他是阿里巴巴最年輕的P10級技術負責人,也是全球最強開源模型之一——通義千問(Qwen)的核心推動者。他就是年僅 32 歲的AI界領軍人物——林俊暘。從北大課堂到達摩院實驗室,從算法代碼到開源生態,他用十年時間完成了從「讓機器懂語言」到「讓智能走進世界」的躍遷。
2025 年春,當全行業仍在爭論「開源還是閉源」「Agent 還是模型」「具身智能(Embodied Intelligence)是否為下一戰場」時,林俊暘已帶領團隊悄然開啓新一輪進化——讓智能從虛擬世界走向真實世界,從理解語言到學會行動。
與許多「算法天才」不同,他的成長路徑是一條更不尋常但極具邏輯的路線:北大本科學計算機,研究生卻選擇語言學與應用語言學——不是逃離理工,而是試圖回答一個更難的問題:「要讓機器懂人類語言、理解人類意圖,它首先要學會什麼?」正是這段語言學訓練,為他後來在大模型語義理解、多模態對齊,以及人機協同智能方向的突破,打下了別人少見的底層邏輯。
2019年畢業後,他沒有選擇學術,而是進入阿里達摩院智能計算實驗室,加入仍處於初期的多模態預訓練項目M6。一年後,通義千問立項,他成為核心架構成員;2022年正式升任技術負責人;2024年帶隊開源Qwen系列,在全球模型排行榜上與GPT、Claude正面交鋒;2025年,他又親自宣佈組建機器人與具身智能團隊,試圖讓模型走出螢幕,去「看世界、動手、行動」。

圖片來源:DataFun 2023
從語言學到大模型:一次詞彙測試中的AI啓蒙
公開資料顯示,他在本科階段主修計算機科學,打下了紮實的算法與編程基礎。但在碩士階段,他選擇進入北大外國語學院攻讀語言學及應用語言學相關方向。雖然他本人從未在公開採訪中解釋過為何跨入語言學領域,但不少業內人士認為,這並不是「離開技術」,而是將語言視為理解智能的入口——機器如果要懂人,它首先要懂語言背後的結構、語義和意圖。
從那時起,他的研究興趣逐漸從「語言是什麼」轉向「語言如何被機器理解」。在碩士期間,他參與多維度文本分類、注意力機制建模等項目,並申請了國家發明專利(CN109582789B),這是他首次將語言理論轉化為可計算框架的嘗試。外界據此推測,他後來在大模型時代迅速成為核心研發力量,正是源於這種「語言邏輯 + 工程實現」並存的底層思維方式。這段兼具理論與工程的積累,使他在2019年碩士畢業時,果斷放棄語言學學術道路,轉而投身人工智能研發的前沿領域。

圖片來源:林俊暘領英
入局多模態:達摩院的技術築基與賽馬突圍
畢業後的林俊暘徑直加入阿里巴巴達摩院,正式開啓職業生涯,擔任高級算法工程師。當時的人工智能領域正處於技術爆發的前夜。2020年,OpenAI發布GPT-3引發全球熱議後,阿里巴巴迅速啓動內部大模型研發的「賽馬機制」,同步推進兩條技術路線:主攻文本的AliceMind,以及側重多模態融合的M6。憑藉「語言學+技術」的複合背景,林俊暘被分配至周靖人領導的智能計算實驗室,成為M6模型團隊的核心開發者。
這支團隊在成立初期規模極小,僅由幾位資深工程師和實習生組成,卻承擔着國內少有的技術挑戰——如何讓模型同時理解文本、圖像等多模態信息,並實現高效訓練與落地。林俊暘主導的模型效率優化模塊成為關鍵突破點。他帶領小組攻克了大參數模型訓練中的資源調度與收斂難題,為M6的快速迭代奠定了基礎。
2021年,M6模型迎來三次重要躍遷:1月首發時達到百億參數規模,5月躍升至萬億級,10月再度突破至十萬億參數,成為當時國內參數規模最大的多模態預訓練模型。而支撐這一系列躍遷的核心架構優化,正出自林俊暘團隊之手。
2022年,阿里啓動AI資源整合,AliceMind團隊在內部賽馬中出局,M6技術路線被正式確立為集團通用大模型的核心方向。憑藉在模型架構設計與工程落地中的突出表現,林俊暘在阿里實現了快速晉升,從核心開發者升任項目主管,主導研發了通用統一多模態預訓練模型OFA(One-For-All,一體化多模態預訓練框架)與中文預訓練模型Chinese CLIP(中文視覺-文本匹配模型),進一步強化了阿里在多模態領域的技術壁壘。而這段早期經歷讓他切身領悟到「技術需與場景共生」的重要性,也為他後來主導通義千問系列的研發打下了堅實基礎。
圖片來源:林俊暘領英
掌舵通義:從旗艦模型到開源生態的戰略躍遷
2022年底,阿里巴巴將達摩院的語言、視覺等AI團隊整體併入阿里雲,成立通義實驗室。林俊暘被正式任命為通義千問系列大模型的技術負責人,全面負責核心模型研發與戰略規劃。他接手時面對的挑戰頗具代表性:如何把實驗室階段的技術成果轉化為真正可規模落地的商業產品,打破「技術先進卻難以應用」的困局。
2023年4月,阿里雲正式發布「通義千問」。其底層架構融合了林俊暘主導優化的多模態技術,這也是他在阿里多年來研究積累的成果。但他並未滿足於此。兩年後,在他的推動下,阿里推出Qwen3系列開源模型。旗艦版本Qwen3-Max擁有超萬億參數和36T預訓練數據,在GPQA、LiveCodeBench等權威評測中超越GPT-5、Claude Opus 4,躋身全球前三。
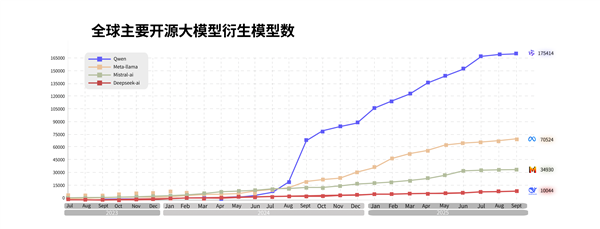
林俊暘在社交平台上寫道,團隊為此花費近一年時間,攻克了三項核心難題:「讓強化學習框架能穩定支撐長時序推理,平衡跨領域數據分佈以避免模型偏科,並強化多語言能力以服務全球開發者。」如果說「開源」是通義千問在大模型競爭中撕開的關鍵突破口,那麼截至2025年10月的一組數據,正印證了這步棋的深遠影響——阿里已累計開源300餘個通義系列模型,從小參數到超大模型全覆蓋,囊括文本、圖像、視頻等多模態能力;下載量突破6億次,衍生模型超過17萬個,中國企業大模型選用率達17.7%,穩居市場首位。
圖片來源:新浪科技
這些成果的背後,是林俊暘主導的「全尺寸覆蓋策略」。他深知,大模型的意義不僅在於「做大」,更在於「用好」。針對機器人、手機等算力受限的終端場景,他帶領團隊在2025年10月推出Qwen3-VL系列,專門設計了4B和8B兩個輕量化版本。令人意外的是,這些「小模型」的空間理解能力並不遜色於大模型,一經推出便成為具身智能公司爭相採用的核心基座,解決了「終端場景用不起大模型」的長期痛點。
在林俊暘看來,開源並非單純的代碼共享,而是一種面向未來的生態策略。當同行仍在權衡「是否該閉源保密」時,通義千問已通過全尺寸模型佈局,把技術的「種子」撒向機器人、移動端等不同場景。隨着越來越多企業基於通義進行二次開發,「用通義、改通義」正在成為行業習慣。一條獨特的生態護城河也在悄然形成——它不是靠技術壟斷維繫,而是通過讓更多人受益,實現技術生態的自我循環與生長。
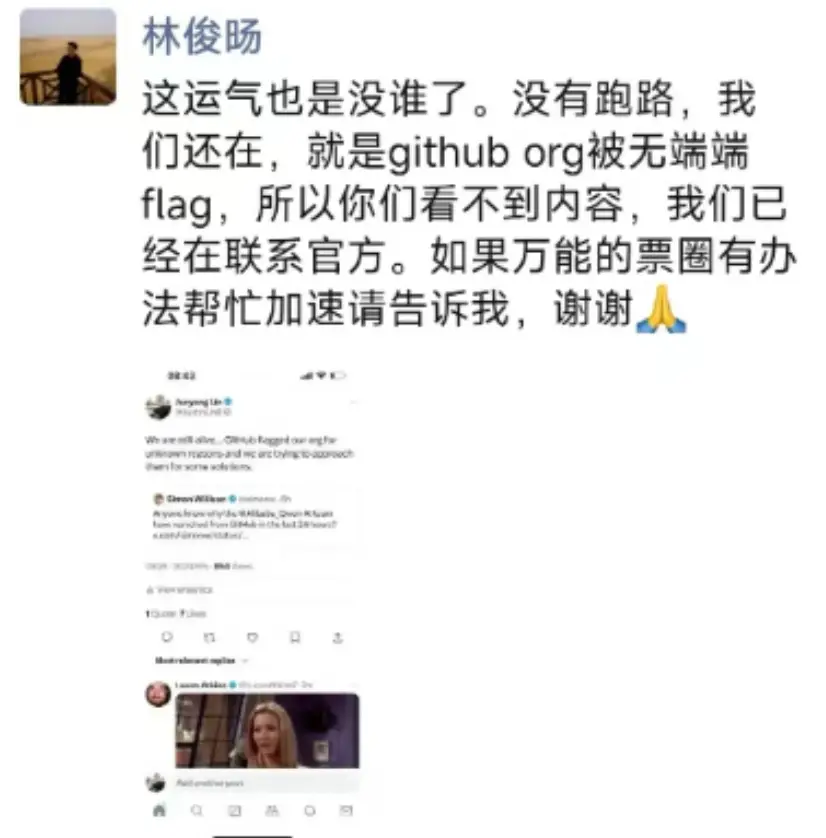
真正讓外界認識林俊暘的,是2024年的通義千問(Qwen)。那一年,隨着多版本模型相繼開源、阿里內部AI團隊的重組,以及GitHub風波引發的輿論關注,這位原本低調的技術負責人突然站到了聚光燈下。當Qwen項目代碼因誤標被GitHub「下架」引發外界質疑時,林俊暘親自出面回應:「團隊沒有跑路,我們還在,只是組織賬號被誤標記。」這句話,比任何公關聲明更能說明問題——冷靜、剋制、真實。
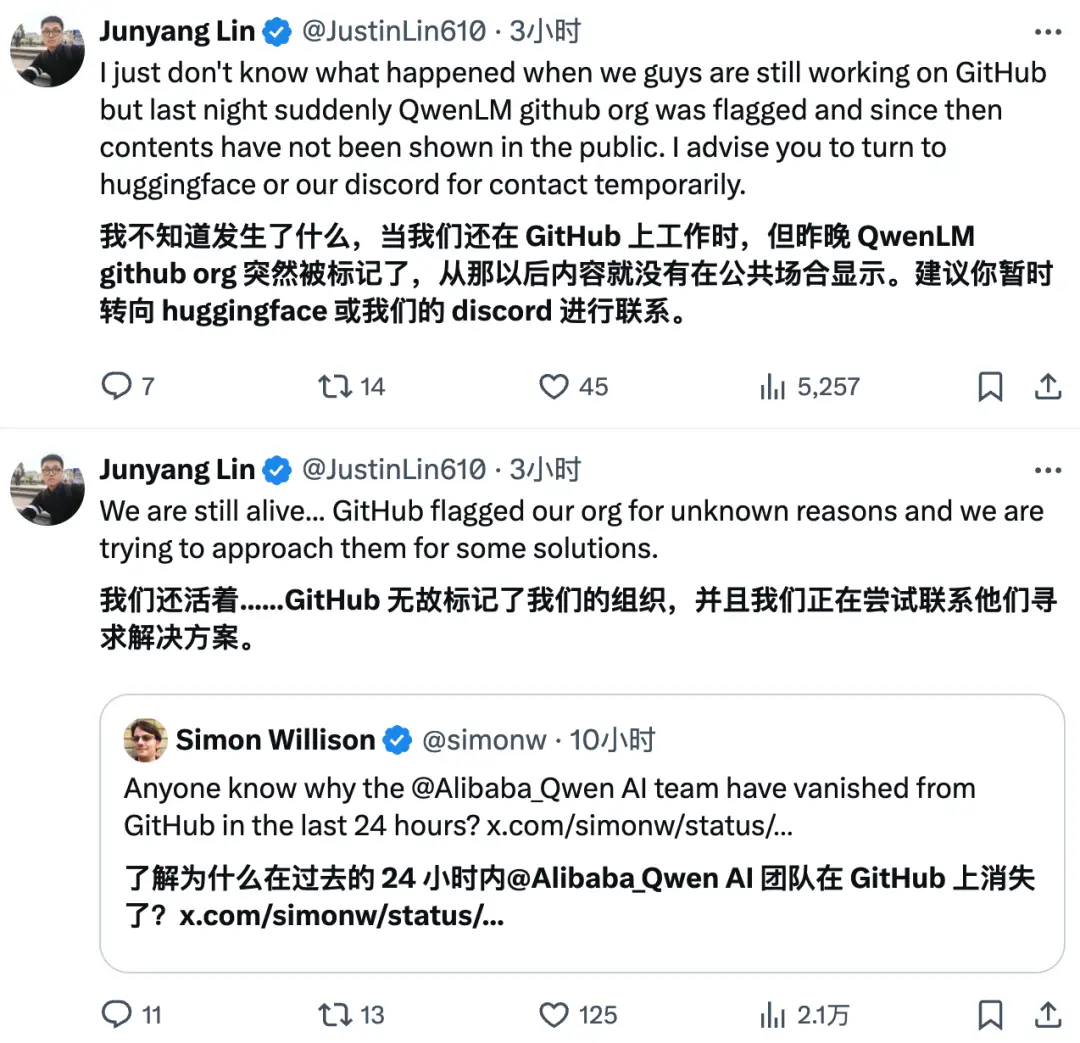
圖片來源:X
如今,隨着AI行業從「大模型競速」進入「生態與Agent能力」競爭的新階段,林俊暘依然站在變革的中心。他牽頭整合行業生態資源,聚焦Agent的人機協同能力打磨,將多年沉澱的人文思維與技術經驗融入其中,讓Agent更貼合真實場景下人的需求。他的經歷不僅是個人的成長史,也映照出新一代中國技術人的選擇:在喧囂的浪潮中,以長期專注和清晰目標,走出一條穩健、獨立的道路。
跨界物理世界:具身智能的閉環佈局與生態構建
2025年10月8日,阿里Qwen團隊核心負責人林俊暘在社交媒體上發布了一條簡短動態:「已在Qwen內部親手組建機器人與具身智能小組。」沒有隆重的發布會,也沒有冗長的技術白皮書,這一句話,足以在科技圈引發震動。它意味着阿里AI戰略正式轉向——從深耕多年的虛擬智能,邁向以「行動智能」為核心的物理世界。

圖片來源:華爾街見聞
這一步並非倉促決定。自2019年加入阿里巴巴達摩院以來,林俊暘一直站在公司AI研發的最前沿,主導了從語言模型訓練框架到多模態系統優化的多個關鍵項目,是通義千問(Qwen)體系的重要推動者之一。他長期專注於模型架構、跨模態理解與推理能力等前沿方向,其多篇論文發表於自然語言處理頂級會議(ACL、EMNLP、COLING等),並在學術界獲得廣泛引用。其中,《Scaling Laws for Multimodal Models》在Google Scholar上的引用量已超過千次,成為多模態模型效率研究的重要參考文獻。
正是這種從算法到底層應用的長期積累,讓林俊暘在通義千問取得階段性成果後,將目光從「讓機器理解文字」轉向「讓機器理解世界」。在他看來,具身智能是語言模型走出螢幕、進入現實的必然方向。正如他在一次內部會議中所說:「當語言模型真正具備感知與行動能力時,智能的邊界纔算被重新定義。」
外界普遍認為,林俊暘此舉標誌着阿里在大模型競爭格局趨穩後的一次主動求變;但對他本人而言,這更像是科研路徑的自然延伸——從語言理解到具身智能,從虛擬語義空間到真實世界的動作學習,他始終在追問同一個問題:AI的「智能」,究竟能走多遠?
林俊暘清楚地看到,行業正處在從「工具」邁向「Agent」的關鍵節點。「多模態基礎模型不再只是被動的回答系統,而正在成長為能調用工具、依託記憶、通過強化學習完成複雜推理的基礎Agent。」他曾在內部總結道,「這樣的智能,不該困在螢幕裏,它必須走向物理世界——去動手,去行動。」也正是這種對技術趨勢的敏銳判斷,成為阿里叩開「行動智能」時代大門的底層邏輯。
林俊暘的佈局,從一開始就帶着「軟硬協同、生態閉環」的清晰藍圖,每一步都踩在技術與產業的銜接點上。要讓AI在物理世界「行動」,首先得解決「怎麼想」的問題。林俊暘主導下的Qwen3系列,正在經歷一場「具身化改造」,目標是成為機器人的「核心決策中樞」:
•Qwen3-Max:化身「任務指揮官」。重點強化「複雜任務分解能力」,面對「拆快遞—分類物品—擺放收納」這類需要多步驟銜接的現實場景,它能像人類一樣拆解目標、規劃流程,確保機器人每一步操作都有明確指令,避免「卡殼」;
•Qwen3-VL:升級「立體視覺中樞」。專攻3D空間感知與動態物體追蹤技術——當機器人面對雜亂的桌面、移動的物體時,它能精準定位每一件物品的座標,預判物體運動軌跡,就像給機器人裝上了一雙「能看懂空間的眼睛」,完美匹配「視覺大腦」的核心需求。
林俊暘的這套佈局之所以能讓阿里在短時間內躋身具身智能賽道的核心玩家,關鍵在於他抓住了行業最真實的痛點。在正式組建團隊前,林俊暘帶隊走訪了三十多傢俱身智能企業,一個意外的發現讓他迅速確定了方向:幾乎所有公司都在使用Qwen-VL模型做後訓練。這意味着,阿里憑藉Qwen系列積累的技術優勢,已經在行業生態中佔據了「入口」位置——當這些企業需要進一步提升具身化能力時,阿里自然成為首選合作伙伴。
更重要的是,林俊暘並沒有停留在算法層面的突破,而是親自推動阿里構建出獨特的「具身智能生態閉環」。他主導將Qwen模型的能力延伸至阿里內部的真實業務場景——從淘寶的物流分揀、菜鳥的倉儲配送,到製造業生產線上的自動協作機器人——這些場景每天都在持續生成來自物理世界的高價值數據。
按照林俊暘的規劃,這些數據會被匯入阿里雲,為Qwen3模型的訓練與優化提供「養料」;經過更新的通義大腦再反向指揮機器人執行任務;而機器人完成任務後的反饋,又會重新進入模型訓練體系,形成一個自我進化的「智能飛輪」。這套機制讓阿里從具身智能的「探索者」迅速成長為「核心玩家」,也讓林俊暘在公司內部的技術佈局中確立了關鍵地位。從主導Qwen系列研發,到開闢「行動智能」的新方向,他始終堅持「技術先行、生態驅動」的理念,推動阿里完成了從虛擬智能到現實行動的跨越。對他來說,這不只是一次技術升級,更是一次認知轉變——讓模型真正「走進現實」,去理解、感知並改變物理世界。
Agent時代的「創新-約束」平衡挑戰
當AI從「工具」進化為能自主決策的「Agent」,林俊暘深知,技術跑得越快,越需要倫理的「剎車系統」。這既是行業共性挑戰,也是他帶領通義千問邁向未來必須解答的命題——如何讓具身智能在「行動自由」與「安全可控」之間找到平衡點。
他認為,「讓機器變聰明」並不難,難的是「讓它做正確的事」。為此,他主導團隊建立了一套貫穿模型研發全流程的安全機制:在模型訓練階段引入人類偏好數據,確保行為決策不過界;在高風險領域(如醫療、工業)接入專家知識庫,為機器人劃定「禁區」;所有物理世界的操作都能被追溯,做到可解釋、可問責。
而隱私同樣是他關注的重點。「技術沒有邊界,但應用必須有底線」是他常掛在嘴邊的一句話。林俊暘推動阿里在菜鳥、盒馬等內部場景中採用「聯邦學習+數據脫敏」方案,讓模型在學習數據的同時不觸碰個人或企業的隱私信息。所有新模型必須通過團隊內部「AI倫理委員會」的一系列安全測試才能上線。林俊暘始終認為倫理並不是創新的障礙,而是智能走向成熟的前提。
對林俊暘而言,AI的未來不是做出更大的模型,而是讓它更「可用」。做大的不是參數,而是可用性;贏下的不是競速,而是生態。當智能真正能「看見、伸手、行動」時,現實世界將成為它最好的測試場。讓機器能動手,去行動——這正是智能擁抱真實世界的第一步。