
進入2026年以後,很少有人再提起圖像生成模型,行業內的焦點全在agent身上。
圖像生成模型,似乎已經成為「上一個時代」的故事。大多數從業者的共識是,圖像生成的技術路線已經基本定型,剩下的只是工程優化和成本控制。
國際調研機構Fundamental Business Insights在《AI圖像生成器市場規模和份額預測》中提到,2024年全球市場規模為4.1024億美元,2025年為4.785億美元,2026年為5.4136億美元。
由此可見,圖像生成模型市場已然是一個成熟穩定,且想象空間比較小的市場。
可就在這個節骨眼上,谷歌拿出了Nano Banana 2。
這是用同樣提示詞生成的圖片,可以看到,Nano Banana 2在呈現圖片的方式上,已經和Nano Banana Pro呈現出了明顯的區別。
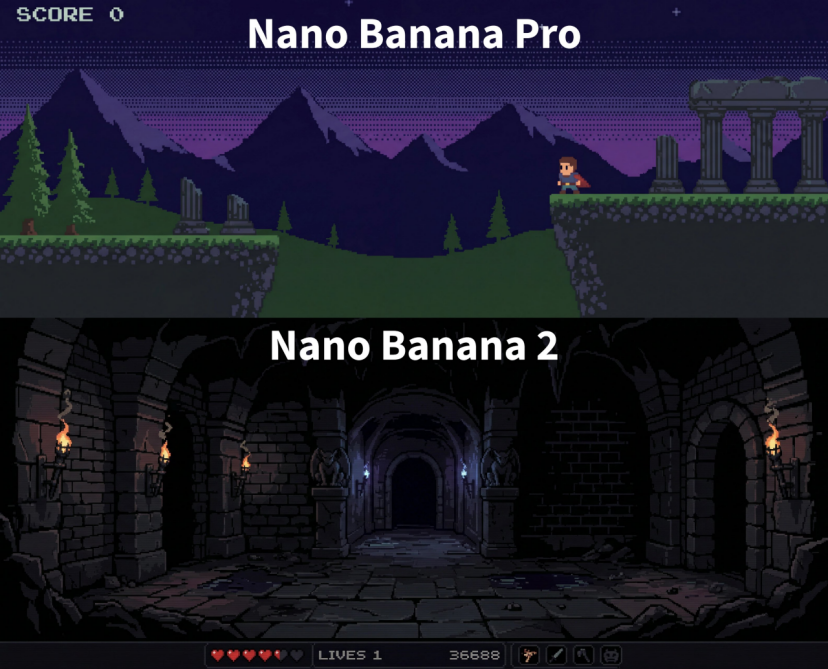
因為這不是那種簡單的版本迭代。
谷歌在發布當天就宣佈,這個新模型將立即取代之前的所有版本,成為 Gemini、谷歌搜索、AI Studio等所有產品中的默認圖像生成模型,最讓人詫異的是,就連谷歌自己的AI編程工具Antigravity也對Nano Banana 2完成了接入。
為啥谷歌突然「All-in」?
在過去一段時間裏,用戶一直面臨着一個兩難選擇,想生成4K分辨率的圖片就需要等很久,想立刻生成圖片,就只能找低分辨率的模型。
而Nano Banana 2又快又好。
谷歌認為,在agent時代,圖像生成依然是一個值得重倉投入的戰場。
01
Nano Banana 2的特點都有什麼?
Nano Banana 2最大的特點就是快,它能夠在4-6秒內完成4K分辨率圖像的生成。
谷歌的Gemini系列一直維持着兩條產品線:Pro追求性能,Flash追求效率。
但將這套架構遷移到圖像生成領域,並非簡單的模型壓縮。圖像生成的計算密集度遠高於文本生成,一張2K分辨率的圖像包含的信息量,相當於數千個文本token。
如何在不犧牲視覺質量的前提下提升推理速度,這是一個工程難題。
Nano Banana 2的解決方案是採用了分層生成策略。
模型首先在較低分辨率下完成場景理解、構圖規劃和物理關係推理,然後再通過高效的上採樣管道將圖像提升至2K甚至4K分辨率。
這種「先思考,後渲染」的流程,讓模型能夠在保持Pro級別的一致性和細節質量時,降低計算成本。
除了速度,Nano Banana 2還引入了「世界知識」這個概念。
傳統的圖像生成模型,本質上是一個強大的視覺模式匹配器。它們在海量圖像數據上訓練,學會了「什麼樣的畫面看起來真實」,但並不真正理解畫面中的物理規律、地理特徵或文化背景。
比如說你要求生成「巴黎鐵塔在雨天的景象」,它可能生成一張看起來不錯的圖片,但鐵塔的結構細節、巴黎特有的建築風格、雨天的光線特徵,都可能是模糊或錯誤的。
Nano Banana 2的不同之處在於,它直接繼承了Gemini大語言模型的世界知識庫,並且能夠實時調用谷歌圖像搜索作為「視覺參考庫」。
也就是說當你要求生成某個真實地點的場景時,模型不僅知道這個地點的地理位置、氣候特徵、建築風格,還能檢索相關的真實照片作為視覺基準,從而生成更加準確的圖像。
在谷歌的「Window Seat」演示中。它能夠根據用戶指定的任何地點和當前的實時天氣數據,生成該地點窗外的逼真景觀。
舉個例子,《哈利波特》中通往霍格沃茨的9¾站台位於英國的國王十字車站(King's Cross station)。在Window Seat中輸入對應車站,窗戶的樣式輸入溫馨咖啡館,外面的天氣指定為瓢潑大雨,Nano Banana 2就會生成以下一幕。

把「世界知識」注入到Nano Banana 2裏,其實就是將大語言模型的推理能力與圖像生成的渲染能力結合起來的產物。
模型在生成圖像之前,會先進行一次「語義推理」,理解提示詞中涉及的真實世界概念,然後再將這些概念轉化為視覺元素。
在圖像生成領域,文字渲染一直是一個公認的難題。無論是Stable Diffusion、Midjourney還是早期的DALL-E,生成的圖像中如果包含文字,往往會出現字母錯位、拼寫錯誤、字體混亂等問題。
這個問題的根源在於,傳統的擴散模型將文字視為視覺紋理的一部分,而不是具有語義結構的符號系統。
Nano Banana 2在文字渲染上取得了顯著進步。根據官方說明,這一代模型能夠「更可靠地渲染文字」,支持多語言文本,並且能夠保持字體的清晰度和風格一致性。
這個能力的提升,來自於模型對文字的「雙重理解」。Nano Banana 2既通過Gemini的語言模型能力,理解了文字本身的語義內容,也通過圖像生成的渲染能力理解文字的視覺呈現規律。
我讓Nano Banana 2設計了一個「字母AI」的Logo,它就能很好展示出每一個字,並且還用電路板這個視覺元素來強化AI的概念。
02
Nano Banana 2背後的技術是什麼?
Nano Banana 2 的另一個重要特性,是它的「對話式編輯」能力。這的確不是一個新概念,但實際用起來效果要比以往好很多。
Nano Banana 2現在能夠做到,完全使用對話來進行圖片編輯,比如「把背景換成日落」、「把這個人的衣服改成藍色」、「去掉左邊的那棵樹」。
這種交互方式的關鍵,在於模型能夠在多輪對話中保持對圖像的「記憶」。當你在第三輪對話中說「把剛纔那個藍色衣服改回紅色」時,模型需要知道「剛纔那個藍色衣服」指的是第二輪編輯中被改成藍色的那件衣服。
這種上下文追蹤能力,叫做「思維簽名」(Thought Signatures)。
簡單來說,當模型生成圖像時,它內部會進行一系列思考,思維簽名就是每一步思考的標籤。在多輪對話編輯圖像時,你把上一輪的思維簽名傳回給模型,它就能記住之前的構圖邏輯、光影關係和設計意圖,從而實現連貫的局部修改—。
當你要求對已有圖片進行修改時,那麼模型就會用思維簽名來理解原始圖像的整體結構,做出合理的調整而不破壞畫面的一致性。
前文提到的一致性,是目前圖像生成模型最大的難題之一。
Nano Banana 2支持最多14張參考圖像的混合使用,其中可以包括最多5張人物角色圖像和最多6張物體圖像。
模型能夠從這些參考圖像中提取視覺特徵,並在新生成的圖像中保持這些特徵的一致性。
比如Nano Banana 2官方發的圖片,將一個香蕉和恐龍玩偶結合,就得到了一個以香蕉當作身體的恐龍玩偶。

以及,我們不妨來看看Nano Banana 2和GPT的對比,同樣的提示詞下,GPT帶有明顯的AI生成感。Nano Banana 2生成的圖片更真實一些。
GPT:

Nano Banana 2:

同時,Nano Banana官方還放出了一些由Nano Banana 2生成的超長圖片。


03
相較於其他模型,Nano Banana 2的優勢是什麼?
Nano Banana 2是一個非常均衡的圖片生成模型,它又有速度,又有質量,關鍵還便宜。
根據谷歌官方給出的信息,Nano Banana 2生成1k圖的價格大約為0.067美元,相當於不到5毛錢。2K圖片為0.1美元,約7毛錢。4K圖片為0.15美元,大約1塊錢。這個價格比Nano Banana Pro便宜很多。
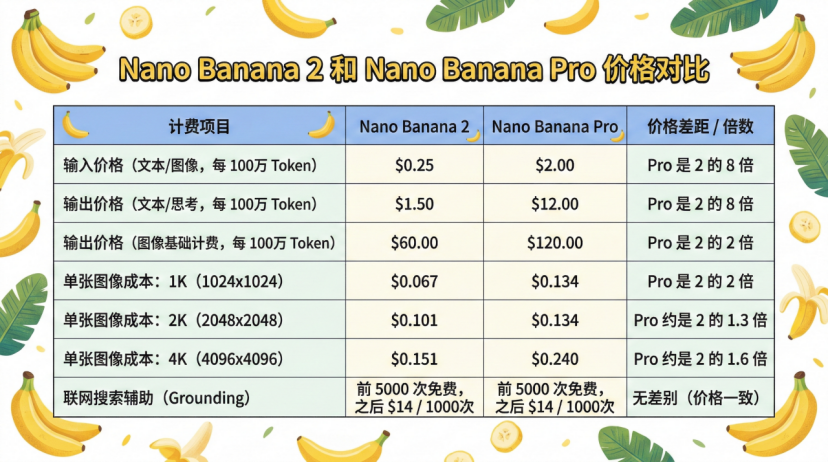
Pro版本的優勢在於極致的複雜場景把控、超寫實光影渲染和小衆藝術風格還原,適合專業視覺設計師、影視概念設計師等對畫質有極致要求的用戶。
Nano Banana 2用畫質上限的稍許讓步,換來了顯著的效率提升。Nano Banana 2的定價更符合普通創作者,以及那些需要快速迭代、大批量生成的實際業務需求。



Midjourney依然是藝術創作的天花板。它的審美上限和風格化能力在行業內無人能及,特別是在生成具有電影質感、繪畫筆觸的藝術作品方面表現出色。
V7版本的生成速度約為20秒/張,在複雜場景下可能更長。
但Midjourney的短板也極其明顯,它沒有對話式編輯功能,無法精準控制真實世界元素(如特定地點的準確建築風格、實時天氣條件), API開放度極低,且主要通過Discord 界面操作,不適合企業級集成。
此前,在一項包含50多個提示詞的對比測試中,Nano Banana Pro的生成速度是Midjourney的10倍以上,Nano Banana 2只會更快。
另外一大圖像生成模型就是Stable Diffusion 3。它的優勢是開源、可本地部署、自定義程度高,這對於有技術能力和數據隱私需求的開發者來說是重要優勢。
它還支持LoRA微調、ControlNet等高級控制功能,可以針對特定需求進行深度定製。可以說,只要你技術能力夠高,那麼Stable Diffusion 3絕對是最好的選擇。
但Stable Diffusion 3,需要配置本地環境、理解複雜的參數設定、自行優化提示詞。
而且在原生能力方面,Stable Diffusion 3的文字渲染準確度在學術評測中得分僅為1.25-1.95(滿分 5 分),遠低於Nano Banana 2。
此外,它的生成速度、事實準確性、對話式編輯能力也全面落後於Nano Banana 2。
當然,Nano Banana 2並非完美無缺。在極致的藝術風格化創作、超複雜場景的光影渲染上,它和Nano Banana Pro以及Midjourney這樣的產品,依然存在差距。
在多輪對話編輯方面,雖然模型支持最多5個角色的一致性維護,但在一些特定的場景,仍然會出現細微變化。而當對話進行多輪次後,這些細微的變化也會累積在一起。
同時,對於小衆冷門的地點、物體,「世界知識」的效果也會有所折扣。
但不可否認的是,Nano Banana 2給整個文生圖行業帶來新的啓示,未來的AI圖像生成,不再是單純的「紋理匹配」,而是「大語言模型推理能力 + 視覺渲染能力 + 檢索增強事實準確性」的深度融合。
文生圖工具終將從「畫畫的機器」,變成真正懂需求、懂世界的視覺創作助手。