
1106 天,OpenAI 從掀桌子的人,變成了被掀桌子的人。
伴隨着 Google Gemini 3 的發布,OpenAI CEO 奧特曼上周罕見拉響了「Code Red」紅色警報,並宣佈所有資源迴流 ChatGPT 主線,其他業務一律靠邊站。
這是 OpenAI 成立以來第一次進入「紅色警報」狀態,也是它第一次如此明確地承認:競爭壓力已經大到必須全力應對。

而就在啱啱,OpenAI 發布了 GPT-5.2 模型,打出了一記力量感十足的重拳。GPT-5.2 將向 ChatGPT 付費用戶開放,並通過 API 提供給開發者,分為三個版本:
不聊天,真幹活,GPT-5.2 闖進打工人職場
本以為 OpenAI 會專注提升 ChatGPT 的個性化和消費者體驗,結果 GPT-5.2 的發布方向依舊是走職場實用主義的路數。
用 OpenAI 應用 CEO Fidji Simo 的話來說:「我們設計 GPT-5.2 是為了給用戶創造更多經濟價值。」
什麼叫經濟價值?
就是讓 AI 真的能幹活,做表格、寫 PPT、敲代碼、看圖、讀長文、調用工具、搞定複雜項目,這些都是 GPT-5.2 的拿手好戲。
數據也挺唬人。平均每個 ChatGPT 企業版用戶說,AI 每天能給他們省 40 到 60 分鐘,重度用戶更狠,每周能省 10 小時以上。
GPT-5.2 Thinking 是這次發布的重頭戲。
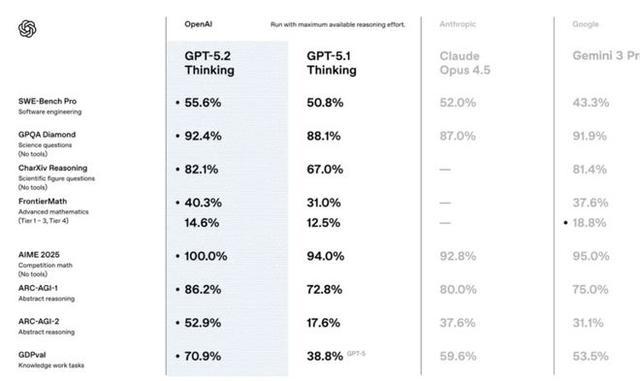
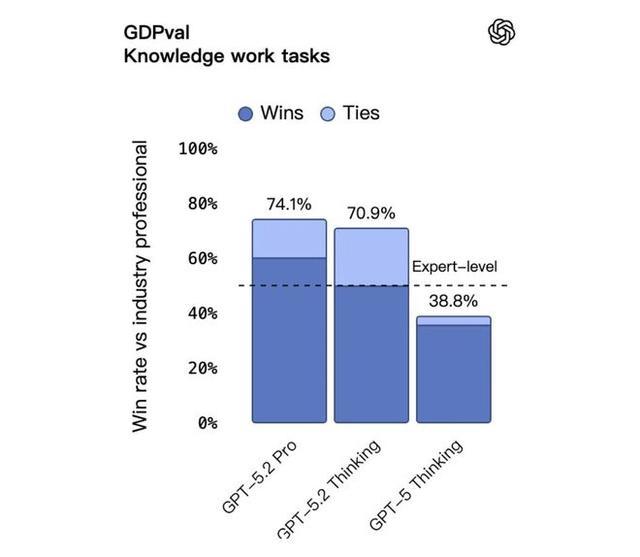
在評估 44 個職業知識型任務的 GDPval 測試中,它成為首個在總體表現上達到或超過人類專家水平的模型。具體來說,在與行業專家的對比中,GPT-5.2 Thinking 在 70.9% 的任務中勝出或持平,由人類專家親自評判。
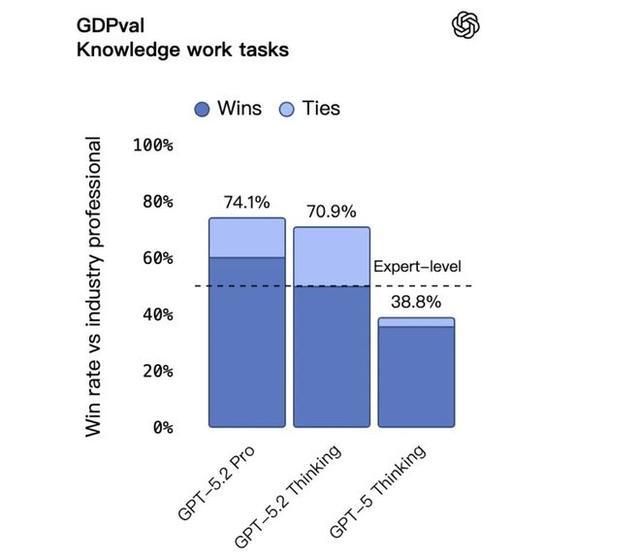
這些任務可不是隨便出的題,涵蓋了美國 GDP 排名前 9 個行業,包括銷售演示文稿、會計報表、急診排班計劃、製造業圖紙、短視頻製作等等,都是真實工作場景裏的硬活。
編程方面的提升更明顯。
SWE-Bench Pro 是個相當嚴格的測試,評估模型在真實世界軟件工程中的能力,涉及四種編程語言,比只測 Python 的版本難多了。GPT-5.2 Thinking 在這個測試裏拿到了 55.6% 的成績,創下業界新高。
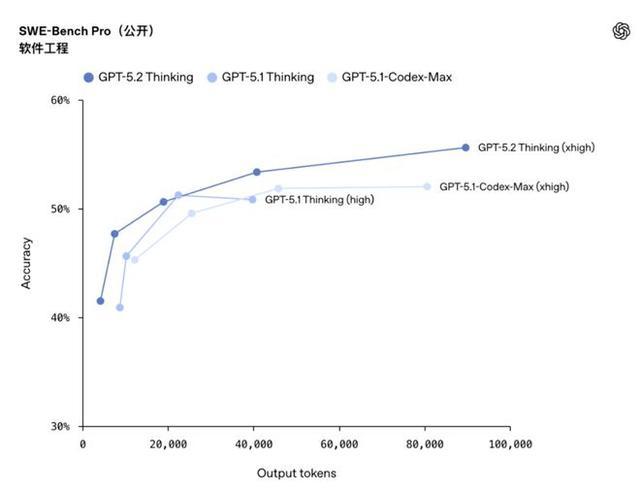
更誇張的是在 SWE-bench Verified 裏直接幹到 80%,成為目前最高記錄。這意味着 GPT-5.2 Thinking 能更可靠地調試生產環境中的代碼、實現功能需求、重構大型代碼庫,端到端的修復工作做得更高效,減少人工介入。
前端開發也有明顯提升。
早期測試者說,它在處理複雜或非常規的前端 UI 任務時表現更出色,特別是涉及 3D 元素的場景,妥妥的全棧工程師助手。
OpenAI 還放出了幾個根據單一提示生成的示例:海浪模擬器、節日賀卡生成器、打字雨遊戲。就一個提示詞,整個單頁應用就出來了,可調節的參數、逼真的動畫效果、平靜的 UI 風格,全都有。
幻覺率降低30%,長文本能力接近完美
事實準確性這塊,GPT-5.2 Thinking 相較於 GPT-5.1 Thinking 的「幻覺率」更低。
在一組匿名化的 ChatGPT 查詢中,出現錯誤的回答減少了約 30%。對於專業人士來說,這意味着在研究、寫作、分析與決策支持等任務中,出錯率更低,用起來更放心。
不過 OpenAI 也提醒,就像所有模型一樣,GPT-5.2 並不完美,關鍵性任務還是得自己覈查。
長文本推理能力也樹立了新標杆。
在 OpenAI MRCRv2 基準測試中,GPT-5.2 表現領先。這個測試評估的是模型能不能正確整合分佈在長文檔中的信息,對於深度文檔分析這類涉及數十萬 token 的跨文檔信息整合任務來說,GPT-5.2 的準確率遠超 GPT-5.1。
尤其在 MRCR 的 4 針測試(不同於「大海撈針」,而是要求模型在海量文本里,區分並找出多個一模一樣的「針」中的特定一個)中,最多 256k token 的上下文,GPT-5.2 是首個接近 100% 準確率的模型。
這意味着專業用戶可以用 GPT-5.2 高效處理超長文檔,報告、合同、學術論文、訪談記錄、多文件項目,它都能在處理上百頁內容時保持邏輯一致和信息準確。視覺理解方面,GPT-5.2 Thinking 是目前 OpenAI 最強的視覺模型。在圖表推理和軟件界面理解方面,錯誤率下降了約一半。
對日常專業使用來說,這意味着模型能更準確地解讀數據儀表盤、產品截圖、技術圖紙、可視化報告,適用於金融、運營、工程、設計、客服等以視覺為核心的工作場景。

空間理解能力和工具調用能力也有所提升,在 Tau2-bench Telecom 測試中,GPT-5.2 Thinking 取得了 98.7% 的新高成績,展現出在長、多輪任務中可靠使用工具的能力。
即使將推理強度設定為最低檔,GPT-5.2 的表現仍顯著優於 GPT-5.1 和 GPT-4.1。
這代表 GPT-5.2 Thinking 在執行端到端工作流方面更強,處理客戶服務案例、從多個系統中提取數據、執行分析任務,高效完成全流程輸出,中間環節更少出錯。
數學和科學能力的提升,可能是這次發布裏最硬核的部分。
在 GPQA Diamond 這種研究生級別的科學問答測試裏,覆蓋物理、化學、生物學等領域,GPT-5.2 表現明顯更強。FrontierMath 那種評估專家級數學問題解決能力的基準測試,它也能啃下來。
更牛的是,在 ARC-AGI-1 測試中,GPT-5.2 Pro 是第一個突破 90% 準確率的模型,相比去年 o3-preview 的 87%,表現更強,成本卻降低了約 390 倍。
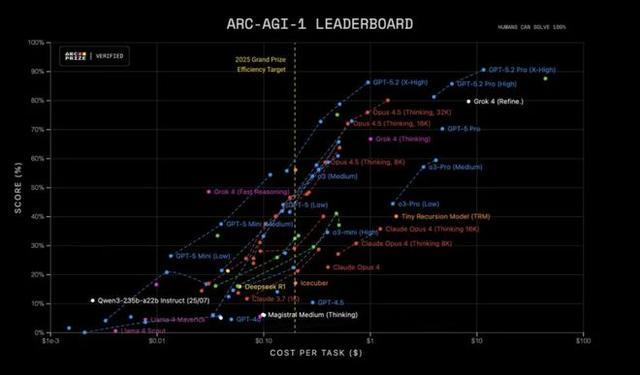
ARC-AGI-2 版本更難,專注於考察流動性推理能力,GPT-5.2 Thinking 得分為 52.9%,創下「鏈式思維模型」新高,GPT-5.2 Pro 更進一步,達到 54.2%。
官方博客中提到一個令人印象深刻的案例:在統計學習理論的一個開放問題上,GPT-5.2 Pro 甚至直接給出了一個可行的證明方案。
這個問題來自 2019 年學習理論大會 COLT 上提出的未解難題:如果模型設定完全正確,數據呈標準正態分佈,在這種教科書式的「乾淨」情況下,學習曲線是單調的嗎?

研究人員沒有先設計算法或提供證明思路,也沒有輸入中間步驟或提示,而是直接請求 GPT-5.2 Pro 給出完整證明。結果,模型提出了一種可行的解法,並通過人工驗證、外部專家評審確認其正確性。
這說明 GPT-5.2 Pro 在一些有明確公理基礎的領域,比如數學、理論計算機科學,已經可以發揮更實質性的科研輔助作用:探索證明路徑、驗證假設、發現隱藏的聯繫。
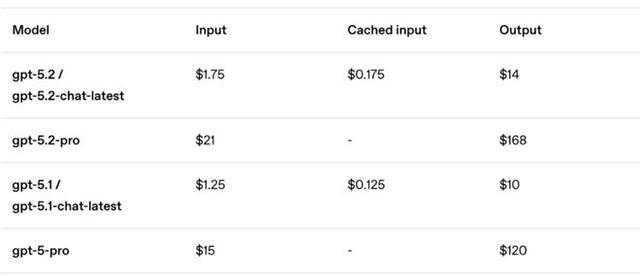
GPT-5.2 API 價格
性能表現這麼猛,代價自然也不小。
Thinking 和 Deep Research 模式消耗的算力遠超普通聊天機器人,因為它們得「思考」得更深。由於 OpenAI 現在用於模型推理的開銷,大部分是直接掏真金白銀,而不是用微軟 Azure 的雲服務積分抵扣。
長期往裏砸錢,這種玩法能撐多久,真不好說。
總得來說,GPT-5.2 更像是對前兩次模型升級的整合,而不是完全重構。
8 月的 GPT-5 是架構重啓,引入了可以在快速響應和深度「Thinking」模式之間切換的路由機制。11 月的 GPT-5.1 讓系統變得更溫和、更具對話性,也更適合智能體和編碼任務。
現在的 GPT-5.2,則是要在這些優勢的基礎上,打造出更可靠的生產級模型。而且有一個非常重要的細節:這次推出的三款 GPT-5.2 模型,底層知識庫都已經完成了更新。

GPT-5.2 已經開始在 ChatGPT 中陸續上線,優先開放給付費用戶。GPT-5.1 還會在「傳統模型」選項中保留三個月,之後就正式下線了。
API 那邊也同步開放,開發者已經可以用上了。價格比 GPT-5.1 貴一些,但 OpenAI 說因為 token 效率更高,實際總成本反而更低。
一個壞消息,和一個好消息
除了模型本身,OpenAI 的商業化上也有兩個極具反差感的消息。
雖然這次發布並沒有推出新的圖像生成模型,但今天 OpenAI 跟迪士尼達成了三年授權協議。
用戶可以生成包含迪士尼、漫威、皮克斯和星球大戰等 200 多個角色的社交視頻,部分生成視頻還能在 Disney+上播放。
作為交換,迪士尼向 OpenAI 投資 10 億美元,還會成為重要客戶。內容 IP 加 AI 生成,這背後想象空間確實挺大。

另一個值得關注的消息是,ChatGPT 的「成人模式」終於有了明確時間表。
隨着越來越多 AI 聊天機器人涉足成人內容,OpenAI 也不打算當聖人了。根據彭博社報道,Fidji Simo 已經明確該功能預計 2026 年第一季度上線。
在此之前,OpenAI 會繼續優化年齡識別功能,確保未成年人自動啓用內容保護機制。目前年齡預測模型正在部分國家進行早期測試,以評估識別青少年的能力,並確保不會誤判成年人。
面對 Google Gemini 的步步緊逼,OpenAI 選擇用 GPT-5.2 這套組合拳來回應。它更快、更強,也更像一個成熟的商業產品。
與此同時,一邊擁抱迪士尼的米老鼠,一邊準備推出成人模式,OpenAI 既要保持技術領先,又要快速變現;既要佔領企業市場,又不放過任何流量入口。
幸運的是,迎來十周年節點的 OpenAI 最終還是演好了這出反擊大戲。
還有一個小彩蛋