
文|魏琳華
編|王一粟
第一批AI大模型公司上市潮來了,先衝線的兩家公司MiniMax、智譜揭開了自己的底牌。
相比於其他AI公司,MiniMax在國內似乎更加低調和神祕,這家從出生時就在海外市場拓展的公司,到底在怎麼賺錢?
從招股書來看,2025年前三季度,MiniMax營收從上年同期的1945萬美元激增至5344萬美元(約3.8億人民幣),按年增長高達174%。
能看出來,MiniMax的商業化,就像三級火箭般加速上升。
翻倍的增長並非孤例。放眼全球,這是2025年全球AI商業化進入加速期的縮影。以OpenAI和Anthropic為代表,它們同樣在這一年迎來了收入的爆發。
那麼,MiniMax是怎麼做到的?
詳細拆解招股書後,光錐智能發現,相比AI 1.0時代的公司基本都以B端業務為主,MiniMax開闢了一個比較新的商業模式——「B+C全都要」,即企業級用戶和個人用戶都拿下。這在過去的AI公司當中,並不常見。
海螺AI、星野,相比於AI視頻、AI社交這兩款用戶熟知的AI爆品,我們今天更想聊聊,MiniMax不為人知的另一面——B端業務。
在C端的光環之下,MiniMax的B端業務往往成為了被忽視的一環。
招股書顯示,MiniMax的B端業務貢獻了1542萬美元的營收,佔比28.9%,接近三分之一,按年增長161%。
MiniMax的B端業務收入來自哪裏?他們的模式和其他側重B端業務的AI大模型公司相比,到底有什麼不同?
收入佔1/3的B端業務
傳統生意的非傳統做法
和其他AI大模型一樣,
MiniMax的B端業務收入主要來自——API調用。
從OpenAI到阿里通義千問,在其他商業模式尚未探索出來之前,API就是那個「看似不那麼性感,但卻非常實際」的收入來源。這個收入模式樸素到不行,就類似水費、電費一樣,開發者用多少,就根據調用量付多少錢。
而MiniMax開放平台就是負責輸出API的標準化B端服務產品。目前,MiniMax開放平台覆蓋範圍超過100個國家及地區的企業客戶和開發者,覆蓋的領域有AI+硬件、文旅、電商、辦公、教育、遊戲、醫療、金融等。
另外,在模型能力上,MiniMax開放平台也提供文本生成、語音合成、視頻生成、圖片生成、音樂生成等接口能力,企業和中小開發者可調用的旗艦模型覆蓋全模態,包括MiniMax M2、Hailuo 2.3、Speech 2.6 和 Music 2.0等系列模型。
儘管體量尚不及C端,但MiniMax的B端業務增長速度和C端接近,都是翻倍式增長。
值得一提的是,目前看來MiniMax的B端業務「健康度」還不錯。招股書顯示,MiniMax的B端業務毛利率高達69.4%,相比去年同期的62.3%有所提升。
在近三年模型價格「一降再降」的行業環境下,MiniMax的模型能力和競爭力應該是非常在線,才能確保不是「賠本賺吆喝」。
另外,從這個收入模式能看出,MiniMax在B端的戰略就是:不做定製化私有部署,只做輕量級的企業服務。
這可能是因為MiniMax創始人閆俊傑在商湯工作的經驗,從一開始就避免做很重的「定製化」企業級服務。而基於開放平台的API調用,這也是OpenAI、Anthropic等一衆海外大廠普遍選擇的模式。
對比在AI 1.0時代被視為「髒活累活」的部署業務,定製化的優勢和劣勢都很明顯:
靠深入的服務,客戶對企業的依賴性極高,如果後續想要遷移平台,不是API平台幾行代碼就能解決的;但深度定製需要企業提供專員跟進服務,高昂的人力成本會拖累整體業務的毛利率。這也是為什麼智譜公司架構需要千人規模,而MiniMax只需要400人左右的團隊。
值得注意的是,雖然API的服務非常輕量級,但要想讓更多人調用,光靠MiniMax遠遠不夠。
通過深扒招股書和公開信息,光錐智能發現,MiniMax在國內和海外都在努力構建自己的生態圈,已經深紮在各大AI平台裏。
在國內,其已經合作了包括字節、阿里、騰訊、小米在內的企業,比如,給阿里和字節旗下的Coding產品提供文本模型支持、給騰訊遊戲和視頻提供視頻生成服務等。
這一點就很有意思,雖然各大頭部科技公司都在推出「AI大模型全家桶」,但依然對MiniMax的需求量不小,說明他們確實在某些模型能力方面有兩把刷子。
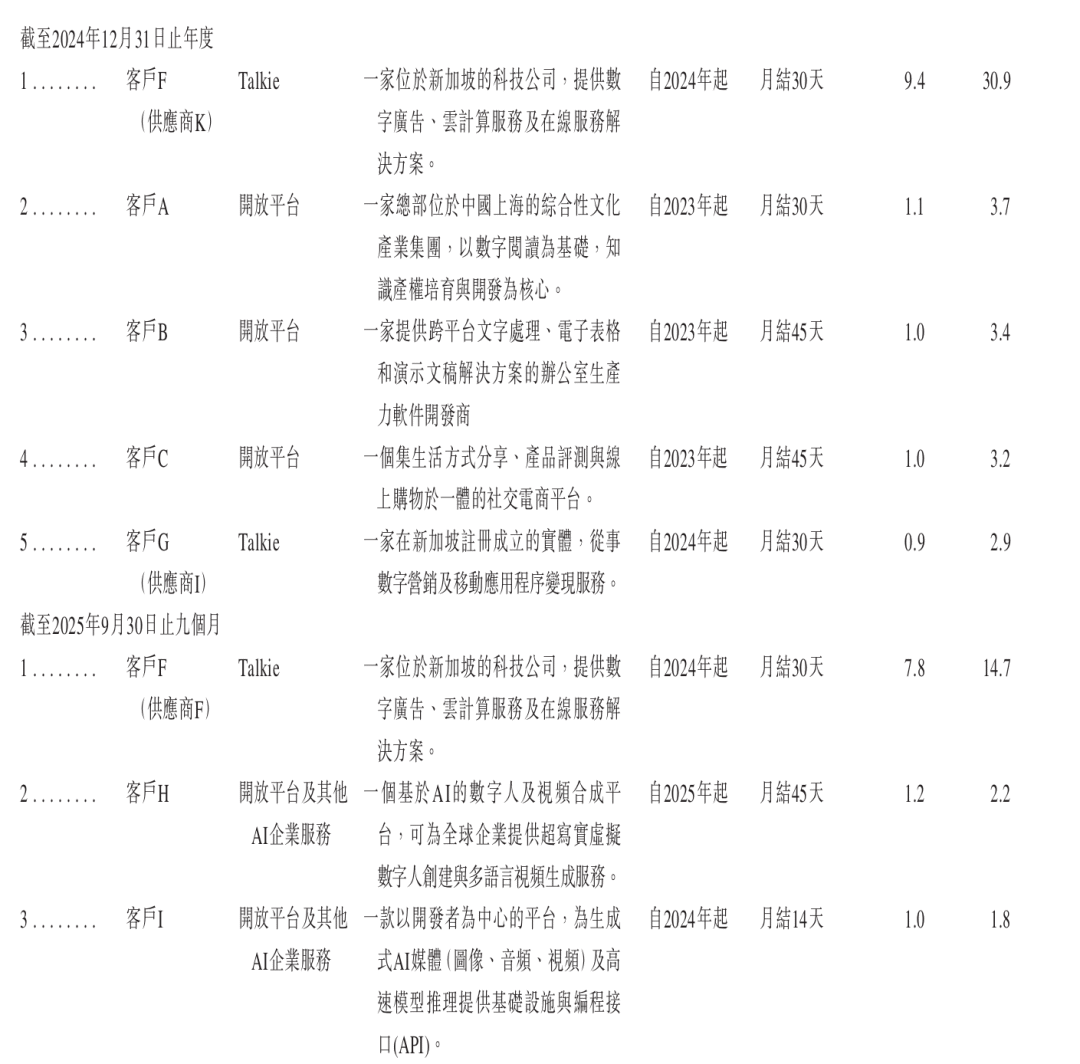
這其中,MiniMax合作的前五大客戶也在招股書中進行了相應披露,比如2023、2024年都位列前五的小紅書、閱文集團和金山辦公(WPS),2025年的企業指向性不強,比較明顯的是一家AI數字人及視頻合成平台,結合MiniMax披露信息推測為Veed。
而在海外,隨着M2模型的破圈,MiniMax也進一步擴大API業務的收入。其中,谷歌、微軟第一時間上線M2模型,亞馬遜大會上也特地官宣了M2模型的上線。

未來幾年的增長預期,MiniMax也進行了相應的估計,從與阿里雲的戰略合作可以體現一二。
招股書顯示,未來三年MiniMax對阿里雲的算力消耗將逐年遞增,而相應的,向阿里巴巴集團提供的API服務收入上限也設定了明確的增長階梯:從2026年的65萬美元,攀升至2027年的100萬美元,並在2028年達到150萬美元。
可以說,市場需求的指數級增長和MiniMax的系列大模型佈局,撐起了MiniMax未來在B端業務的成長空間。
從API接口,到深度融合
年年增長的算力需求背後,MiniMax的B端業務如何擴張版圖?
通過拆解招股書和公開信息的梳理,MiniMax的B端戰略可以拆解為三個層級:從最基礎的API接口,到幫助企業內部工作提效,再到嵌入企業產品中,做深層融合。
最基礎的合作形態,是直接和服務商對接,通過在三方平台中開放API接口,通過生態鋪開銷量。比如,谷歌、亞馬遜、英偉達等平台直接接入M2模型。
當然,這也是非常早期的合作模式。隨着生成式AI的發展按下加速鍵,企業對AI的應用逐漸深化,需求也向着和業務深度結合的方向演進。
分拆到具體合作模式中,可以分為兩種。其一,聚焦於「提效增收」,企業試圖用AI,重塑內部生產流程。
在內容產業,這種提效體現得尤為明顯。
以騰訊視頻及天美工作室為例,在視頻內容和遊戲創作領域,AI視頻生成能夠幫助生成高質量的特效視頻、遊戲素材。
單以影視上的應用來說,AI能夠在需要特效的大場景製作中幫助壓縮生產周期和成本,往往需要幾天時間佈景拍攝的內容,交給AI只需要幾分鐘,同時能把成本從數十萬壓到萬元、千元級別。
同樣的邏輯也延伸到了營銷領域。Monks在為其他企業提供的營銷方案中,通過接入MiniMax視頻模型和海螺AI產品,優化內容創作流程,同時在這個過程中節省成本、提升效率。以HaiLuo 2.3模型的官方信息計算,其批量創作成本最高可降50%。
如果說降低成本是為企業做「減法」,那麼第二類業務模式相當於做「加法」——通過將模型嵌入企業主推產品中,達到「1+1>2」的效果。
按照MiniMax做全模態的思路分類,出場頻率較高的幾種合作可以分為文本、語音、視頻三類。
在文本與邏輯推理領域,MiniMax從推理模型M1開始,主推的Agent(智能體)能力成為了賣點。
以編程來說,在目前備受關注的AI Coding賽道中,兩個主要參與者字節、阿里的產品裏,都出現了MiniMax的參與:字節是在其Coding類產品中接入新模型供調用,比如本周上線開源的M2.1;而阿里則是用於其AI Coding工具iFlow的底座文本模型。
而對於AI Coding類產品來說,底座文本模型的選擇很關鍵,因為它對於複雜任務的拆解能力要求更高,需要模型完成理解需求—規劃步驟—編寫代碼—自我糾錯。這種多步梳理的特性,剛好和Agent能力相契合。
隨着模型泛化能力的提升,B端業務的合作範圍也隨之擴大。
12月22日,維他動力發布的機器狗Vbot披露了合作MiniMax的新模型M2.1,宣傳「實現空間智能Agent」。

對於空間智能來說,推理是一件更麻煩的事。類似智駕邏輯,如果模型泛化能力不足,就會對陌生問題難以下手——比如遇到路障就「卡殼」。
M2.1能夠支撐機器狗處理任務,就得益於模型泛化能力的提升,其中的關鍵之一,就是MiniMax從M2系列開始大力推的交錯思維鏈(Interleaved Thinking)。它的優勢就在於,能夠讓模型保持「思考-執行」的思維方式,根據執行結果,代入上一輪思考結果來處理,使智能體能夠實時應對開放性環境,應對「未知雜亂」。
除了文本領域,MiniMax有不少的合作項目集中在視頻和語音領域。
其中,視頻領域多支撐視覺產品運行,比如Veed數字人、和快看合作的AI漫畫;語音領域則是一個在C端不太賺錢、B端需求量高的生意,MiniMax的合作就集中在給小米、智元機器人的產品提供音色互動支持。
縱觀MiniMax在B端的合作版圖擴張,關鍵在於兩點——全模態佈局和模型能力提升,前者讓B端業務更多元,後者則保證能夠在競爭激烈的市場上拿到訂單。
堅持只做API服務、和私有化部署「割席」的決定,則讓B端業務的高毛利率,成為了向市場證明未來潛力的敲門磚。
被低估的中國AI獨角獸
如何重估價值?
為了繼續向市場證明自身能力,新模型的發布和能力升級就成了現階段大模型公司們的頭號任務。
MiniMax也不例外,在上市當周,MiniMax也發布並開源了基於M2模型升級的新模型M2.1。從官方信息來看,新模型在多編程語言、移動端開發、執行、泛化等能力均有提升。
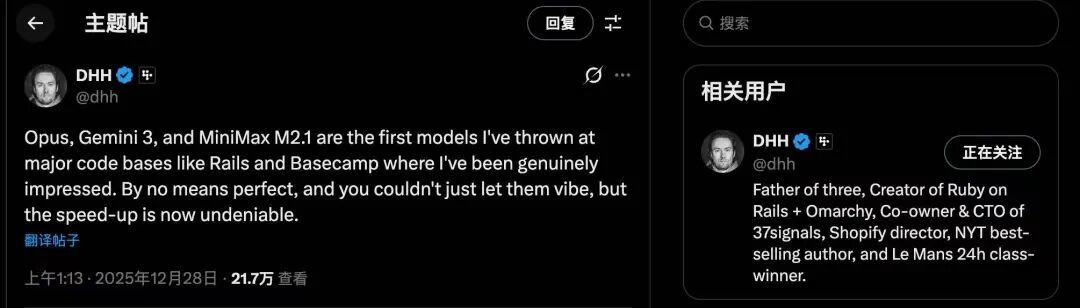
「(Claude)Opus、Gemini 3和MiniMax M2.1是首批被我用於Rails、BaseCamp等代碼庫中的模型,在使用過程中我感到非常震撼。」創建Web開發框架Ruby on Rails的傳奇程序員DHH在X上給出了評價。
不過,儘管更多國內開源大模型已經能夠和海外第一梯隊的閉源大模型們較勁,但在公司估值表現上,兩者拉開了一條長長的距離。
這也引出了現階段國內大模型公司的一個共同特點——加速上市,以獲取更多能夠支撐公司繼續「掰腕子」的籌碼。
仍以MiniMax為例,即使交出的成績單證明了商業化規模落地的初步潛力,但如果拿來和其他行業公司的上市階段相比,不難發現,AI 2.0時代的公司們,奔赴上市的步伐相當快。
以AI 1.0時代為例,基本上,一家尋求IPO的公司已經在商業化完成了相應佈局,在營收模式上相對成熟。
其中,商湯上市前累計完成12輪孖展,到了E輪階段,累計孖展超52億美元,才正式開啓遞交招股書的階段。彼時,商湯已經確立智慧城市、智慧商業、智慧生活和智能汽車四大業務,年營收達到34.5億。
但無論是近期沐曦、摩爾線程、壁仞等國產GPU們的加速上市,還是MiniMax和智譜赴港上市,都能看出這一代公司尋求上市的急切。
而對於尚處早期階段公司的上市,如何估值和定價就成為了一個新的難題。如果用傳統的市銷率(PS)甚至市盈率(PE)來衡量,大模型公司難免「貴得離譜」。
以OpenAI為例,以2025年預計收入130億美元來算,據悉OpenAI正在展開孖展,孖展後估值有望衝擊8300億美元,這樣來算,其PS值高達63倍,而OpenAI淨虧損預計高達90億美元,更是無法從PE來衡量。
高達幾十倍的PS倍數,通常意味着巨大的泡沫。然而,將大模型公司視為普通的公司做估算,本身就是一種估值錯位。
可以說,在AI 2.0時代,傳統的財務錨點已經失效了。相比之下,國內大模型公司往往處於被低估的節點。
在近期的一場對談中,羅永浩與MiniMax創始人閆俊傑觸及了一個令中國科技圈頗感複雜的現實:AI 2.0時代,中國公司似乎陷入了一種奇怪的「估值悖論」。
「美國最好公司的估值,是中國創業公司的100倍,然後收入基本上也是100倍,但是技術可能就領先5%。」閆俊傑如此描述這種落差,「然後(相比中國公司)花的錢其實可能也是幾十倍,可能在50到100倍之間。」
這段話精準地勾勒出中國大模型創業者的生存圖景:估值被嚴重低估後,各家公司練就了「花小錢辦大事」的本領。
無論是靠極致效率殺出圈的DeepSeek,又或者是最近上市的MiniMax,都是其中極具代表性的公司。前者通過對底層架構的極致優化,將訓練與推理成本壓縮了一個數量級;後者用400人左右的團隊,在業務廣度上覆蓋了Anthropic(文本)、Runway(視頻)、ElevenLabs(語音)和Suno(音樂)這四家美國獨角獸的總和。
到了最終的上市環節,可以看到,上述四家美國公司的估值總和高達數千億美元,在中美投資風格差異之下,估值可能存在的差距1個數量級。
不過,可以確認的是,大模型公司們先後跑通商業化閉環,已經初步證明了大模型的營收能力。
無論是OpenAI年入百億美元,海外Anthropic年入50億美元,都證明了大模型確實能賺大錢。
MiniMax們遞交招股書,也藉着數據證明了這一邏輯在中國企業身上同樣奏效。不僅僅是高收入,高毛利率,高增長空間也是關鍵:其B端業務高達69.4%的毛利率,以及付費客戶數25倍的增長,都是最有力的驗證。
當「模型通,商業通」的邏輯閉環被驗證,剩下的只是通過堆算力和擴銷售來放大規模的問題。這也就是為什麼當前階段,大模型公司爭先恐後上市。
在技術發展尚未觸及天花板的當下,只有率先完成IPO,才能靠二級市場的資金支持,支撐大模型訓練的同時,快速擴大市場覆蓋範圍,拿下通往AGI下一關的門票。