過去一年,生成式人工智能在音樂行業的應用正不斷創造新體驗,但歌唱語音合成領域(SVS,Singing Voice Synthesis)整體進展相對緩慢。
為拓展這一領域,近日,Soul App AI 團隊(Soul AI Lab)聯合吉利汽車研究院人工智能中心(AIC)、天津大學視聽覺認知計算團隊和西北工業大學音頻語音與語言處理研究組(ASLP@NPU),正式開源歌聲合成模型SoulX-Singer,這是一個面向真實應用場景設計的高質量零樣本歌聲合成模型,超42000小時訓練數據,覆蓋多語言、多音色及多種演唱風格,在穩定性、可控性與泛化能力方面,均達到了當前開源 SVS 模型中的領先水平。
 Demo Page:
Demo Page:
HYPERLINK "https://soul-ailab.github.io/soulx-singer/" \t "https://mp.weixin.qq.com/_blank" https://soul-ailab.github.io/soulx-singer/
Technical Report: HYPERLINK "mailto:https:/arxiv.org/pdf/2602.07803" https://arxiv.org/pdf/2602.07803Source Code:
HYPERLINK "https://github.com/Soul-AILab/SoulX-Singer" \t "https://mp.weixin.qq.com/_blank" https://github.com/Soul-AILab/SoulX-Singer
Hugging Face: HYPERLINK "https://huggingface.co/Soul-AILab/SoulX-Singer" \t "https://mp.weixin.qq.com/_blank" https://huggingface.co/Soul-AILab/SoulX-Singer
SoulX-Singer介紹
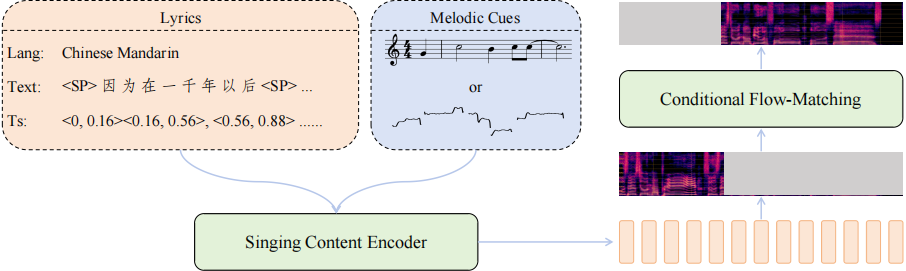 SoulX-Singer 結構簡圖
SoulX-Singer 結構簡圖
過去一段時間,語音合成與音樂生成領域迎來了快速發展,大模型與生成式 AI 持續刷新行業認知。然而,與這一熱潮形成對比的是,行業內仍缺乏一個真正穩定可用、同時支持零樣本(Zero-shot)生成的開源歌聲合成(SVS)模型,這很大程度上制約了 SVS 技術在真實業務場景中的應用與落地。
SVS(Singing Voice Synthesis,歌唱語音合成)是一種根據歌詞和樂譜生成歌聲的技術。相比於普通語音合成(TTS,Text-to-Speech Synthesis),SVS 需要對音高、音律以及演唱風格等進行精細控制,以實現自然且富有表現力的歌聲輸出。與近期熱門的 Music Generation(自動生成整段音樂或伴奏)不同,SVS 專注於可由 MIDI 控制的人聲生成,因此在虛擬歌手、歌詞演繹以及多語言歌聲創作等場景中展現出獨特價值。
在這樣的背景下,SoulX-Singer 正式開源。SoulX-Singer 是一個面向真實工業應用場景設計的零樣本歌聲合成模型,其核心目標是在未見過歌手音色的情況下,實現穩定、自然且高度可控的歌聲生成。為此,模型在整體架構、建模範式以及控制機制上進行了針對 SVS 場景的系統性設計。
在模型架構上,SoulX-Singer 採用基於Flow Matching 的生成建模範式,並將歌聲合成問題建模為一種 audio infilling(音頻補全)任務。針對歌聲合成中「歌詞—旋律—發聲」三者強耦合的特點,SoulX-Singer 在建模階段顯式引入了note 級別的對齊機制。
模型通過構建歌詞、MIDI 音符(note)與聲學特徵之間的精細對齊關係,使得每一個音符的起止時間、音高(pitch)以及持續時長都能夠被準確建模和獨立控制。這一設計使得模型不僅能夠忠實還原樂譜信息,還可以在生成階段靈活調整音符結構,從而滿足音樂編輯、重編曲等複雜需求。
大規模 SVS 訓練數據,夯實零樣本能力基礎
零樣本歌聲合成對訓練數據的規模、多樣性與覆蓋範圍提出了極高要求。SoulX-Singer 得益於超過 42000 小時的高質量歌聲數據進行訓練,覆蓋多語言、多音色及多種演唱風格。
在如此大規模數據的支持下,模型在面對未見過的歌手與複雜音樂條件時,依然能夠保持穩定、自然且高質量的合成表現。在實際測試中,SoulX-Singer 展現出了良好的魯棒性和一致性,為零樣本歌聲合成技術從「可演示」走向「可使用」提供了堅實基礎。
Music Score 與 Melody 多種控制方式
在生成控制能力方面,SoulX-Singer同時支持基於Music Score(MIDI)和基於 Melody的兩種歌聲合成控制方式:
Music Score(MIDI)驅動生成支持直接基於樂譜與歌詞生成歌聲,適用於音樂創作、歌詞編輯、歌曲重製等場景,具備音符級別的時長與節奏控制能力。
Melody驅動生成支持從已有歌曲旋律出發進行歌聲合成,可復刻參考音頻中的演唱技巧與表達方式,適用於翻唱、風格遷移等應用場景。
這種雙控制範式為實際音樂製作流程提供了更高的靈活性,使SoulX-Singer能夠覆蓋從「從零創作」到「基於已有歌曲再創作」的多種使用需求。
多語言支持,面向真實應用場景
SoulX-Singer 當前支持普通話、英語和粵語三種語言的歌聲合成,並在不同語言和音樂風格下均展現出穩定一致的合成質量。這一多語言能力為其在內容創作、虛擬歌手、互動娛樂等應用場景中的落地提供了更廣闊的空間。
客觀表現
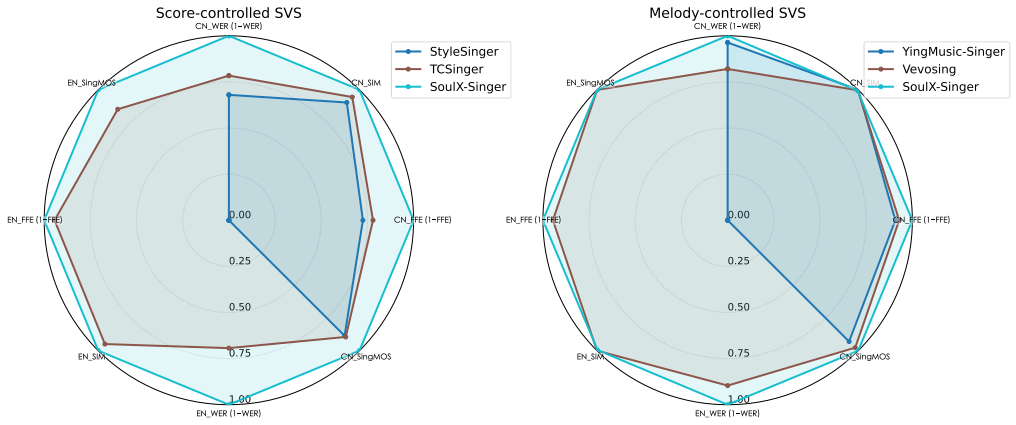
在評測方面,SoulX-Singer 在GMO-SVSSoulX-Singer-Eval兩個數據集上,對零樣本歌聲合成、歌詞編輯後的歌聲合成以及跨語言歌聲合成等多項任務進行了系統評測。
其中,GMO-SVS 綜合了GTSinger、M4Singer 和 Opencpop等主流開源 SVS 數據集;而 SoulX-Singer-Eval 則專門面向嚴格的零樣本場景構建,通過獨立音樂人等渠道採集數據,確保測試歌手未出現在訓練集中。
實驗結果表明,SoulX-Singer 在語義清晰度、歌手相似度、基頻一致性以及整體合成質量等多個維度上均顯著優於此前的相關工作;在主觀聽感評測中,其表現同樣取得了明顯領先優勢。
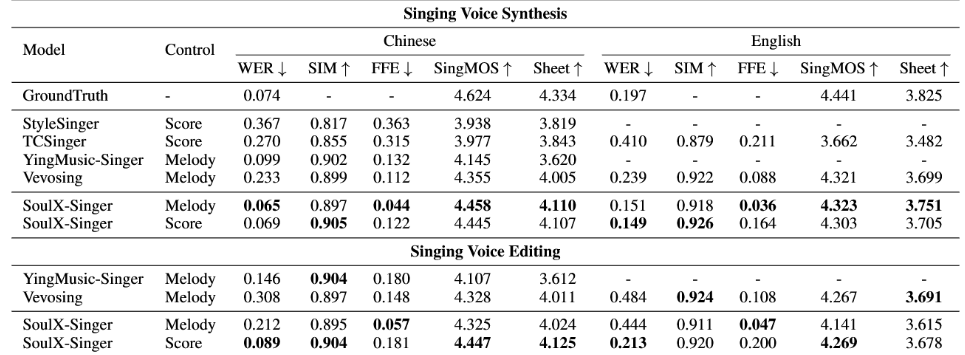
儘管此前歌聲合成領域已經湧現出一些優秀的研究工作,但受限於訓練數據規模或控制方式單一等因素,相關模型在真實使用場景中仍面臨諸多挑戰。SoulX-Singer 的發布提供了一個真正魯棒、靈活可控且面向場景落地的零樣本歌聲合成解決方案,為歌聲合成技術在UGC音樂創作等方向的實際應用探索帶來了積極意義。
SoulX-Singer 也延續了Soul AI團隊的開源工作。此前,Soul AI團隊已陸續開源了播客語音合成模型SoulX-Podcast、實時數字人生成模型SoulX-FlashTalk,在語音、歌聲、實時數字人、視頻等不同領域提供了可落地的多模態生成方案。
港股頻道更多獨家策劃、專家專欄,免費查閱>>