鳳凰網科技訊 12月18日,美團LongCat團隊正式發布並開源虛擬人視頻生成模型LongCat-Video-Avatar。該模型基於其此前開源的LongCat-Video基座構建,支持通過音頻、文本或圖像生成虛擬人視頻,並具備視頻續寫功能。

據介紹,新模型重點提升了動作擬真度、長視頻生成穩定性與身份一致性。其通過「解耦無條件引導」技術使虛擬人在語音間歇也能呈現眨眼、調整姿勢等自然狀態。針對長視頻生成中常見的畫面質量退化問題,團隊提出了「跨片段隱空間拼接」策略,旨在避免重複編解碼帶來的累積誤差,聲稱可支持生成長達5分鐘的視頻並保持畫面穩定。
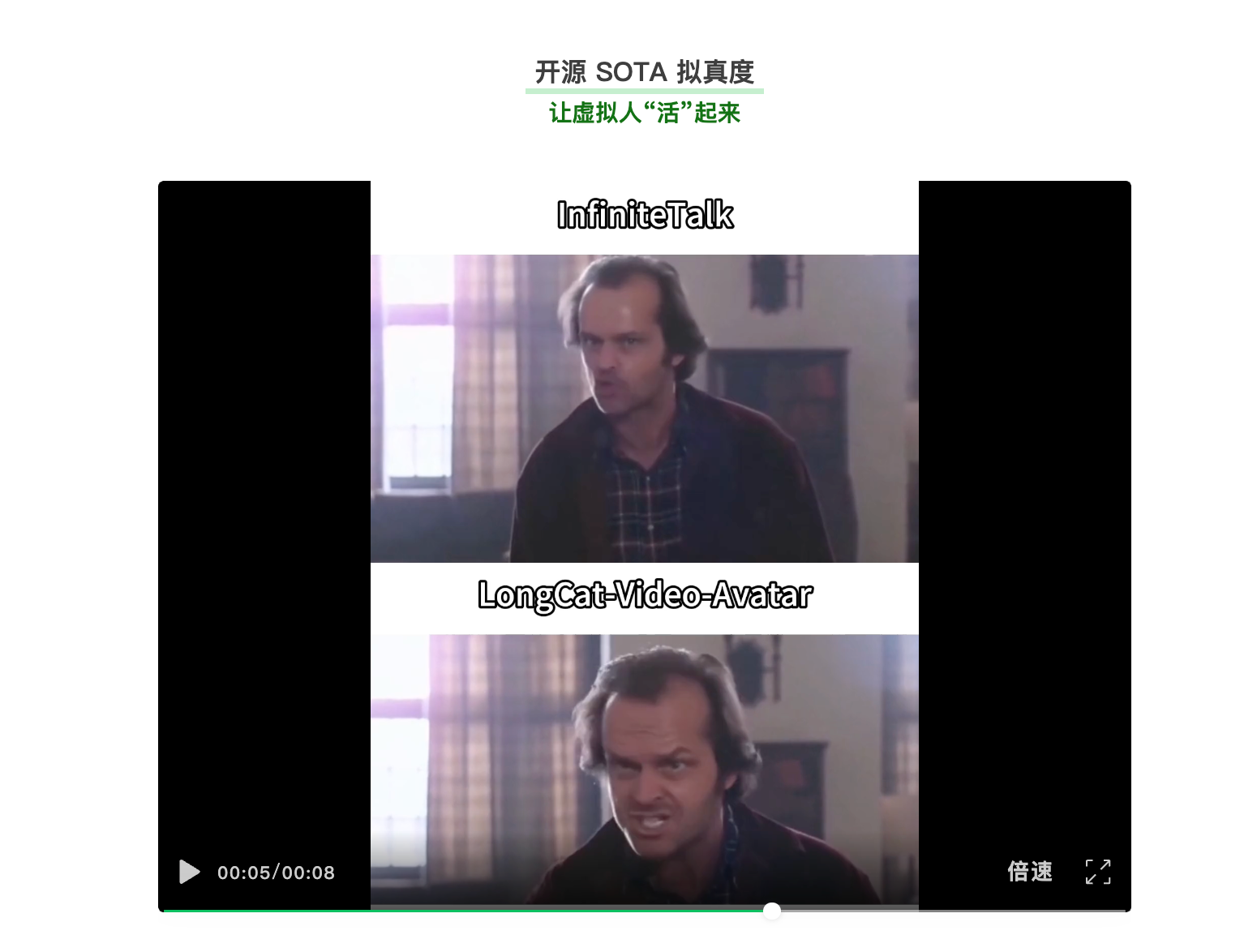
在身份一致性方面,模型採用了帶位置編碼的參考幀注入與「參考跳躍注意力」機制,以在保持角色特徵的同時減少動作僵化。團隊表示,在HDTF、CelebV-HQ等公開數據集的評測中,該模型在脣音同步精度與一致性指標上達到當前先進水平,並在涵蓋商業推廣、知識教育等場景的綜合測試中表現領先。