作者 | 王涵
編輯 | 漠影
你一定在科幻電影中看到過這樣的情節:主角不小心進入了遊戲世界,在3D虛擬的場景中探索、漫步。
如今,這不再是只能幻想的場景。世界模型的出現,給這一情節帶來了更多在現實中實現的可能性。
經過一年時間的打磨,10月底,智源研究院發布了新一代原生多模態世界模型「悟界·Emu3.5」。
性能上,相較上一版本,Emu3.5在超過13萬億token的大規模多模態數據基礎上展開訓練,其視頻數據訓練量時長從15年提升到790年,參數量從8B上升至34B。
在不犧牲性能的前提下,Emu3.5每張圖片的推理速度提升了近20倍,首次使自迴歸模型的生成效率達到頂尖的閉源擴散模型的水平。
智東西獲得了Emu3.5的內測資格,第一時間對其文生圖和圖片編輯功能進行了實測。
首先是文生圖功能,我們輸入提示詞如下:
在一個充滿活力的灶底1場景中,大窗戶外可見鬱鬱蔥蔥的綠植。兩個動畫角色並排站着。左邊是一個擬人化的狐狸模樣的生物,有着橙色的皮毛、白色的腹部和一雙富有表現力的大眼睛,脖子上繫着一條綠色的圍裙。右邊是一個年輕女孩,棕色的頭髮紮成了辮子,穿着黃色的襯衫,外面套着一件藍綠色的圍裙。兩個角色似乎都在忙着做飯,背景中掛着各種灶底1用具、鍋以及橙子、大蒜等食材。整個環境明亮又歡快,陽光透過外面的樹葉灑進來。圖像中沒有可見的文字。
不到一分鐘,Emu3.5就生成了一副很「迪士尼風」的圖畫。畫面顏色明亮輕快,小女孩和狐狸都和提示詞形容的十分相似,畫面光影、比例和構圖都很協調。

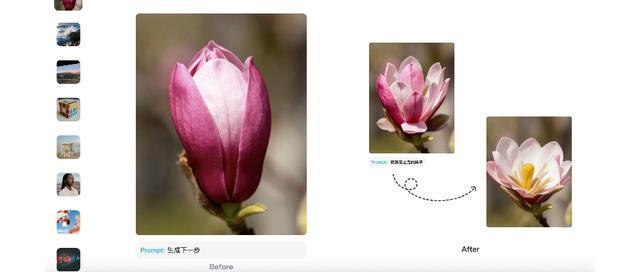
圖片編輯方面,我們上傳了一張小松鼠的照片,要求Emu3.5將畫面中的小松鼠提取出來,背景換成雪地場景。

原圖片中,小松鼠和背景色調一致,肉眼都容易看不清楚,Emu3.5卻十分精準地識別出了小松鼠的形象。其生成的圖片光影、結構準確,連陽光照射在雪地上的反光都十分逼真,在畫面的前方和後方背景,還實現了相機般的虛化效果。

此外,Emu3.5還能修改圖片視角。我們上傳了一張仰視的鼓樓夜景照片,要求Emu3.5將這張照片轉化為一隻鳥的視角:

Emu3.5不僅能精準實現視角切換,其「下一階段預測」範式更使其具備自動補全周邊環境畫面的能力,表現就像一台置於真實場景中的相機。

此外,Emu3.5還可以更改畫面中主體的位置關係和動作形態,比如讓小狗擁抱小貓:

識別數字和計數一直是多模態模型的弱點,Emu3.5卻可以精準識別將圖片中的標號,將指定序號的掛畫換成另外一張海報:

在畫面中加入一個物體也不在話下,Emu3.5可以直接將魔方放置在圖片場景中,並且會根據場景的光線和風格自動調整物體的色調,不會出現「不在一個圖層」的效果。

再比如,Emu3.5還可以修復老照片,還原老照片本來的顏色和質感:

當然,作為世界模型,Emu3.5也可以創造出一個「世界」。
例如,我們讓Emu3.5生成了一個臥室照片。接着,點擊繼續探索,要求Emu3.5更走近一些。通過一步一步地變換視角,Emu3.5就可以生成一個完整的「世界」:

除了變換視角,Emu3.5還可以「預測」圖片場景100年後的樣子:

該模型延續了將圖像、文本和視頻等多模態數據統一建模的核心思想,並在「Next-Token Prediction」範式的基礎上,模擬人類自然學習方式,以自迴歸方式實現了對多模態序列的「Next-State Prediction(NSP)」,從而獲得了可泛化的世界建模能力。
那麼,NSP是怎麼實現的?Emu3.5和其他世界模型有什麼不一樣的地方?除了生成圖片和「世界」Emu3.5還能用在哪裏?我深扒了「悟界·Emu3.5」的技術報告,給你一一解答。
一、直接預測下一個狀態,厲害在哪?
李飛飛在她的自傳《我看見的世界》中寫到,5.43億年前,地球上的生物生活在原始海洋中,沒有感官和知覺,因此也沒有大腦。後來,「寒武紀生命大爆發」時期到來,生物進化歷程從此開始狂飆。
動物學家安德魯·帕克認為,「寒武紀生命大爆發」之所以會發生,其實是因為生物開始具備「光敏感性」,這也是現代眼睛形成的基礎。
簡單來說,生命爆發進化是從「看見」開始的。那如果將這個進化路徑放在AI上呢?
在Emu的技術溝通會上,王仲遠博士也提出了類似的看法,他說:「人類的學習,不是從文本學習開始的。我們每一個人從出生開始,跟其他人的交流,認識物理世界的運行規律,都是從視覺開始的。」
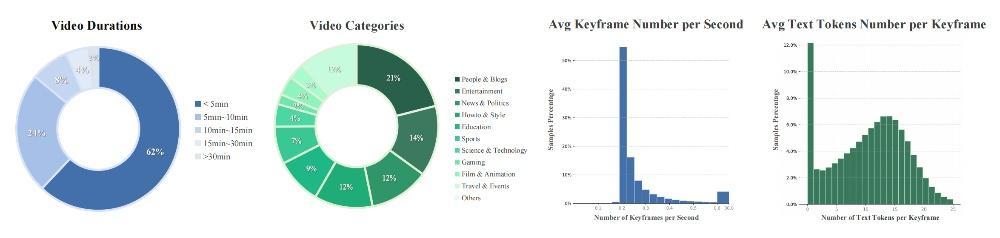
Emu3.5的訓練數據中包含超13萬億多模態token,其中視頻數據時長累計有790年,覆蓋教育、科技、How-to、娛樂等多領域。與傳統方法不同,Emu3.5的訓練語料庫旨在捕捉長時程、交錯的多模態語境。
具體而言,該子集來源於大規模互聯網視頻的連續視頻幀和時間對齊的音頻轉錄文本,這些內容本身就保留了時空連續性、跨模態對齊性和語境連貫性。
在訓練框架上,Emu3.5基於單一自迴歸Transformer架構,採用端到端原生多模態建模,無需依賴擴散模型或組合式方法,就實現了圖像、文本、視頻等多模態數據的「大一統」處理。
進而,在大規模多模態數據和Next-Token Prediction(NTP,下一個token預測)的基礎上,Emu3.5擴展出「Next-State Prediction(NSP,下一狀態預測)」即直接預測多模態序列的完整動態狀態,而非孤立token。
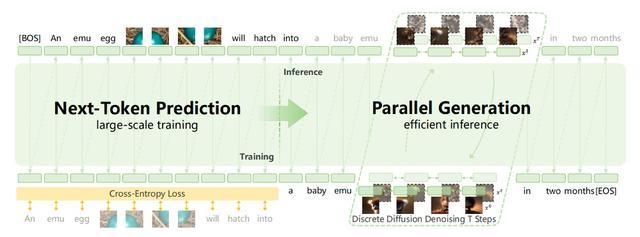
NSP厲害就厲害在,它可以讓模型從多模態數據中自主學習世界的動態規律,例如物理動態、時空連續性、因果關係,進而實現「理解——預測——規劃」的完整能力。
NSP還能將高層意圖轉化為可執行的多步行動路徑,接受指令後,Emu3.5能基於視頻中學到的 「物體移動規律」,規劃符合物理邏輯的連貫步驟,這正是AI從「感知」進化為「認知」的核心標誌。

為了提高推理效率,研究團隊提出了離散擴散自適應(DiDA)方法,它將逐token解碼轉換為雙向並行預測,在不犧牲性能的情況下,將單圖像推理速度提升了約20倍。
研究團隊還構建了多維度獎勵系統,對NSP的 「多步驟規劃準確性」「因果邏輯連貫性」 進行定向優化,提升了Emu3.5的步驟分解與物理規律匹配度。
從性能表現來看,當前Emu3.5參數量為340億,訓練所用視頻數據累計時長達790年,僅佔全互聯網公開視頻數據的1%以下,但模型性能已達到「產品級」水準。
「自迴歸架構」+「大規模強化學習訓練」+「下一狀態預測」(NSP)範式,至此,Emu3.5找到了多模態世界模型的Scaling Law方向,多模態模型性能可以像大語言模型(LLM)一樣,隨計算和參數規模的增長而可預測地提升。
「Emu3.5很可能開啓了第三個Scaling範式。」王仲遠博士這樣形容Emu3.5,毫不誇張。
二、教機器人抓拿握,不用再不同場景分開學了
正是因為在「下一狀態預測」上的技術突破,EMU3.5 模型具備了學習現實世界物理動態與因果的能力,展現出對複雜動態世界進行預測和規劃的能力。這就讓EMU3.5可以在具身智能方面大展身手。
在場景應用層面,模型可實現跨場景的具身操作,具備泛化的動作規劃與複雜交互能力,並能在世界探索中保持長距離一致性與可控交互,兼顧真實與虛擬的動態環境,實現自由探索與精準控制。

據介紹,Emu3.5已經開始了在具身智能方面的實踐探索。
過去,數據採集多侷限於固定場景,機器人真機只能採集到具體有限的數據,通過Emu3.5它可以產生泛化的數據,使得模型產生了泛化的能力。
而得益於Emu系列採用的自迴歸架構,其可擴展性極強,並且能夠支持視覺與文字Token的輸出。這能夠極大的提高模型,包括具身機械人、機械手臂,實際場景中處理泛化性的能力,自然而然就會推動整個具身更快進入一些真實的場景中
在真實場景測試中,應用Emu3.5後,未知場景中,機器人行動的表現成功率可直接達到 70%,而其他模型的表現成功率往往接近零。
「泛化」這一方向就是是智源研究院的重點發力的領域,目前正進一步擴大技術驗證規模,在真機上對各類場景展開嘗試。
三、只有原生多模態大模型,才能讓AI感知世界、理解世界
從上文中對Emu3.5的技術解讀不難發現,智源研究院一直堅持的技術路線核心就是「原生多模態」。
從Emu3到Emu3.5,模型均採用單一自迴歸Transformer架構,實現圖像、文本、視頻數據的 「端到端統一處理」,無需依賴擴散模型(DiT)或混合架構,從底層解決 「多模態數據對齊」 與 「跨模態推理」 的核心痛點。
智源研究院的研究團隊認為,世界模型不等同於視頻預測模型。真正的世界模型應該理解「杯子掉落→破碎」「點燃木頭→燃燒」等深層因果關係,並且可以「舉一反三」,將一個場景中的能力泛化到其他場景,真正做到像人一樣思考。
原生多模態大模型的研發,能夠把多模態的理解和多模態的生成統一起來。智源研究院認為,只有這樣,才能夠真正讓AI看到、感知、理解這個世界,才能夠讓AI真正進入物理世界,真正解決現實生活中更多現實的問題。
結語:世界模型進入「下一個狀態預測」範式
從「下一Token預測」邁向「下一個狀態預測」,Emu3.5的發布標誌着世界模型的發展進入了一個新階段。
其意義不僅在於視頻生成功效的提升,更在於通過「原生多模態」與「下一狀態預測」的路徑,讓模型獲得了對物理世界動態與因果關係的深層理解能力。這為AI在真實場景中實現可靠的規劃與決策奠定了基礎。
在行業落地上,這一能力更是直接瞄準了具身智能、自動駕駛和工業仿真等行業的痛點。在這些領域,AI不僅需要「看得見」,更需要「看得懂」,並能預測「接下來會發生什麼」。
隨着「狀態預測」範式的確立,世界模型的技術競爭正從「生成質量」的比拼,升級為「世界理解深度」的較量。