阿里未來生活實驗室 投稿
量子位 | 公衆號 QbitAI
MoE(混合專家模型)已經成為大模型時代的「版本答案」。
從GPT-5到DeepSeek-V3,幾乎所有最強模型背後都有MoE的影子。
但你是否想過:你模型裏那幾十個「專家」,可能都在幹同一件事?

在MoE預訓練中,原本期望這些專家「各司其職」,最後發現他們竟然「同質化」了?學術界將這種現象稱為「專家同質化」(Expert Homogenization)。這直接導致了MoE模型參數的浪費和Scaling能力的封頂。
來自阿里巴巴未來生活實驗室的研究團隊認為,這背後是MoE預訓練過程中的信息缺失。
為了解決這一頑疾,來自阿里巴巴集團的研究團隊提出了一種全新的專家分化學習(Expert Divergence Learning)策略。他們利用預訓練數據中天然存在的「領域標籤」,設計了一種新的輔助損失函數,鼓勵不同領域的Token在路由統計信息上表現出差異,從而引導專家分化出真正的專業能力。
這一研究(Expert Divergence Learning for MoE-based Language Models)已中稿ICLR 2026。
核心洞察:多樣性≠有效分工
為什麼傳統的MoE訓練會導致專家同質化?團隊在論文中揭示了一個被長期忽視的數學盲區。
現有的負載均衡損失(Load-Balancing Loss)雖然能提高總的路由多樣性(Total Divergence),但它是一種「盲目」的提升。它只在乎「所有專家都被用到了」,卻不在乎「是被誰用到的」。
這就好比公司發獎金,只看大家是不是都忙起來了,卻不管是不是所有人都在重複造輪子。
阿里團隊提出,真正的專家化,應該建立在「領域差異」之上。需要將總的路由多樣性,通過數學手段引導到「域間差異」(Inter-Domain Divergence)上。
基於此,他們提出了專家分化學習(Expert Divergence Learning)。
硬核方法論:如何在預訓練中強迫專家「分家」?
為了打破僵局,阿里團隊提出了一種純粹的、即插即用的訓練目標函數——專家分化損失(Expert Divergence Loss, LED)。
它的設計靈感來源於一個優美的數學直覺:MoE的路由多樣性是可以被「解構」的。
數學原理:多樣性分解定理(Divergence Decomposition)
論文在理論部分使用了一個關鍵公式:
總多樣性(Dtotal) =域間多樣性(Dinter) +域內多樣性(Dintra)
傳統做法的缺陷:以前的負載均衡Loss只是盲目地推高左邊的Dtotal。但在缺乏引導的情況下,模型傾向於通過增加Dintra(讓同一個領域的Token亂跑)來應付考試,而不是增加Dinter(讓不同領域的Token分開跑)。
新方法的Insight:LED的本質,就是精準鎖定並最大化Dinter。它通過最大化不同領域之間的「排斥力」,分配總多樣性的額度給「域間差異」,從而迫使專家發生功能分化。
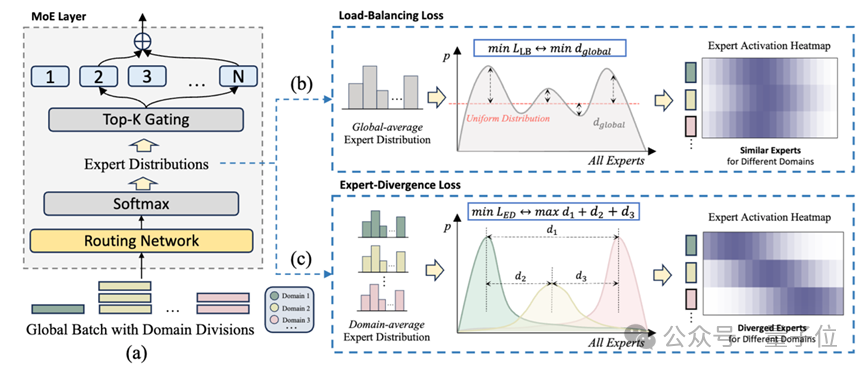
幾何直觀:把專家「推」向邊緣
這個Loss的計算過程可以拆解為三步:
第一步:從Token到領域(Aggregation)在訓練過程中,模型通常會接收到不同來源的數據(如數學題、代碼片段、新聞)。算法首先計算出當前Batch中,屬於「數學域」的所有Token的平均路由分佈,以及屬於「代碼域」的平均路由分佈。
第二步:計算「排斥力」(Divergence Computation)有了不同領域的平均路由分佈,如何衡量它們的差異?團隊選擇了JS散度(Jensen-Shannon Divergence)。
JS散度是對稱且有界的,非常適合用來衡量兩個概率分佈的「距離」。
如果「數學專家組」和「代碼專家組」的人員構成高度重疊,JS散度就會很低。
如果它們使用的是兩套完全不同的人馬,JS散度就會很高。
第三步:最大化差異(Optimization)LED的最終目標,就是最大化所有領域對之間的JS散度。
這相當於給梯度下降過程施加了一個強大的「排斥力」:「數學題正在往1號專家那裏跑,那麼寫代碼的Token請儘量離1號專家遠一點!」
通過這種顯式的監督信號,模型不再是隨機地分配專家,而是被迫學習出一種與語義高度對齊的路由策略。
粒度實驗:49類標籤>3類標籤
這種分化學習,分得越細越好嗎?
為了驗證這一點,研究團隊構建了兩種不同粒度的領域標籤體系:
1. 粗粒度(3-Class):簡單分為英文、中文、數學。
2. 細粒度(49-Class):利用分類器將數據細分為49個具體主題(如物理、歷史、計算機科學、法律、醫學等)。
後續實驗結果呈現出明顯的「粒度縮放定律」:使用49類細粒度標籤訓練的模型,性能顯著優於使用3類標籤的模型。
這說明,給專家的分工指令越具體(例如:「不僅要區分文理,還要區分物理和化學」),MoE模型湧現出的專業能力就越強。
實驗實錘:SOTA性能與可視化證據
研究團隊在3B、8B、15B三種規模上,進行了長達100B Tokens的從零預訓練(Training from scratch)。
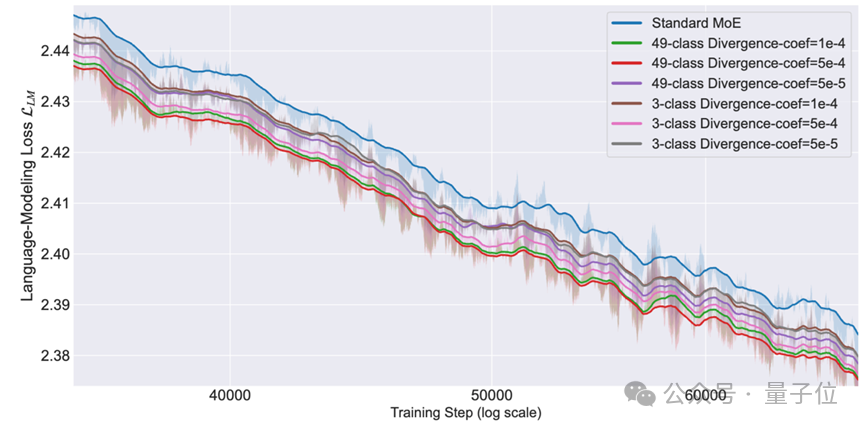
在預訓練階段最重要的訓練損失對比上,專家分化學習在語言建模損失上展現出來穩定且顯著的訓練收益。
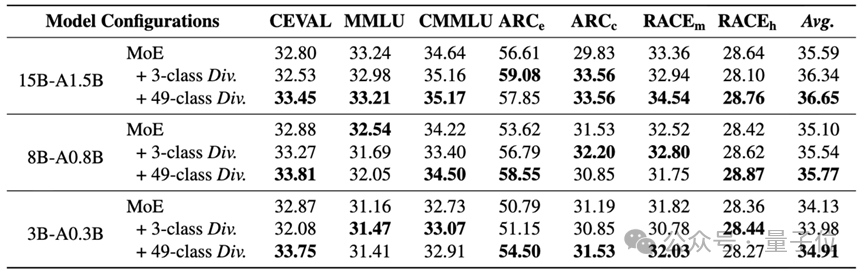
全面超越基線在MMLU、C-Eval、CMMLU、ARC等7個主流基準測試中,搭載了專家分化學習的模型全面超越了標準MoE基線。特別是在15B模型上,細粒度策略帶來的平均分提升超過1個百分點——在預訓練領域,這通常意味着數百億Token的訓練差距。
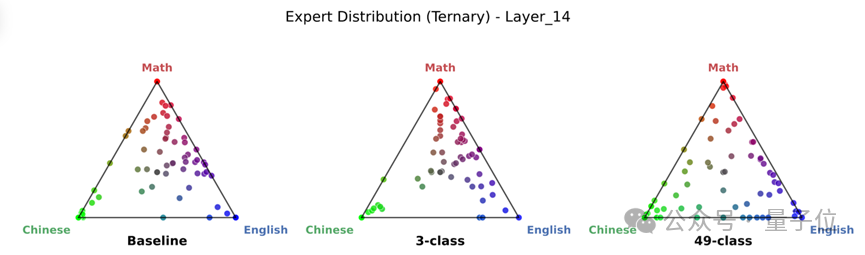
可視化:一眼看穿「僞專家」與「真專家」
為了直觀展示專家是否真的「分家」了,團隊繪製了極具說服力的三角單純形圖(Ternary Simplex Plot)。
下圖中,三角形的三個頂點分別代表「數學」、「中文」、「英文」三個純粹領域。
左圖(Baseline):所有的點都擠在三角形中間。這說明無論輸入什麼領域,激活的專家都差不多,專家是混日子的「通用工」。
右圖(Ours):點明顯向三角形的三個頂點發散,緊貼邊緣。這證明處理數學的專家、處理中文的專家,已經是兩撥完全不同的人馬,實現了真正的專精特新。
不僅效果好,還省資源值得一提的是,LED計算非常輕量級,僅涉及Router輸出的低維向量運算。實驗數據顯示,相比標準MoE,新方法的訓練吞吐量幾乎沒有下降(TPS保持一致),且額外推理成本為零。

總結
阿里團隊的這項工作(Expert Divergence Learning),並沒有盲目地堆砌算力或修改模型架構,而是從損失函數的數學本質入手,重新思考了MoE的「專家」定義。
它證明了:利用數據中天然存在的「領域結構」作為監督信號,是挖掘MoE潛力的最高效途徑。同時,這種充分挖掘語料「立體結構信息」的訓練範式,在高質量數據日趨枯竭的今天,或許能幫助預訓練突破瓶頸,走向一個新的Scaling維度。