AI變聰明的真相居然是正在「腦內羣聊」?!
谷歌最新研究表明,DeepSeek-R1這類頂尖推理模型在解題時,內部會自發「分裂」出不同性格的虛擬人格,比如外向的、嚴謹的、多疑的……
大模型的解題推理過程,就是這些人格一場精彩的社交、辯論會;左右腦互搏be like:
「這個思路對嗎?試試這樣驗證……」
「不對,之前的假設忽略了xx條件」
……

有意思的是,AI還越吵越聰明。
研究發現,當遇到GPQA graduate-level科學問題、複雜數學推導這類高難度任務時,這種內部觀點衝突會變得更加激烈。
相比之下,面對布爾表達式、基礎邏輯推理等簡單任務,模型的腦內對話會明顯減少。
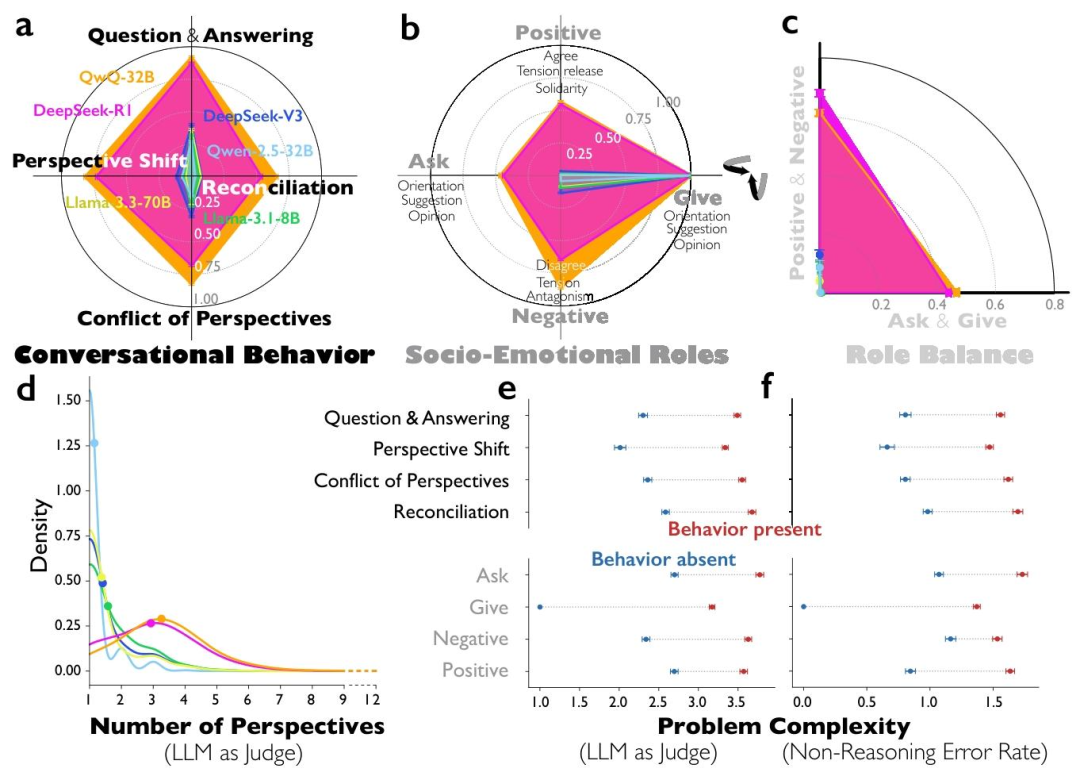
模型推理過程就是「左右腦互搏」
團隊通過分析DeepSeek-R1和QwQ-32B等模型的思維軌跡發現,它們的推理過程充滿了對話感。
內部分裂出來的虛擬角色不僅性格迥異,還能覆蓋更多解題角度。
創意型角色擅長提出新穎思路,批判型角色專注挑錯補漏,執行型角色負責落地驗證……
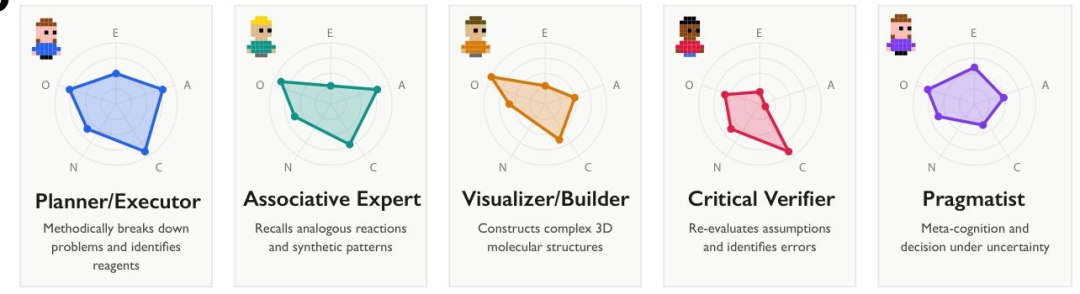
通過這些人格的一場交流,不同觀點的碰撞能讓模型更全面地審視解決方案。
就連網友都說,自己在思考的時候,也會「左右腦互搏」。

不過,這種多角色互動並不是開發人員刻意設計的,而是模型在追求推理準確率的過程中自發形成的。
那麼實驗是如何證明這一點的呢?

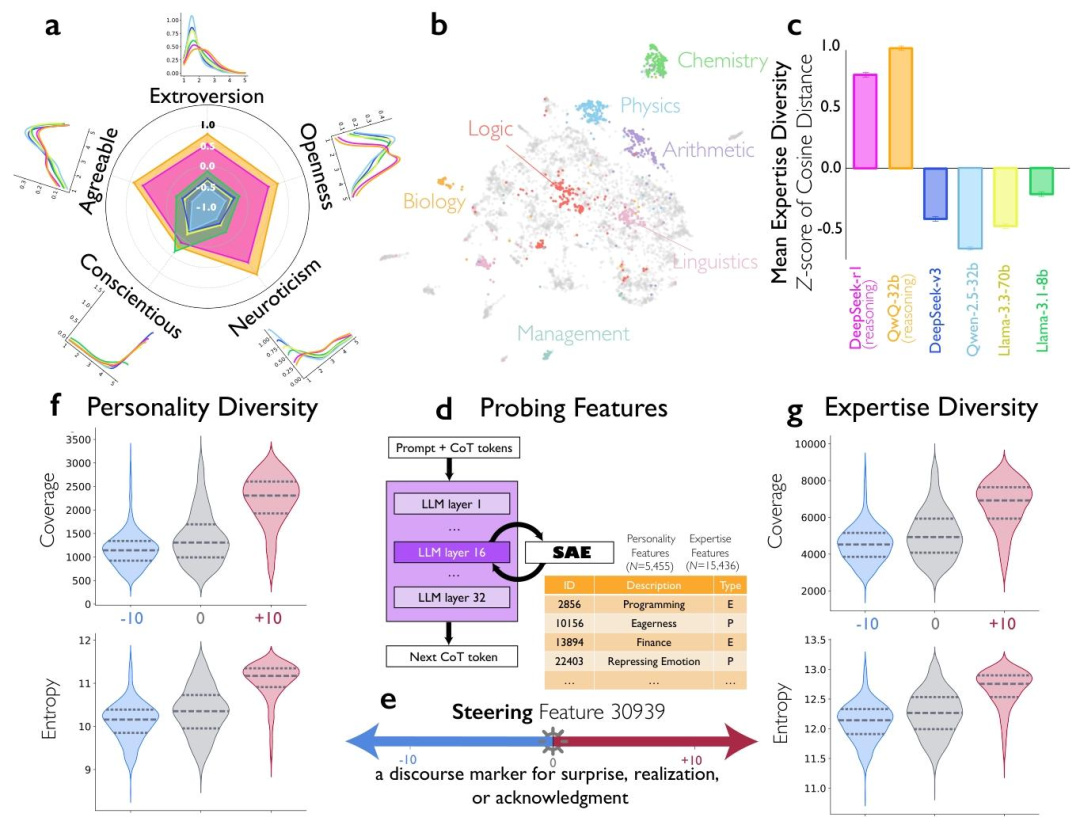
團隊藉助稀疏自編碼器SAE,對AI的推理黑盒進行了深度解碼,成功「監聽」到了AI的腦內羣聊。
首先,研究者讓AI執行復雜的數學或邏輯推理任務。在模型產出思維鏈的同時,團隊同步提取其隱藏層神經元的激活數值。
但此時的數據是由數億個參數構成的複雜非線性信號,無法直接對應任何語義。
將這些激活數據輸入SAE,通過SAE的稀疏約束機制,就可以把雜亂的激活拆解為「自問自答」、「切換視角」等獨立的對話語義特徵;
通過分析這些特徵的激活頻率以及它們在時間序列上的協同關係,團隊成功識別出了不同的內部邏輯實體。
再給上述特徵打上「規劃者」、「驗證者」等虛擬角色的標籤,就成功解碼了AI內部的多角色對話行為。
「哦!」能讓推理更準確
通過對比DeepSeek-R1與DeepSeek-V3、Qwen-2.5-32B-IT這類普通指令模型的推理軌跡,發現推理模型的對話式行為出現的頻率顯著更高。
這裏還有個很有意思的發現——
「哦!」能讓推理更準確。
當團隊通過激活添加法強化模型的對話特徵,放大「哦!」這類表達驚訝、轉折的話語標記時,模型在Countdown算術推理任務中的準確率直接從27.1%翻倍至54.8%。
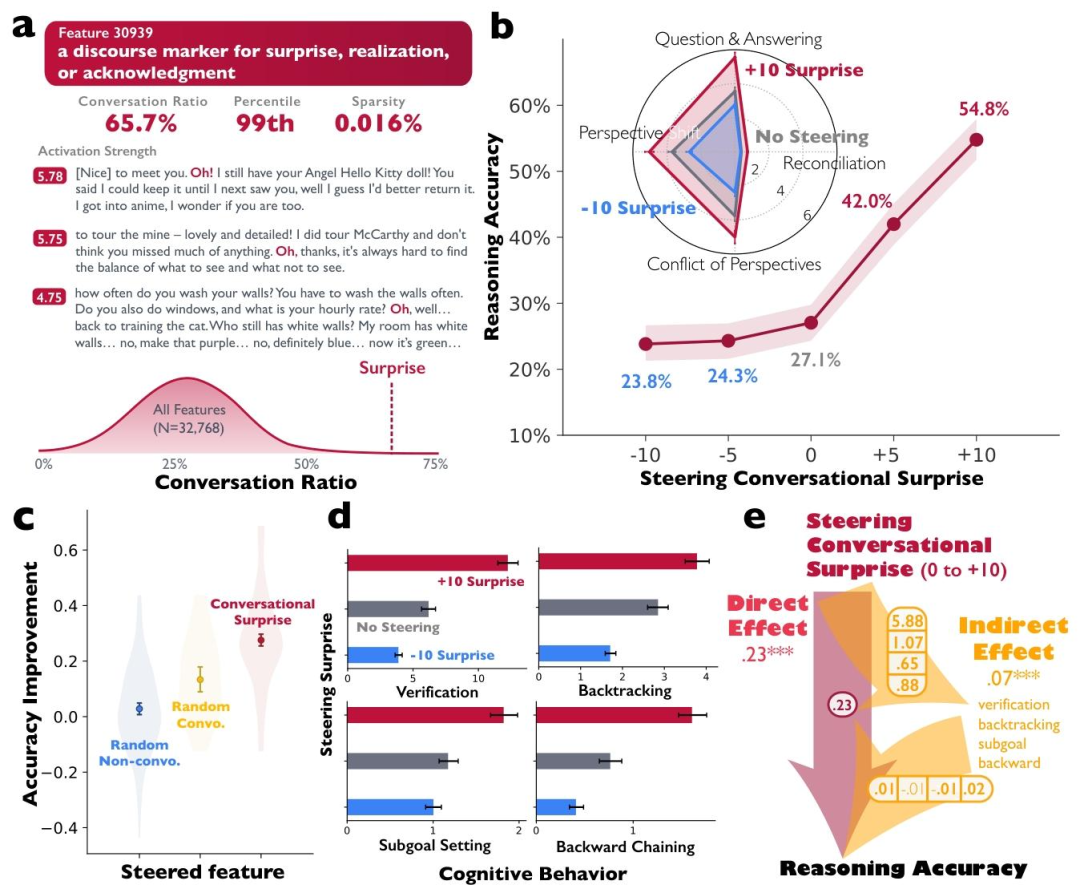
更關鍵的實驗證據來自強化學習訓練。
研究人員不提供任何對話結構的訓練信號,只獎勵模型答對題目的行為,結果發現模型會自發學會用對話式思考;
而先通過多智能體對話數據對模型進行微調,再進行推理訓練,進步速度會遠快於直接訓練推理或用獨白式推理數據微調的模型。
在Qwen-2.5-3B和Llama-3.2-3B兩個模型體系中,早期訓練階段對話微調模型的準確率比獨白微調模型高出10%以上,Llama-3.2-3B到訓練後期差距甚至擴大到22%。
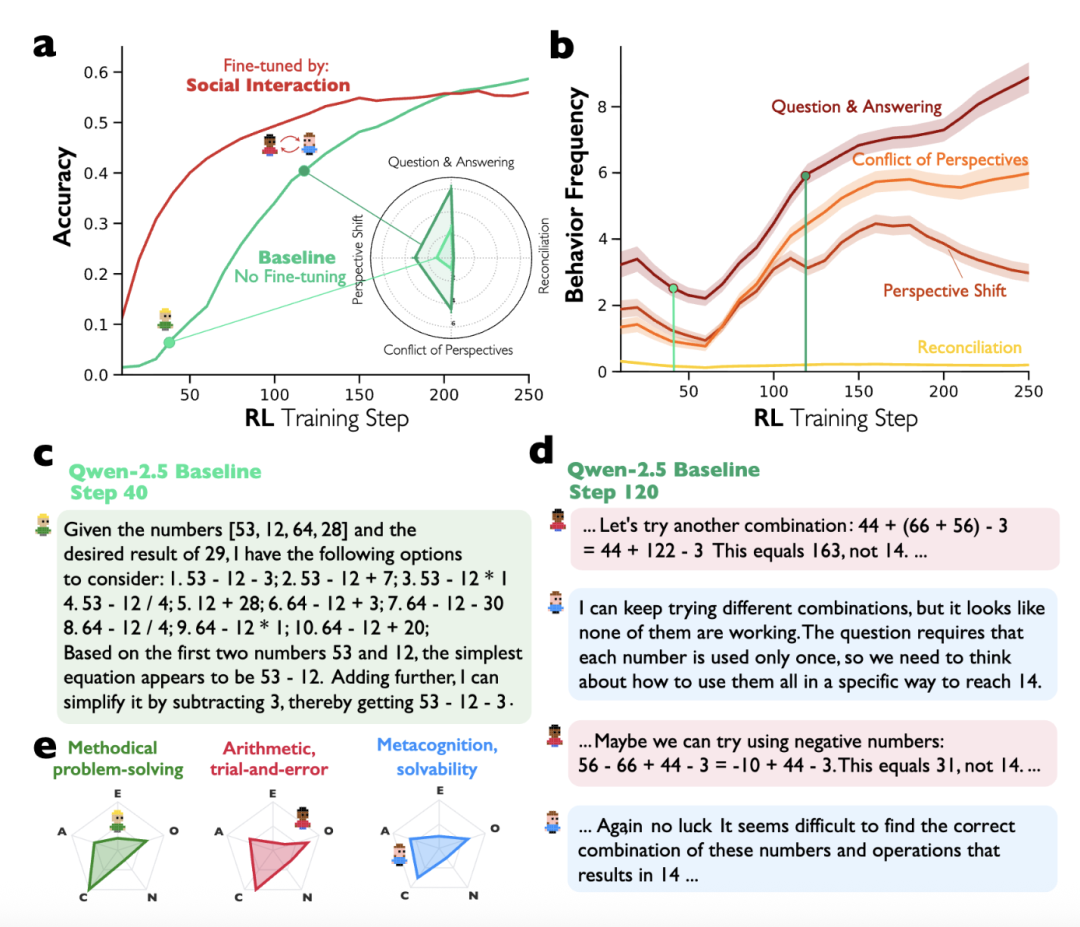
這一發現恰好呼應了人類演化生物學中的著名理論社會腦假說。
假說認為人類大腦的進化主要是為了應對複雜的社交關係和羣體互動需求。
如今看來,AI也是一樣,為了變聰明,得先會和不同「人格」社交!