春節前夕,兩款重量級的AI圖像生成模型在同一個下午接連閃亮登場。
阿里的通義千問發布了Qwen-Image-2.0,字節也在即夢上線了Seedream-5.0。
這對「臥龍鳳雛」究竟好不好用,能不能和Nano Banana Pro掰掰手腕?
我們一起來一探究竟。
01 「字字清晰,張張細膩」的Qwen-Image-2.0
首先來看阿里的新模型Qwen-Image-2.0,可以在Qwen Chat免費使用。
Qwen-Image-2.0是一個生成和編輯一體化的模型,將文生圖和圖像編輯的功能合二為一,模型的架構更加輕量,速度也更快。
在AI Arena的盲測中,該模型在文生圖和圖像編輯基礎測試中都拿到了相當亮眼的分數。
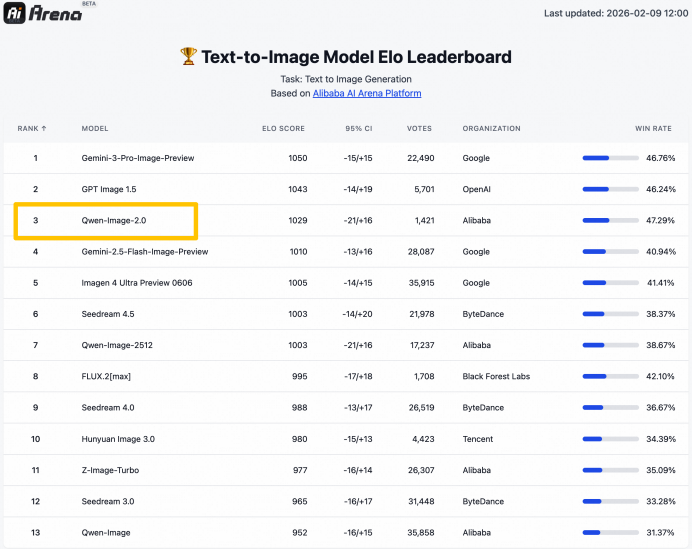
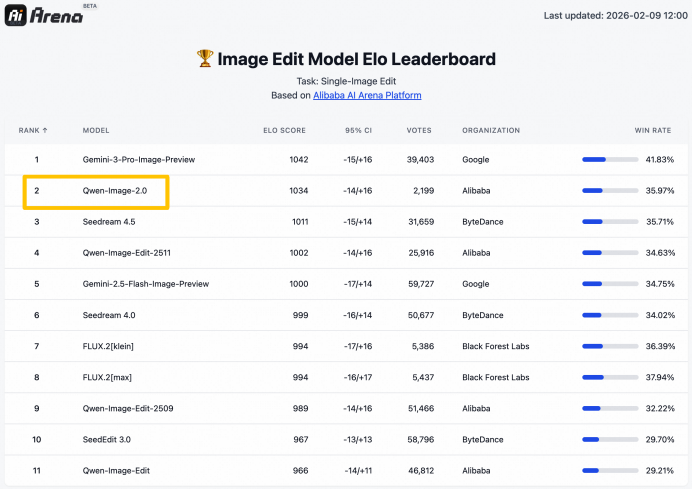
功能上,「字字清晰」背後是Qwen-Image-2.0在文字生成方面的五項能力突破:「準/多/美/真/齊」。
準確性(準):支持1k token超長指令,能夠理解AB測試數據表、PPT時間軸等包含大量信息的複雜圖表。
承載量(多):能處理極高密度的文字信息,生成專業信息圖表。
審美與排版(美):擅長圖文混排,還懂得留白,不會遮擋主體;支持多種書法字體,可以生成有意境的水墨畫。
寫實融合(真):文字能完美融入真實場景的材質和光影中。
對齊與規整(齊):極強的排版對齊能力,適合生成日曆、多格漫畫、流程圖等。
除此之外,圖像畫質也有所提升,該模型支持2k分辨率原生生成,圖像具備更加細膩的質感,能夠準確還原自然場景中複雜的生態細節。
而得益於文生圖和圖像編輯能力二合一,文字渲染和真實質感的優勢也能在圖像編輯任務中得以體現。
模型可以在現有圖片的指定位置添加文字,能生成同一人物的九宮格組圖,甚至跨次元將卡通形象添加到實景照片中。
雖然官方給出的demo十分完美,不過實際能力邊界還得親自測試才能看清。
接下來,開始實戰環節:
Test 1:丞相的北伐PPT彙報
首先,我們來驗證一下模型生成複雜圖表、長文本指令和排版對齊的能力。
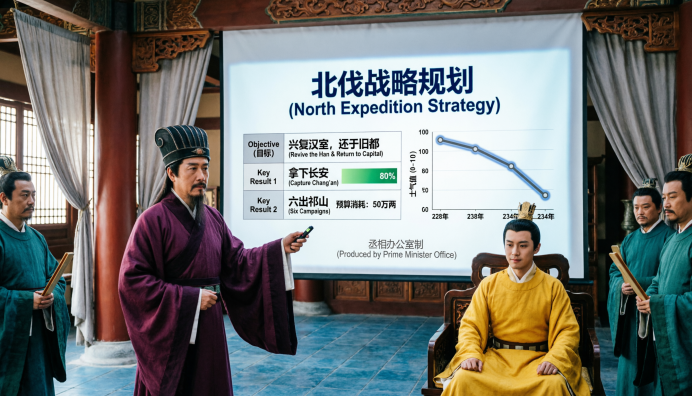
提示詞:諸葛亮正在給劉禪彙報《2026年北伐戰略規劃》,但他不用竹簡了,改用現代PPT。
一張投影在幕布上的現代商務風格PPT,標題是「北伐戰略規劃 (North Expedition Strategy)」。
左側是一個詳細的OKR表格:
Objective(目標):興復漢室,還於舊都 (Revive the Han & Return to Capital)
Key Result 1:拿下長安 (Capture Chang'an),完成度 80% (綠色進度條)
Key Result 2:六出祁山 (Six Campaigns),預算消耗 50萬兩 (Budget: 500k)
右側是一個折線圖,顯示「魏軍士氣」隨時間下降的趨勢,X軸是年份(228-234),Y軸是士氣值。
底部有一行小字:「丞相辦公室制 (Produced by Prime Minister Office)」。
畫面要有真實投影的微光感,文字清晰銳利。
如此複雜的任務,交給以前的AI生圖恐怕只能得到滿屏的亂碼,但千問圖像2.0卻能做到。
圖中的人物清晰,提示詞中的戰略規劃和折線圖齊全,中英文顯示正確,能夠把提示詞中明確寫明的細節全部落實,實在令人感到驚喜。
儘管座標軸縱軸的數字和劉禪坐姿朝向有些問題,但無傷大雅,更何況這些都是未包含在提示詞中的隱含信息。
Test 2:曹操的朋友圈九宮格
這個測試中,我把新三國的曹操照片作為參考圖傳給了模型。
接下來,看看模型的人物一致性、生成寫實人像的能力如何。

提示詞:曹操赤壁戰敗後,為了挽回顏面,發了一組九宮格自拍展示「魏王風采」。
九宮格畫面描述(從左到右,從上到下):
格1(橫槊賦詩): 他站在船頭,手持長矛,面對江面,神情豪邁。
格2(仰天大笑): 他在樹林背景下,頭向後仰,張嘴大笑,神態狂妄。
格3(現代梗): 他坐在簡陋的馬紮上,手裏端着白色的現代泡沫盒餐盒,拿着一次性筷子正在大口吃飯,表情充滿疲憊。
格4(夢中殺人): 他側臥在古代床榻上,雙眼圓睜,眼神充滿殺氣,手按在劍柄上。
格5(嚴肅特寫): 他的正面大頭照,直視鏡頭,眼神深邃多疑,威嚴感極強。
格6(現代梗): 他的臉上戴着一副黑色的現代墨鏡,表情冷酷,背景是古代軍營。
格7(青梅煮酒): 他與對面的人(只露背影)對坐飲酒,手指前方,表情試探。
格8(敗走華容): 他披頭散髮,臉上沾滿灰塵和泥土,神情狼狽驚慌。
格9(現代梗): 他手裏舉着一部亮屏的智能手機,對着自己比「剪刀手」自拍,面帶尷尬而不失禮貌的微笑。
整體來看,生成寫實人像是沒有問題的,無論是喫飯、戴墨鏡還是自拍場景,模型能夠按照提示詞將背景與人物自然融合。
不過,保持人物一致性方面略有瑕疵,圖7和圖8中的人物五官有些走形。推測原因是較短時間的生成過程中難以迅速學習到參考圖中的全部細節特徵。
Test 3:改正城樓上的錯字
下一步驗證文字與材質融合的能力,以及模型在特定區域修圖的能力。

這是關羽溫酒斬華雄時出戰的經典場面。
熟悉三國的朋友們可能會發現,十八路諸侯的會盟地是陳留,而不是城樓上寫的當陽。
試試用模型修復這個錯誤:

提示詞:這是新三國中關羽出戰華雄的場景,不過編劇出了一個小小的錯誤,城樓的牌子上應該寫的是「陳留」而不是「當陽」,請在保持城樓牌子原有風格的基礎上,修復這個錯誤,並讓圖像清晰一些。
模型在重繪過程中成功地把原本模糊的劇照變得更加清晰,並且光照效果也更好。
不過,可能是因為原圖中「當陽」兩個字字體複雜和光線太暗而難以識別,模型只能生成正確的文字,卻難以復刻原圖中的文字版式。
Test 4:馬斯克前來桃園四結義
最後,測試一下模型多圖融合和風格遷移的能力。
同樣是提供了老三國的桃園三結義劇照和馬斯克的照片作為參考圖。

提示詞:這是三國中桃園結義的場景。請將圖2的人物(馬斯克)自然地融入圖1的場景(桃園結義)中,讓他站在劉備的左側,同樣舉着酒杯。統一光影為桃園的柔和自然光,人物穿着要改成漢代風格的長袍,但保留圖2人物的面部特徵。畫面構圖要平衡,四人結義。
還別說,馬斯克身着長衫、舉杯結義還真沒有顯得太違和,提示詞中的要求模型都做到了。
不過,人物佔位還是有些混亂,在多圖融合中,如何控制圖像尺寸和比例是個尚未解決的問題。
評測結果:
幾輪測試下來,Qwen-Image-2.0展現出來的效果還是相當驚人的。
首先,它憑藉強大的文字渲染能力解決了過往AI生圖總是產生中文亂碼的難題。
不僅能把字寫對,還能把字寫好看,並實現複雜的排版,使它生成流程圖、PPT都不在話下,讓文字不再是視覺生成的障礙,極大地提高了實際應用價值。
其次,物理層面上的真實統一也值得讚揚。
雖然暫時無法完美復刻古裝劇中的文字,但模型也體現出對物體表面物理屬性具備一定程度上的理解。同時,它能夠自然處理環境光線和反射,將原有暗淡的圖像變得清晰而鮮明。相比之下,過去的AI修圖更像是在圖像上貼一張貼紙,一眼假。
最重要的是,Qwen-Image-2.0具備了對超長指令的邏輯理解能力。
1k的超長提示詞輸入窗口以及官方demo中的大段提示詞都在向用戶傳達一個信息:
「只要你能說清楚圖裏要有什麼,我就能幫你實現。」
能夠讀懂複雜的指令,是因為它具備大語言模型的知識。
從好玩,到有用,再到好用,千問的這款新模型正在向世界證明:AI生圖已經不再是娛樂工具,而是新一代的生產力工具。
02 「實時檢索+精準編輯+邏輯推理」的Seedream 5.0
相比千問的圖像模型,字節則是將新模型Seedream-5.0預覽版悄悄上線了旗下的剪映APP、即夢和小云雀平台,預計年後將會上線正式版。
該模型目前處於限時免費體驗狀態,不消耗積分。
雖然官方目前尚未發布技術文檔,但早在2月6日就已經公開了用戶手冊。
Seedream-5.0-preview版本主打聯網實時檢索、編輯精準可控和智能邏輯推理三大亮點。
與此同時,研發團隊的態度非常謙虛,坦誠預覽版生成圖像的真實感和美感存在一定效果劣化,並給出了一些可能存在的問題:AI貼圖感較重,人物比例不合理,文字結構不穩定,數據圖表推理能力不足,設計材質質感不足。
當然,字節的多模態能力大家是知道的,研發團隊大可不必妄自菲薄,我們同樣來實際測試一下:
Test 1:接着奏樂接着舞
先來測試聯網實時檢索功能,看看模型生成的結果是否能識別出名人且具備強時效性。
這次我們選用新三國的經典人物劉皇叔以及他的經典台詞:「接着奏樂接着舞」。

提示詞:生成一張《新三國》劉備在現代迪廳蹦迪的照片,穿着古裝,戴着墨鏡,燈紅酒綠,表情享受,並說出他的經典台詞「接着奏樂接着舞」。
不過很遺憾,生成的圖片雖然符合主題,但人物形象卻與新三國的劉備完全不符。
模型在沒有參考圖的情況下,還無法準確地從外部渠道獲取劉備的面貌特徵。
Test 2:曹衝稱象
接下來看看智能邏輯推理功能。
曹衝稱象作為三國中的經典故事之一,需要模型掌握真實世界中的物理重量邏輯以及多步推理能力。

提示詞:曹衝稱象。一條船浮在水面上,船上站着一頭大象,船身喫水很深,水面快要漫過船舷。旁邊對比一張同樣的船,船上只有一隻貓,船身浮得很高。
模型似乎沒能理解物理中的浮力原理,但還是忠實地將提示詞中的內容儘可能展現在了圖片中,儘管文字生成有一些小小的錯誤。
Test 3:商業精英三結義
編輯精準可控主要在指令遵循和特徵遷移兩方面得以體現。
因此我們要測試一下模型是否能根據指令完成跨次元的風格遷移。
原先我準備用此前使用過的桃園結義劇照和馬斯克照片進行測試,無奈上傳到小云雀平台時無法通過審核,因此只能使用了其他桃園結義的AI生圖和西裝模特圖進行測試。

這一次Seedream-5.0沒有讓人失望,模型的指令遵循能力和風格遷移能力確實不錯,在不改變原圖相貌特徵的情況下,順利完成了提示詞中的服飾變更指令。
測評結果:
必須承認的是,給Seedream-5.0的測試題目確實偏難了一些,但結果還是令人有些失望。
從技術角度來看,聯網實時檢索和智能邏輯推理本質上還是大語言模型的強項,而目前的預覽版本中,大語言模型的知識儲備和推理能力尚未完全嵌入到多模態模型圖像生成的過程中。
但是,模型的亮點在於具備極強的指令遵循能力,這表明其文本編碼器同樣非常強大,只要提示詞給得足夠精細,它就能畫得足夠精準。
因此,Seedream-5.0預覽版暫時還不是一個能理解萬物運行規律的物理世界模擬器,也還不能成為一個「實時喫瓜」的新聞配圖機,它更像是一個執行力極強的高級美工。
它只是在畫圖,而不是去模擬這個世界。希望正式版能給我們帶來更多驚喜。