模型代表了更底層的認知方式,強調物理規律和空間理解力,適合長期演進。
儘管挑戰顯著,但全球已在這一賽道展開競爭。但在這條平行賽道上,一場定義AI下一個十年的角逐已經鳴槍起跑,AI正在努力超越文本邊界,嘗試理解並重塑我們所在的物理世界。
可以肯定的是,世界模型的意義,絕對不是讓AI更像人,而是讓人類在AI的協同下,走向更遠的未來。