智通財經APP獲悉,2月10日,騰訊混元正式推出一款面向消費級硬件場景的「極小」模型HY-1.8B-2Bit,等效參數量僅有0.3B,內存佔用僅600MB,比常用的一些手機應用還小。通過對此前混元的小尺寸語言模型——HY-1.8B-Instruct進行 2 比特量化感知訓練(QAT)產出,這一模型對比原始精度模型等效參數量降低了6倍,並且在沿用原模型全思考能力同時,在真實端側設備上對比原始精度模型生成速度提升2—3倍,可大幅提升使用體驗。
此次騰訊混元推出HY-1.8B-2Bit模型,可以在邊緣設備上無壓力部署。這也是首個在實現2bit產業級量化的端側模型實踐。此外,HY-1.8B-2Bit模型還沿用了Hunyuan-1.8B-Instruct的全思考能力,用戶可以靈活使用,為簡單的查詢提供了簡潔的思維鏈,為複雜的任務提供了詳細長思維鏈,用戶可以根據其應用的複雜性和資源限制靈活地選擇這兩種模式。
騰訊混元還通過數據優化、彈性拉伸量化以及訓練策略創新三個方法來最大限度的提升HY-1.8B-2Bit的全科能力。
部署方面,騰訊混元提供了HY-1.8B-2Bit的gguf-int2格式的模型權重與bf16僞量化權重,對比原始精度模型,HY-1.8B-2Bit實際模型大小直降6倍,僅有300MB,能夠靈活用於端側設備上。該模型也已在 Arm 等計算平台上完成適配,可部署於啓用 Arm SME2 技術的移動設備上,並實現高效運行。
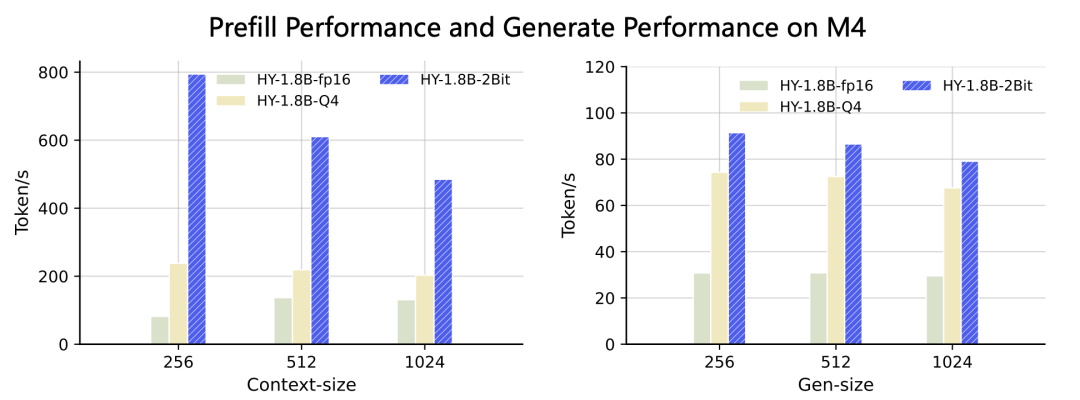
在MacBook M4芯片上,HY-1.8B-2Bit固定了線程數為2測試了不同窗口大小下的首字時延和生成速度,模型選定fp16、Q4、HY-1.8B-2Bit三種gguf格式作為對比,首字時延在1024輸入內能夠保持3~8倍的加速,生成速度上常用窗口下對比原始模型精度,HY-1.8B-2Bit能夠實現至少2倍穩定加速。
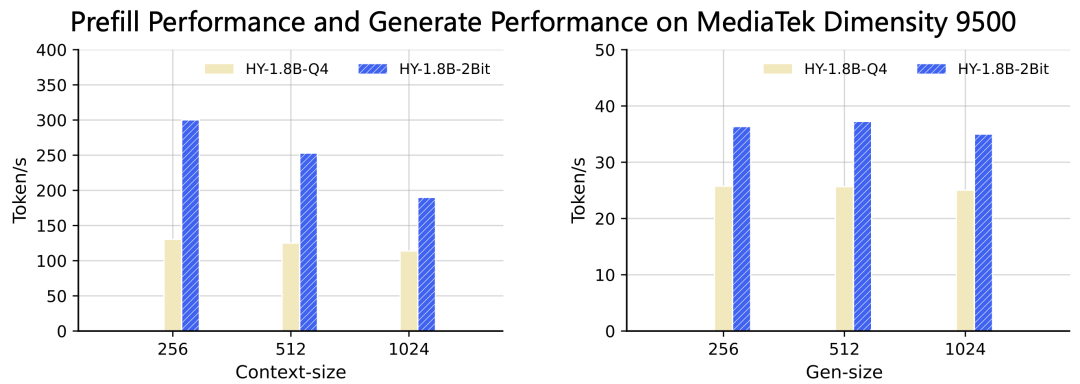
在天璣9500上同樣進行了測試,對比HY-1.8B-Q4格式首字時延能夠加速1.5~2倍,生成速度加速約1.5倍。
為在邊緣設備上實現大語言模型的靈活部署,HY-1.8B-2Bit採用了極低比特量化技術,在保持與INT4-PTQ方法相當模型性能的同時,實現了在端側設備上的高效穩定推理。
當前,HY-1.8B-2Bit的能力仍受限於監督微調(SFT)的訓練流程,以及基礎模型本身的性能與抗壓能力。針對這一問題,混元團隊未來將重點轉向強化學習與模型蒸餾等技術路徑,以期進一步縮小低比特量化模型與全精度模型之間的能力差距,從而為邊緣設備上的大語言模型部署開拓更廣闊的應用前景。