
本文來自微信公衆號:硅谷101,作者:張珺玥,原文標題:《全面解析「世界模型」:定義、路線、實踐與AGI的更近一步》,頭圖來自:AI生成
如今的AI看起來似乎「無所不能」:能寫深奧的論文、複雜的代碼,做出頂級的畫面和視頻。然而,它仍然缺乏理解世界、預測世界以及在世界裏推演並行動的能力。
而為了解決這個問題,OpenAI、谷歌、微軟等大公司,Yann LeCun、李飛飛等頂尖學者都開始搶着研究同一件事,那就是——世界模型。
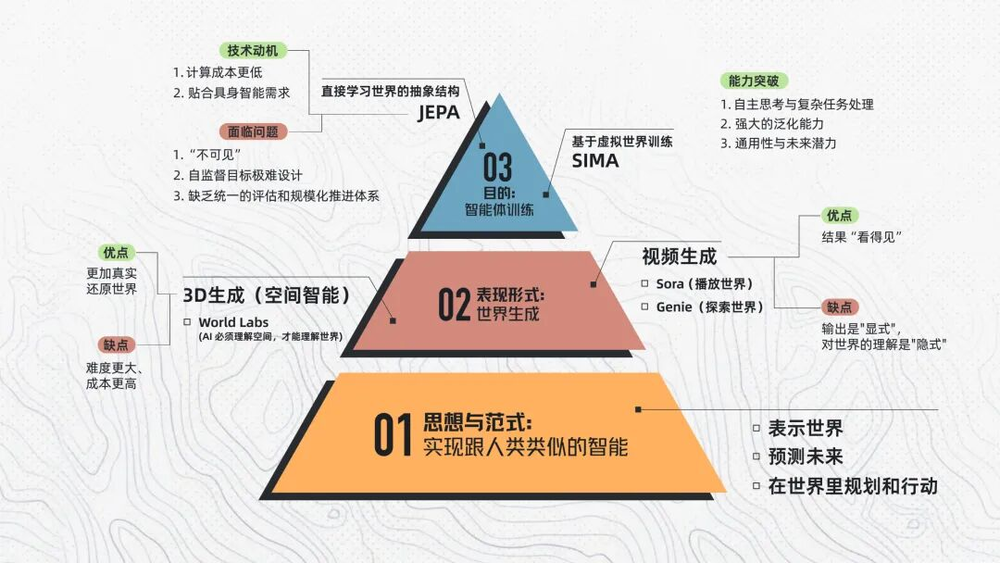
不少AI科學家認為,隨着多模態走向普及和成熟,如果這條技術線完全跑通,它將徹底重塑整個AI格局。但我們也注意到,「世界模型」的爆火也帶來了新的問題:彷彿整個AI圈,一夜之間都變成了「世界模型」:無論是做視頻生成的、做機器人的,還是自動駕駛、遊戲開發等等,只要跟「世界」沾點邊,幾乎都是世界模型。
世界模型到底是什麼,它跟大語言模型有什麼區別?這些看起來完全不同的路線,是在做同一件事嗎?世界模型的到來,又會給各行各業以及整個社會帶來什麼樣的改變?以及,它會是人類通往AGI的終極密碼嗎?
一、什麼是世界模型?
關於世界模型的定義,目前仍然還沒有一個非常清晰的、被所有人都認可的說法。但我們可以先來聊一聊這個概念的起源,以及它究竟想解決什麼事情。
先從一個再簡單不過的問題開始:你是怎麼知道,一杯水放在桌邊,它可能會掉下去的呢?
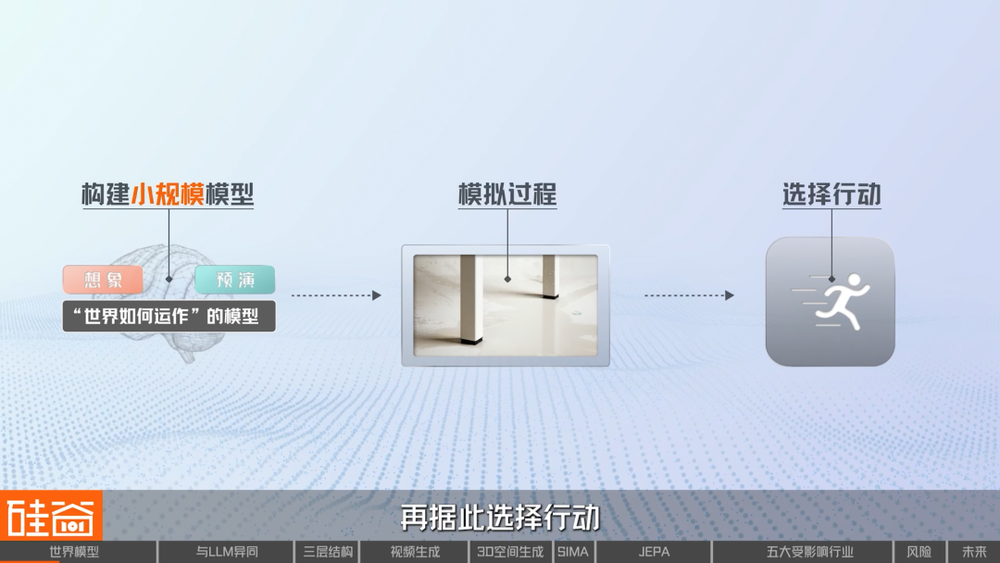
科學家們認為,人類之所以能預測杯子會掉落、門往哪邊開、球會順着斜坡滾,是因為從很小的時候,我們就在腦子裏構建了一個「世界怎麼運作」的模型。我們能預判下一秒會發生什麼,能想象「如果我這麼做,會怎麼樣」,並在腦海中提前排演各種可能性,在認知科學中,這被稱為心智模型(Mental Model)。
早在上個世紀,科學家們就已經開始研究人類的心智模型。1943年,Kenneth Craik在其著作《解釋的本質》中就提出:人在對現實作出反應之前,會先在大腦中構建一個「小規模的世界模型」,用它來模擬可能發生的過程,再據此選擇行動。也就是說,我們每個人腦子裏,都有一個看不見的「小世界」。
既然人類智能依賴於這樣的內部世界,很多AI研究者也開始追問:機器要想具備真正的智能,是否也需要一個屬於自己的世界?
於是,在AI和強化學習的早期研究中,這個思想以不同的名字反覆出現。比如在1991年,Richard Sutton、Doina Precup和Satinder Singh在論文《An Integrated Architecture for Learning, Planning, and Reacting》中提出了後來被稱為Dyna架構的設計思路。
Dyna的核心在於:智能體在學習行動策略的同時,也要學習model of the world。也就是,當我採取某個動作之後,世界會如何變化,這也是第一次將「世界模型」明確確立為智能體內部的一項基礎能力。

在此之後,世界模型並沒有沿着單一路線發展,而是在不同研究領域中被不斷拆解、強化和改寫。比如在強化學習和機器人中,它體現為Forward Model;在自動控制和工業系統中,則發展出了Model Predictive Control(模型預測控制)。

這些理論的名字雖然不同,但背後共享着同一個核心假設:智能體之所以能做出更好的決策,不是因為反應更快,而是因為它能在行動之前,在內部世界中先「看到未來」。
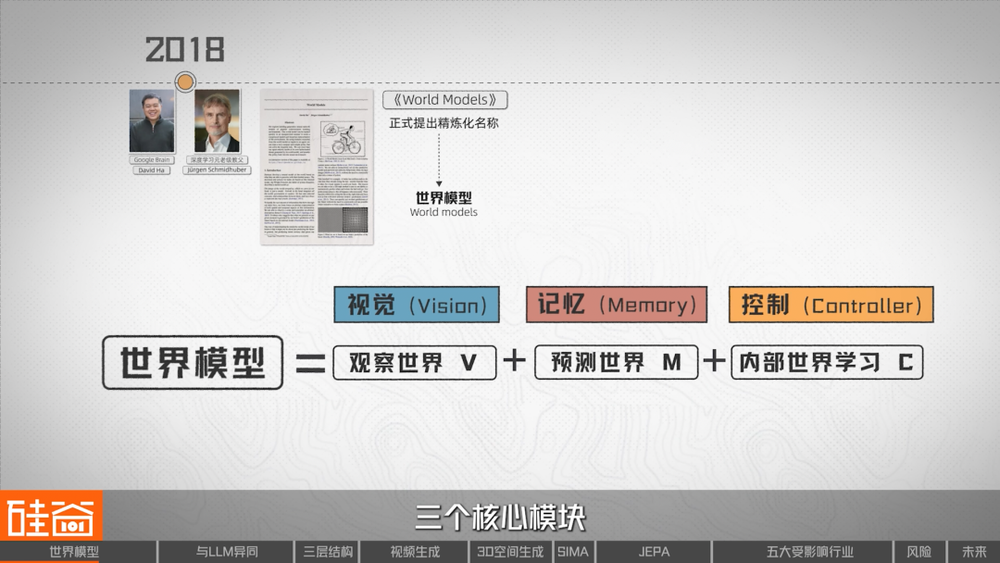
在此後在很長一段時間裏,世界模型更多停留在偏理論、偏算法的層面,直到深度學習和表示學習逐漸成熟。2018年,Google Brain的David Ha與深度學習元老級教父Jürgen Schmidhuber共同發表了論文《World Models》。這篇論文正式提出了「世界模型」(World models)這個精煉化的名稱,同時還給出了一個比較簡潔的世界模型理解框架:
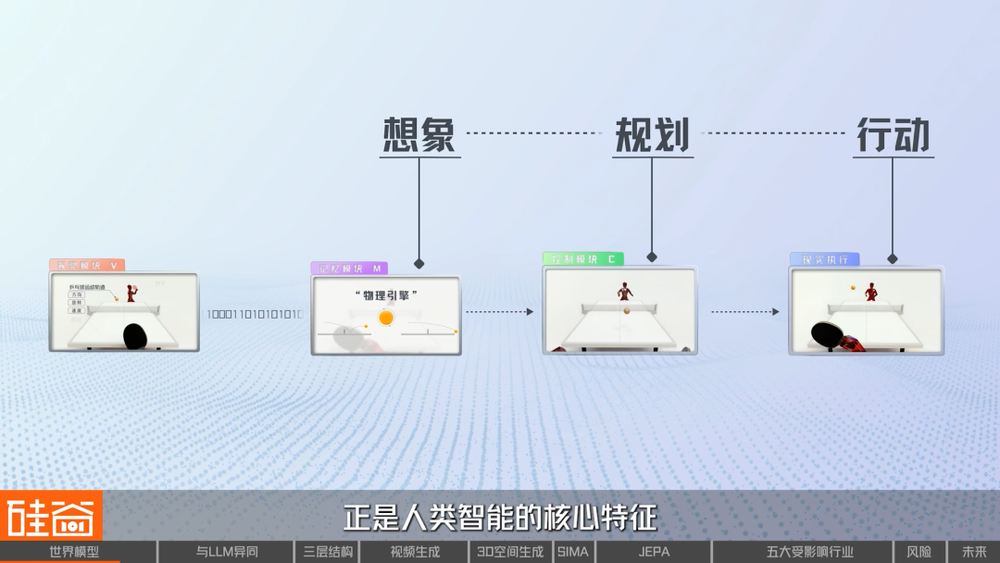
世界模型=觀察世界(V)+預測世界(M)+在內部世界中學習行動(C),對應的是視覺(Vision)、記憶(Memory)和控制(Controller)三個核心模塊。
我們用一個簡單的例子來解釋一下:想象你是一個從未打過乒乓球的新手,當你站在球台前,眼睛接收到的是大量複雜的視覺信息。視覺模塊(V)並不會記住每一個像素,而是會自動提取出對決策真正重要的部分,它將原本上百萬像素的畫面壓縮成僅有幾十個數字的精華編碼。
記憶模塊(M)接收到這些編碼後,便立即開始內部模擬。經過多次練習,你的大腦已經建立起對乒乓球運動規律的理解。記憶模塊就像你內心的「物理引擎」,能預測「如果我這樣做,會發生什麼」。
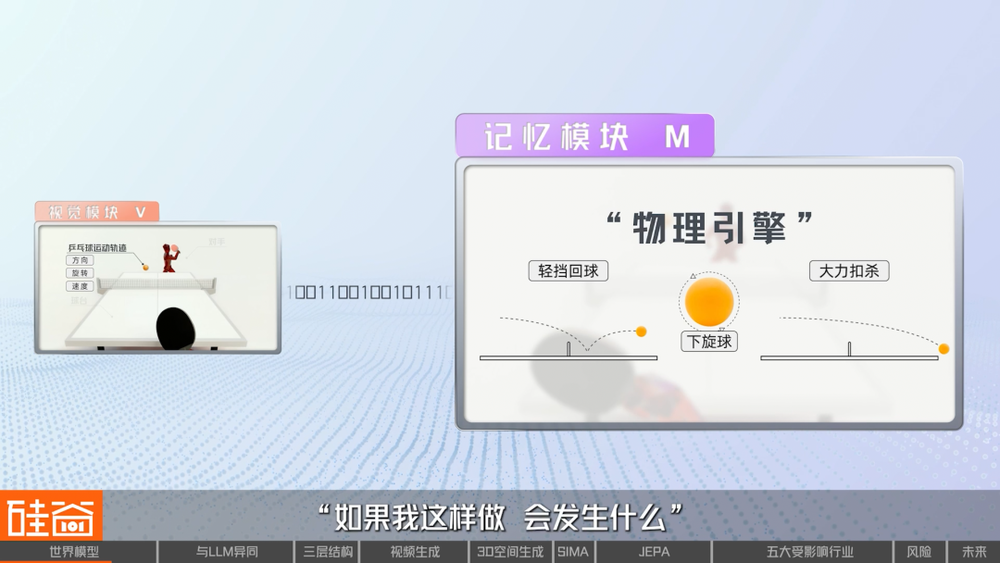
所以,當球飛來時,視覺模塊提取特徵,記憶模塊模擬方案,而控制模塊(C)就主要是在記憶模塊(M)所創造的「內部世界」中進行訓練,你並不需要真的揮拍一百次試錯,而是在記憶模塊的「夢境」中找到最佳策略後,再在現實中只執行一次最優解。而這種「想象-規劃-行動」的認知過程,正是人類智能的核心特徵。
在這篇論文中,他們也做出了一個有意思的demo,讓模型在完全虛擬的小世界裏學會了玩一款賽車遊戲,證明了AI可以像人類一樣,通過內部世界的想象來進行學習。
總結下來,研究者們普遍認為世界模型應該具有三大特質:
第一,表示世界(Representation)。模型能夠理解所處的環境裏有什麼、物體在哪裏,以及物與物之間是什麼關係。
第二,預測未來(Prediction)。它能夠對事件進行模擬和生成,如果我推一下杯子、打開一扇門、往前走兩步,世界會發生什麼樣的改變。
第三,在世界裏規劃和行動(Planning & Control)。當能預測接下來會發生什麼之後,我應該如何採取行動。

Yiqi Zhao(Product Design Lead, Meta);
它是把世界抽象到一個潛在的、被壓縮過的空間裏,在這個潛在空間裏,你能夠通過學到的物理規律,去做對未來的預測,形成一個對真實世界的模擬器。相當於它是一個模擬系統,有點像是一個縮小的平行宇宙。這感覺就像如果你有一個真正的AI大腦,它就擁有自己的AI世界觀。因為可以做預測,所以就可以去做未來的推演,就可以做決策。
世界模型的本質,就是想讓AI從一個「只會回答問題」的語言機器,走向能夠真正像人類一樣「會觀察、會推理、會行動」的真正智能體。但是問題來了,作為一個上個世紀就開始被研究的概念,為什麼突然在最近一段時間火了起來?它跟我們現在所熟悉的大語言模型又有什麼區別或是聯繫呢?
二、為什麼要研究世界模型?
世界模型與大語言模型的不同
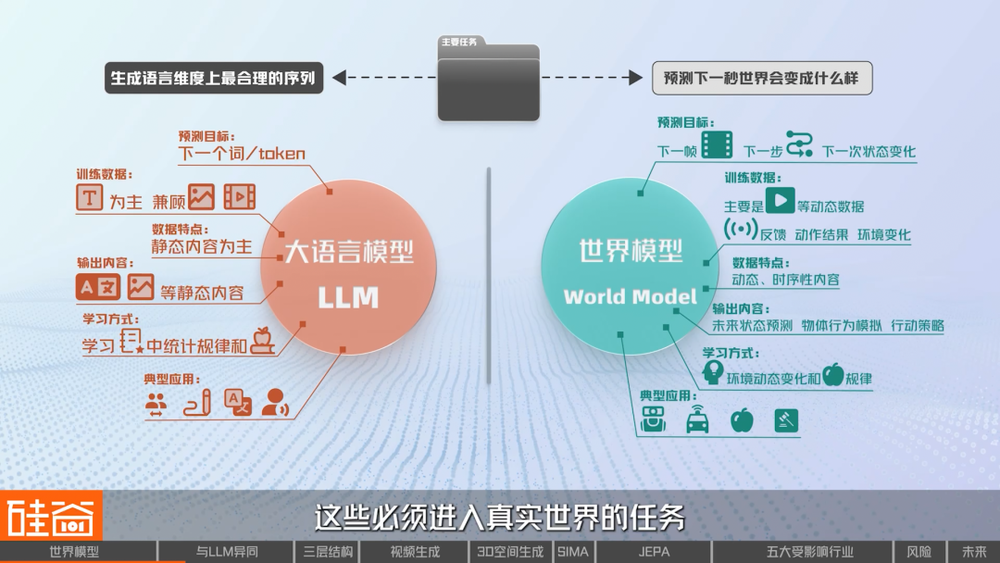
從主要任務和預測目標來看:
大語言模型的目標是生成在語言維度上最合理的序列,預測的是下一個詞或token。比如你問「杯子會從桌子上掉下來嗎?」,它回答「會」,因為這是在無數文本里出現過的正確答案。
世界模型的任務是預測「下一秒世界會變成什麼樣」,預測的是下一幀畫面、下一步動作、下一次狀態變化,它需要理解物理規律、空間關係和動態變化。
從訓練數據來看:
大語言模型主要依賴文本數據,也包括一些圖像和視頻,數據特點是以靜態內容為主。
世界模型則主要依賴視頻等動態數據,包括攝像頭看到的畫面、機器人的傳感器反饋、動作的結果、環境的變化,數據特點是動態的、時序性的。
從輸出結果看:
大語言模型輸出的是語言或圖像等內容。
世界模型輸出的是對未來狀態的預測、對行為的模擬,以及可執行的行動方案。
從學習方式看:
大語言模型是通過語言間接理解世界,更像一個「知識容器」。
世界模型是通過交互和推演直接理解世界,不僅能「看見」,還能「預測」和「干預」。
因此,大語言模型更適合對話、寫作、翻譯、問答。而世界模型更適合機器人、自動駕駛、物理模擬和決策系統這些必須進入真實世界的任務。
此前,李飛飛也曾在採訪中精煉總結過兩者在目的和訓練模態上的不同:
李飛飛(World Labs創始人、資深AI科學家):
一種是關於表達,另一種是關於觀察和行動。因此它們本質上是截然不同的模態。大型語言模型的基本單元是詞庫,無論是字母還是單詞,而我們使用的世界模型的基本單元是像素或體素。
大語言模型路線遇到瓶頸了嗎?
雖然大語言模型和世界模型是兩條不一樣的技術路線,但它們的終極目標都是要實現通用人工智能。那麼現在為什麼要突然非常關注世界模型呢?是因為大語言模型這條路已經走不動了嗎?
關於這個問題,研究界目前仍然存在着不同的觀點。
一些研究者們旗幟鮮明地提出,大語言模型是死路,這一派的代表人物之一就是Yann LeCun。
離開工作了12年的Meta後,這位65歲的圖靈獎得主、深度學習先驅並沒有選擇退休,而是回到巴黎創立了一家名為Advanced Machine Intelligence的公司。他要做的事情,與硅谷主流的大模型路線截然不同。
他在最近的採訪中表示,AI領域的Moravec悖論一直存在。所謂Moravec悖論,是指AI可以輕鬆處理對人類極其困難的高智力任務,比如下棋、微積分、讀論文。但直覺性的感知、社交等人類和動物輕鬆完成的初級技能,對機器卻極其困難。Yann LeCun認為,這個悖論至今未解決,就是因為我們研究AI的路線錯了。
人類智能的核心在於不依賴海量數據就能自主學習,但現在的LLM是在擬合語言的統計相關性,對現實世界幾乎沒有直接建模能力,如果繼續沿着LLM路線「堆量」,最多隻能做出一個更會說話、更會寫字的模型。

他甚至放言稱,再過5年,GPT之類的大語言模型就不會有人再用了。而關於大家都在憧憬AGI很快到來,他也認為是一種幻想,最樂觀也要5到10年,機器的智能才能勉強接近一隻狗。
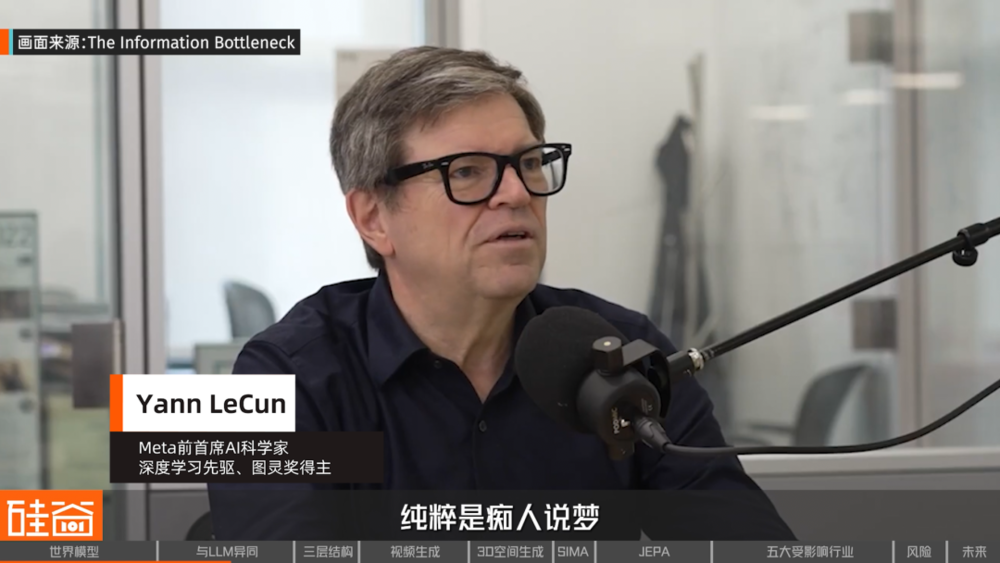
Yann LeCun(Meta前首席AI科學家、深度學習先驅、圖靈獎得主):
那些吹噓一兩年內就能實現通用人工智能的人,純粹是癡人說夢,徹頭徹尾的妄想,因為現實世界遠比這複雜得多。你不可能通過「將世界token化」和使用大語言模型來解決這個問題,這根本不可能實現。
而除了Yann LeCun之外,學術界中有不少的大佬級人物也都持有類似的觀點,比如圖靈獎獲得者、強化學習之父Richard Sutton。
Richard Sutton(強化學習之父、圖靈獎得主):
大語言模型試圖在沒有目標、也沒有‘好壞優劣’這種評價標準的情況下運作,這其實一開始就走錯了方向。
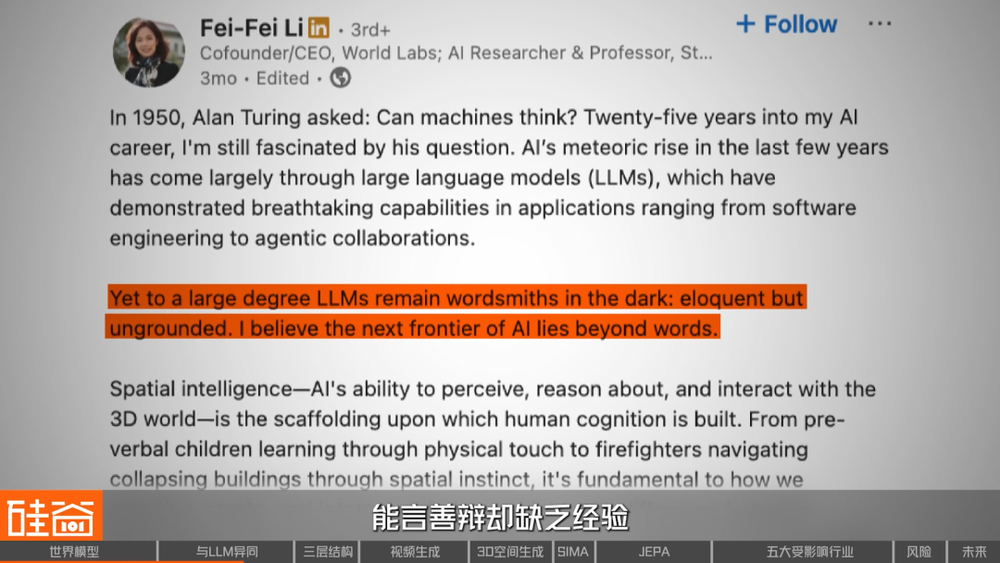
李飛飛最近也在密集地發聲,她說大語言模型仍然是黑暗中的文字匠人:能言善辯,卻缺乏經驗;知識淵博,卻脫離現實。
所以,大語言模型這條路線是不是真的走不通了呢?嚴格來說,現在還沒有標準答案,但有幾件事,大家開始有了越來越多的共識:
首先,單純把模型做得更大,已經不會再像過去那樣帶來立竿見影的突破。規模繼續上去當然可以變強,但在算力、數據、能源、成本這些硬約束下,它的性價比正在迅速下降。
其次,AI需要更直接地接觸「真實世界」。語言世界太乾淨了,它無法提供現實世界裏那種混亂、連續、充滿不確定性的因果經驗。AI想繼續往前走,需要新的輸入方式、需要多模態感知、需要和環境互動。
最後,大家普遍認為世界模型和大模型將會是一個互補的關係。陳羽北就在訪談中提到,世界模型並不是要完全將大語言模型推翻重來,而是為大語言模型補上「現實世界」的維度。

陳羽北(加州大學戴維斯分校電子與計算機工程系助理教授):
在語言中我們有了GPT的話,當預訓練的好處達到一定程度的時候,它可以被快速地變成任何的下游應用。世界模型可以被認為是一個大號的GPT,它包含了感知和控制。如果我們在這裏也能獲得根本上的成功,未來我們所有的機器人、所有的智能體都可以用這樣預訓練和後訓練的方式產生,這有可能會徹底地解鎖一些AI的應用場景。
為什麼是現在?
既然世界模型如此重要,為什麼最近一段時間它才突然被行業普遍討論和關注呢?
第一個原因就是上文我們所討論的,大模型的原生能力遇到了天花板,但人們對AI在現實生活中的期待卻越來越高。
另一個原因是,隨着多模態時代的到來,讓我們第一次有能力訓練「真正的世界模型」。訓練世界模型需要海量的視覺與動作數據、多模態傳感器輸入、大規模視頻模型能力以及足夠強的算力來支持「世界推演」,這些條件直到最近幾年才逐步成熟。

總得來說,因為大模型的天花板已經顯現,而且全行業都在邁向具身智能,再加上我們現在有了讓AI看世界、理解世界的技術基礎,世界模型就順理成章地成為了下一輪AI競賽的核心舞台。而這些嘗試,很快在行業裏分成了幾條不同的技術流派。
三、當前推進世界模型的主要路線
雖然世界模型的最終目標看起來是相對清晰的,但落實在實踐探索層面,卻常常會讓人感到困惑。比如有的在做視頻生成,有的在做3D場景,有的在做機器人,有的在做智能體,它們都叫做世界模型,但在做的事情似乎完全不同。
我們究竟應該怎麼去理解,現在整個行業到底在做些什麼?
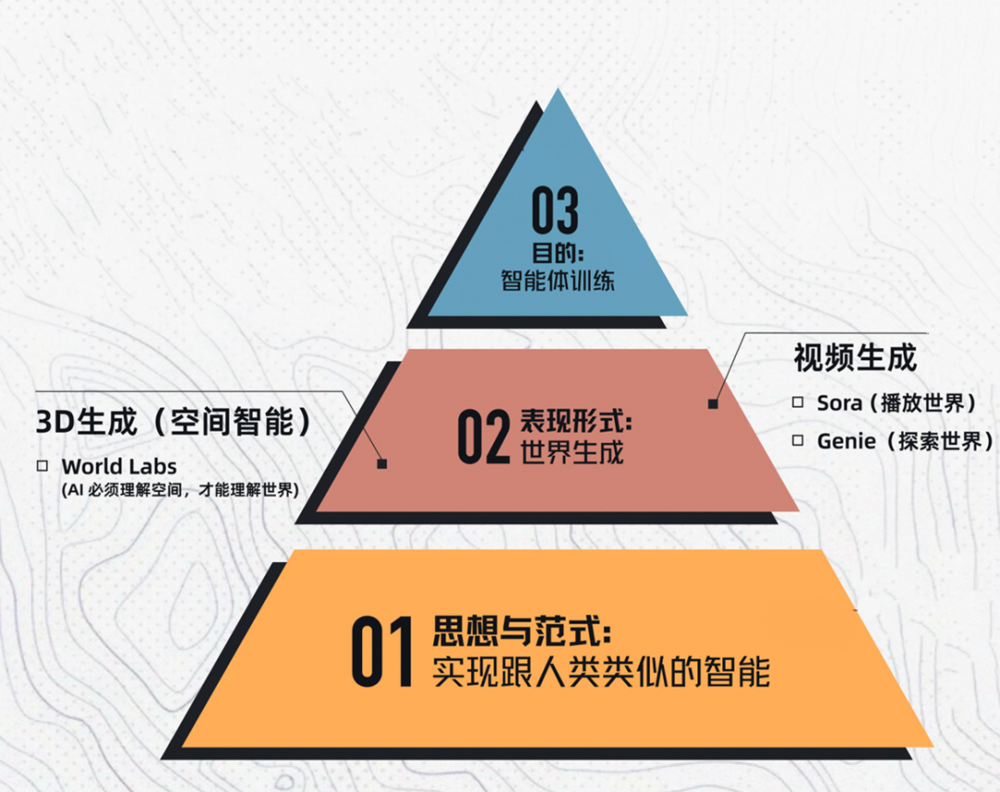
關於這個問題,我們的嘉賓Yiqi結合世界模型的理論知識以及她在Meta的一些實踐觀察,在採訪中提出了一個我們認為非常有幫助於大家理解的框架,就是把整個世界模型領域拆解成「三層結構」,在這個架構中:
底層,是世界模型的思想與範式。也就是我們之前所討論的,世界模型的抽象、預測、規劃特徵,以及它要解決的問題。這一層涉及到目前很多研究層面的創新。
第二層,是世界模型的當前的「表現形式」。指模型到底是用什麼方式來表示世界和預測世界,世界應該如何被生成出來。
第三層,是世界模型的「目的層」,也就是智能體訓練,讓AI最終能在這個世界裏行動、做任務、完成決策。

Yiqi Zhao(Product Design Lead, Meta):
Latent MDP(潛在狀態表示)+Learn Dynamics(環境動力學模型)+Simulator(內部模擬能力),這三者結合起來就是底層的世界模型核心層級,但是它是抽象的、不可見的。
如果要讓人和AI看到,需要有一個表現形式,這個表現形式需要AI幫忙生成,所以生成的層級會比它之前的層級稍微高一點。
等生成完了之後,AI大腦裏有了世界觀,就可以看到這個世界了。那接下來這個世界裏需要有東西,讓人和AI智能體都要活在裏面。
所以智能體在裏面存在的方式就是:我終於有一個宇宙了,我要在裏面玩、學習,要對這個世界造成影響,和這個世界有一個交互,互相產生影響。
四、世界模型的表現形式:世界生成
如果我們把當前產業界的主要嘗試放在這個框架中去看的話,它們其實很多都聚焦在第二層級:世界生成。這也是目前整個領域最熱鬧的地方。
為什麼要先做世界生成
很多研究者認為,構建世界模型的第一步不是讓AI直接「推理」或「行動」,而是讓它能夠去「生成世界」,這看似簡單,卻是世界模型的根基。
所謂「理解世界」,本質是理解世界如何隨時間和行為變化。物體如何移動、光線如何變化、風吹過樹葉會發生什麼,要獲得這種對「世界演化」的直覺,最直接的方式就是讓模型先能夠生成一個可連續變化的世界。
此外,強大的世界生成模型能為智能體提供廉價的訓練場。比如訓練一個機器人倒咖啡,讓它在現實中倒幾萬次、打碎幾千個杯子顯然性價比太低,而地震、火災、車禍這些邊緣場景也可以在虛擬世界中自由進行反事實推理的實踐。
因此,世界生成既是世界模型的外殼,也是整個體系的入口。而在世界生成這件事情上,目前主要有兩大技術路線:
第一類,用「視頻生成」的方式去重建世界,包括OpenAI Sora、谷歌的Genie等。
第二類,用「3D空間生成」的方式去顯式建模世界,其中的代表是李飛飛的World Labs。
視頻生成路線
視頻生成應該是目前最具代表性的、也是最為大衆所熟悉的世界模型路線。它的目標很直觀,就是嘗試讓AI直接生成一個「能動起來的世界」,並讓這個世界隨着時間流動、演化、變化。
OpenAI在發布Sora之初,它們就將其定義為一個「世界模擬器」。Sora並不是簡單地把一段視頻用靜態圖像一張張「拼出來」,而是讓畫面裏的事物能夠隨着時間連續地演化。這些視頻細節之所以令人震撼,是因為人們發現,模型似乎開始真的「理解」了事物變化的背後規律,它知道光線在材質上如何變化,知道一個物體在受到外力後該怎樣移動。而目前與Sora類似的,還有Seedance、Veo、Kling等一系列視頻生成模型。
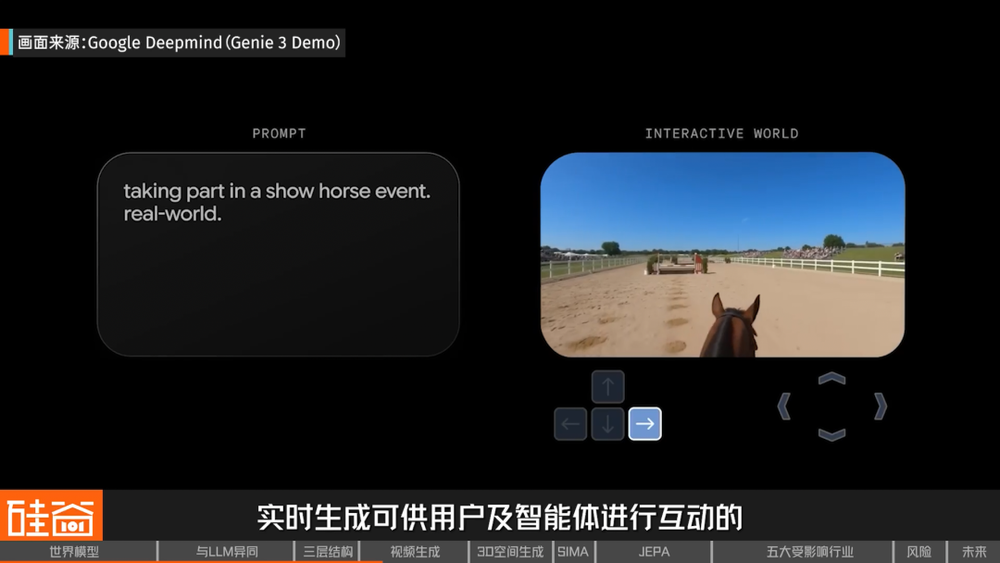
如果說Sora等模型是能夠去「播放一個世界」,Google的Genie系列模型則是讓我們能去「探索一個世界」。在Genie 3中,模型能夠根據用戶的文本或圖像提示,實時生成可供用戶及智能體進行互動的虛擬環境。相比前代產品,Genie 3的核心突破在於「實時交互性」和「長時間一致性」,用戶可以跟模型進行長達數分鐘的互動。
Yiqi Zhao(Product Design Lead, Meta):
Genie 3跟傳統的視頻生成模型很不同的一點在於,它生成出來的內容,你是可以跟它實時交互的。你生成出來的內容,比如黑板上寫了字,我走到別的地方回來之後這個字它還在黑板上。說明它雖然還是有frame by frame(逐幀生成)的生成方式,但是它已經能夠記住世界裏面的這些狀態。
Genie 3的這種可控性,意味着模型內部不再只是預測下一幀是什麼,而是已經在模擬「未來的世界狀態」。它讓視頻生成從「播放」走向「交互」,開始從「電影式生成」走向「遊戲式模擬」,更接近一個真正的「世界引擎」,也更接近智能體將來需要使用的環境。

就在今年1月,谷歌還推出了基於Genie 3打造的實驗室原型Project Genie,首次將Genie 3的能力第一次封裝成為了一個「人人都可以直接上手體驗」的產品形態。它的強大在於多模態的深度協同:由Gemini提供邏輯支撐,Nano Banana Pro生成高精度的場景與角色,再由核心引擎Genie 3將靜態設計「激活」為可互動的3D世界。依託TPU v5的算力,Project Genie實現了720p/24fps的實時環境渲染,同時允許用戶對同一個世界進行「重新混剪」,具有長達60秒的強一致性記憶。
Project Genie的發布意味着「世界模型」或許開始真正從PPT走進現實,它不再只是個會「變魔術」的算法,而是通過一句話就能「變」出一個可運行的小型遊戲世界的生產力工具。
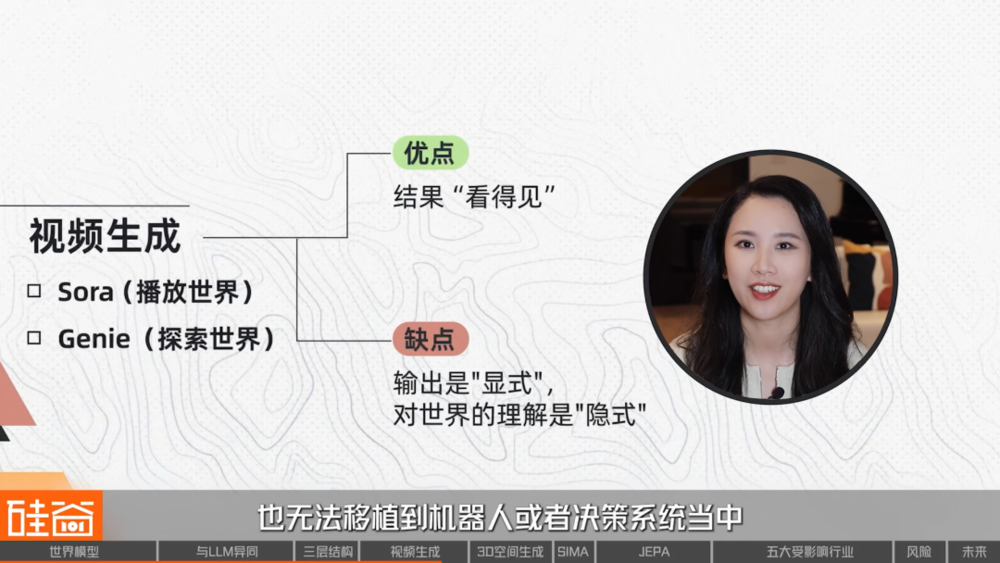
從行業視角來看,視頻生成路線有一個非常明顯的優勢就是它的結果「看得見」。我們能直接觀察世界模型是否具備物理一致性、是否理解時空結構,而且它能快速商業化落地,影視、廣告、教育、遊戲都能立刻使用。
從技術角度看,視頻生成的優點也很突出:首先,訓練數據相對容易獲得。互聯網上有大量真實世界視頻,為模型學習世界規律提供了訓練空間。其次,它對Scaling Law非常敏感,模型規模越大、數據越多,視頻的一致性和物理合理性就呈指數級提升。此外,視頻數據天然包含多樣化場景,模型泛化能力也更強。
正因為這種「可觀察性」和「可規模化訓練」的組合,讓視頻生成路線在過去一、兩年成為世界模型最引人注目的方向。
但視頻生成的侷限也同樣明顯,最重要的一點是,雖然它的輸出是「顯式」的,但內部對世界的理解是「隱式」的,我們無法直接讀取,也無法將能力直接移植到機器人或決策系統中。

視頻生成路線其實和大語言模型很像,兩者都是典型「scale-driven(規模驅動)模型」。語言模型通過學習互聯網文本掌握語言統計規律,視頻模型通過學習海量視頻掌握視覺統計規律,區別在於:視頻數據天然包含物體運動、加速度、重力等物理特徵,因此視頻模型能更直接地看到真實世界的運作方式。
但和語言模型一樣,視頻模型理解的世界規律依然「藏在權重裏」。語言模型預測下一個token,視頻模型預測下一幀,但都很難告訴你世界內部的結構是什麼。比如你讓Sora生成一輛車的行駛視頻,造型和光影可能很逼真,但如果你問,這輛車的長寬高是多少?被擋住的輪胎在哪裏?它答不上來。因為Sora並沒有構建一個3D的幾何車輛模型,它只是學到了像素組合的概率分佈。
3D生成(空間智能)路線
所以視頻生成雖然是目前最直觀、最能應用落地的一步,但它目前也只是畫出了世界的一層皮,但還缺少有血有肉的框架。那如何才能勾勒出世界表層下的框架呢?
李飛飛提出的思路是:3D生成,也就是空間智能。
與視頻生成相比,3D生成路線走的是一條截然不同的技術選擇,不是把世界畫出來,而是把世界建出來。這也是李飛飛領導創建的World Labs目前的技術路線。它們不追求畫面有多逼真或「電影級」連續性,而是更關注世界的結構,包括物體在哪裏?空間的幾何關係是什麼?物體之間如何相互影響?生成的世界是否能被「進入」與「操作」?

WorldLabs最新發布的模型叫Marble,它的特點是給它一個語言指令、一張照片或視頻,就能通過高斯潑濺技術重建出完整的3D場景結構。簡單來說,Marble就像建築師,看到圖片時不只看到「像素」,而是看到背後的三維結構。比如你同樣問它圖片裏汽車的長寬高,它能回答出是長4.5米、寬1.8米,還能輸出3D網格文件。
為什麼李飛飛如此強調3D呢?因為她認為真正的世界就不是2D的,而是3D的,AI必須理解空間,才能理解世界。人類能抓住物體、避開障礙、記住空間,是因為我們天生具備構建3D模型的能力。機器人要抓取物體需要知道形狀、體積、位置,自動駕駛要理解空間和距離,這些都不是二維像素能表達的。AI要真正進入現實世界,首先要知道「世界的三維結構」。
從技術層面看,3D生成路線有個巨大優勢:與視頻模型的「隱式物理直覺」不同,它生成的是顯式結構,模型知道每個物體的具體位置,因此物理模擬、規劃、控制都更容易實現。一旦掌握這些顯式信息,它就能繼承傳統物理引擎的優勢,確保碰撞、遮擋、施力等表現嚴格正確,成為「可操作世界模型」的底座。
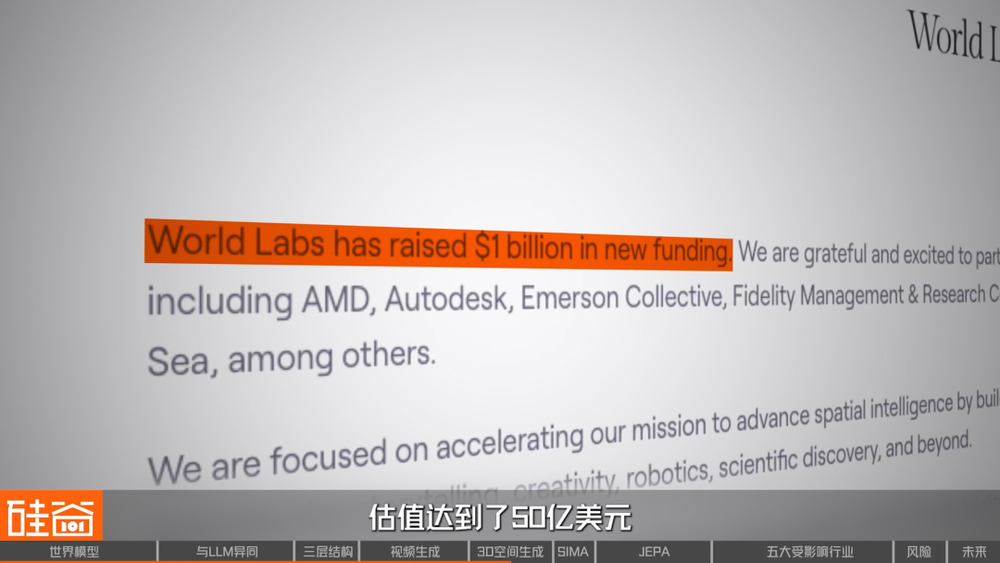
此外,3D生成在遊戲、影視製作、室內設計等場景也能快速落地,讓它能夠在商業轉化上具有優勢。不久前,Worldlabs宣佈了最新一輪10億美元的孖展,估值達到了50億美元,短短一年半時間,它的估值飆升了5倍之多,一定程度上也反映了市場對於「3D生成」這條路線潛力的認可。
雖然3D生成對世界模型的發展具有巨大的戰略意義,但它的實現難度也要比視頻生成大很多:
首先是訓練數據稀缺。互聯網是巨大的2D視頻礦山,但3D數據卻很少。高質量3D數據主要靠LiDAR、結構光掃描儀等專業設備採集,不僅設備貴,流程還繁瑣,標註成本也比2D高出一個量級。
其次是幾何結構難建。3D模型需要確保生成的物體封閉、無穿模、無破損,而預測柔體、流體、鏈式碰撞等複雜3D動態交互則難度更大。
最後是對算力需求很大。無論是訓練中的3D渲染還是實時物理模擬,計算量都遠超2D模型,直接推高了研究門檻。

胡淵鳴(Meshy AI CEO):
我們如果要生成一張1024x1024分辨率的圖片,大約一百萬個像素。但是如果要生成一個3D的模型,最大的挑戰就是多出來一個新的維度,就不太可能直接用1024x1024x1024分辨率這樣的表示方式去做,計算量實在是太大了,所以大家就發明了很多新的創造性方法:
比如Meshy用的技術路線,是基於擴散模型或者自迴歸模型,通常先生成一個低分辨率版本的模型,然後再去把它Upscale(上採樣)。在Upscale(上採樣)的過程中,就會發現有一些區域不屬於我們關心的範圍,所以在這種情況下,我們就可以把計算量集中在我們特別關心的區域。
總結來說,3D生成路線能夠更加真實地去還原世界,但它實現難度更大、成本更高。
不過我們以上討論的其實都是如何把世界生成出來,但光有生成,還遠遠不夠,因為世界模型的真正的目標不是去生成一個世界,而是要讓AI在這個世界裏行動。
五、世界模型的目的:智能體訓練
如果「世界生成」是為了讓AI看見世界、重建世界,「智能體訓練」就是要讓AI能在這個世界裏「做事」,從「世界長什麼樣」走向「我能在這個世界裏做什麼」。目前,業界主要有兩種探索路線。
基於虛擬世界訓練路線:SIMA
第一條路線,就是直接把世界生成模型當成「訓練環境」,讓AI在虛擬生成的世界裏不斷去犯錯、探索、總結,最終學會一套可以遷移到真實世界的能力,這一類的代表是Google SIMA。
SIMA的思路非常直接:既然現實世界太複雜、真實的訓練太昂貴,那我們就用虛擬世界來教AI如何行動,而遊戲就成為了它最佳的訓練場。視頻遊戲作為複雜、可交互、實時反饋的環境,一直是AI發展的搖籃,從早期的Atari到AlphaStar在《星際爭霸II》中打到世界前0.2%,DeepMind一直用遊戲訓練更智能的AI。

而SIMA的訓練方式就是把AI放進很多不同類型的遊戲環境裏去「練級」。最新的SIMA 2還將Gemini嵌入內核,並首次使用Genie 3生成的遊戲世界進行了訓練。
SIMA 2展現出幾個令人矚目的能力突破:
首先,它不僅能「跟指令做事」,還能「自己思考」。它可以理解複雜、多步、抽象的任務,在陌生環境中自主探索、規劃行動、尋找解決方案。
其次,它具有強大的「泛化能力」,能在從未見過的遊戲環境中表現出色。比如在Genie實時生成的世界中仍能合理辨別方向、理解指令、採取有意義的行動。此外,SIMA 2被設計為能跨遊戲、跨環境執行任務的通用AI智能體,這也為將來的具身機器人遷移奠定了基礎。

SIMA想做的事情,顯然比「玩遊戲」本身更大。遊戲只是現實世界的縮影,它最終想要實現的,是讓AI能在任何3D世界裏行動、探索、推理、解決問題。然而對於這個目標,不是所有研究者都認為「要行動,就必須先生成一個世界」。以Yann LeCun代表的另一派,就選擇了一條完全不同的路線。
直接學習世界的抽象結構:JEPA
Yann LeCun實現世界模型的思路是:不用去把世界「畫」出來,而是讓AI直接去學習世界的抽象結構。
在他看來,不管是生成圖片、生成視頻,還是生成3D世界,生成式模型都有一個共同的問題:消耗了大量算力去「畫細節」,卻未必真正理解了世界的結構。比如人類學習走路時,我們只需要知道:地面在哪裏,障礙物在哪裏,下一步該往哪走。

理解世界的結構,比生成世界的外觀更重要。這正是Yann LeCun所提出的JEPA(Joint Embedding Predictive Architecture,聯合嵌入預測架構)理論的核心思想。JEPA不預測圖像、不預測像素,也不重建視覺內容,它做的事情是把真實世界壓縮成一個抽象的、高維的潛在表示,然後在這個潛在空間裏進行預測。預測的目標可以是空間上被遮擋的區域,也可以是時間上的後續狀態。
我們來舉個簡單的例子:如果你輕輕推一個球,視頻模型要預測的是下一幀裏球的位置、陰影、光照、材質反射。但JEPA不關心這些,它只關心球會往哪個方向滾,速度會怎麼變,會不會撞到障礙物,哪些變化與任務和決策相關。它學習的是未來的結構,而不是未來的畫面。
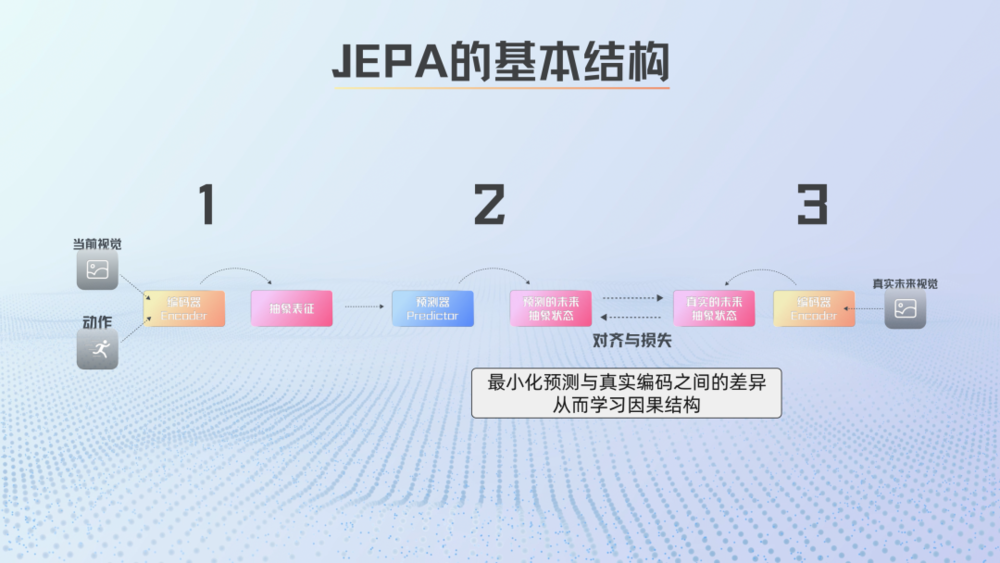
JEPA的基本結構可以拆成三件事:首先,用Encoder(編碼器)將視覺和動作壓縮成抽象表徵,然後用Predictor(預測器)預測這些抽象狀態在未來如何變化,最後將預測結果與真實未來狀態的編碼進行對齊,讓模型學會捕捉世界的關鍵因果結構。
基於JEPA架構,Yann LeCun在Meta也先後發布了I-JEPA和V-JEPA,前者讓AI理解靜態圖像的結構,後者則讓AI學習視頻中世界隨時間變化的規律。
JEPA的路線背後,有非常重要的技術動機:
首先,生成像素既昂貴又低效,而絕大多數像素信息與行動決策無關。JEPA不「畫世界」,因此計算成本更低。
其次,由於只保留關鍵結構信息,JEPA更容易捕捉因果關係,也更具跨場景、跨任務的泛化能力。
更重要的是,這種抽象、結構化的世界表示,更接近機器人和具身智能真正需要的「可操作世界」。比如對於機器人來說,它不需要知道物體的光影紋理,它只需要知道物體的可達性、跟自己的位置關係以及下一步該做什麼,而JEPA的輸出的就是這種結構化的抽象信息。
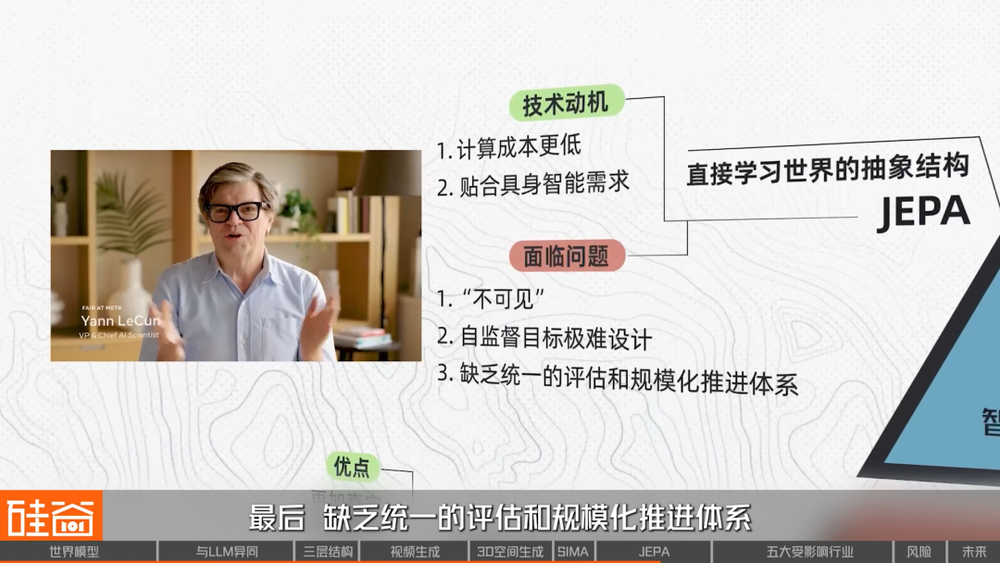
早在幾年前,Yann LeCun就已經在為JEPA路線搖旗吶喊了,但它至今仍然未能成為世界模型的研究的主流,因為JEPA路線在實際推進中面臨了很多現實問題:
首先,它是「不可見的」。Sora能用逼真的畫面震撼所有人,Genie可以生成可探索的遊戲世界,WorldLabs能用3D場景告訴你「我理解了空間結構」。但JEPA學到的所有東西,都藏在一個抽象的潛在空間裏,這意味着我們難以直接看到和驗證模型到底「理解了什麼」。
其次,它的自監督目標極難設計。JEPA不像視頻生成那樣有現成的目標,你給它一幀讓它預測下一幀,JEPA想預測的是「未來的結構」。但什麼纔是「結構」?哪些因素該保留、哪些該忽略?目前仍沒有統一答案。
最後,缺乏統一的評估和規模化推進體系。JEPA的表徵質量藏在潛在空間裏,研究社區多依賴下游任務或行為表現來評估模型,缺乏類似圖像生成或語言模型那樣統一的benchmark(基準指標),這也使不同設計路線之間的效果比較變得更加困難。正因為這些限制,JEPA更像一個「世界模型的前額葉原型」,方向很可能是對的,但距離成熟落地還仍然有一段距離。
到這裏,我們把世界模型最核心的幾條技術路線都梳理了一遍:有人用視頻把世界「畫」出來;有人用 3D 把世界「搭」出來;有人在虛擬世界裏訓練行動智能;也有人乾脆不畫世界,想讓AI直接學習世界的結構。
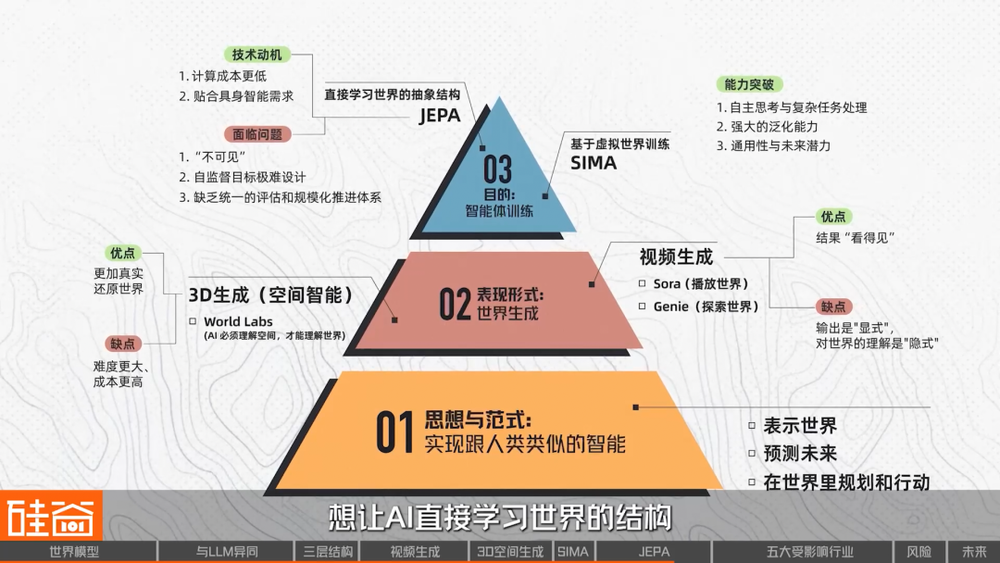
當然,還有一些我們沒有展開的路線:比如Dreamer這一類以動力學為核心的世界模型更專注於控制與想象;有的試圖從物理規律出發,用可微分模擬器去逼近真實世界;也有越來越多工作,正在模糊世界模型、預測模型與決策模型之間的邊界。
這些路線看起來方向不同,但它們正在指向同一個未來:讓AI不再只是「輸出信息」,而是真正理解世界、推理世界、在世界裏行動。
Yiqi表示,因為目前世界模型在落地層面還在早期階段,並沒有看到哪一條路線具體的商業應用形式,所以包括Meta在內的大廠們,實際是在各個路線上都在做佈局和研究。

Yiqi Zhao(Product Design Lead, Meta):
Meta在世界模型的路線上,不同的技術路線全部都做了,主要是因為它的用戶場景和垂直場景的需求不同。所以為遊戲服務的我們就做了AI遊戲引擎,叫做Meta Horizon Studio。為內容創作來服務,我們就做了純視頻方向的。為了數字重建和3D重建,我們就做了高斯潑濺的方式。所以我們希望能夠把方方面面的需求都概括進去,各種場景都適用,我相信其他公司也是這樣想的。
不過可以預見的是,當世界模型真正成熟,對產業帶來的改變,絕對不會只是讓「視頻生產效率更高」這麼簡單,它將是一次橫跨軟件、硬件、製造、娛樂等衆多行業的系統性衝擊。
六、世界模型會改寫哪些關鍵行業?
機器人
如果說有哪個行業,會最直接地被世界模型撬動,那一定是機器人行業。
過去幾十年,機器人的發展受制於硬件、算力和應用場景等多重因素。但更深層、也更關鍵的瓶頸在於它們還不「懂」世界,因此難以實現跨環境的遷移和泛化。今天的絕大多數機器人看起來很厲害,但它們做的一切,本質上都是「被編程好的動作」,所以只要環境稍微變化,它們就會立刻「失能」。
機器人行業過去一直難以擴張的原因就在於:每一項新任務,都意味着一次新的工程項目。
而世界模型帶來的,是讓機器人擁有「世界的內部模型」。它能看到現在,也能預測未來,知道物體怎麼動,也能推斷自己的動作會產生什麼後果。它能先在腦子裏模擬,再決定要不要執行。

比如它可以模擬箱子會不會翻倒、門把的角度能否順利轉動、路徑是否足夠安全、抓取是否會失敗。過去要花工程師幾十小時調參的任務,現在機器人在模擬世界裏自主練習就能掌握。
更重要的是,機器人開始具備遷移能力。它不需要每次換一個物體、換一個場景、換一個任務都重新示教一遍,它能把內部模型裏學到的規律遷移到現實世界。儘管仿真到現實的遷移至今仍是一個開放難題,世界模型有望大幅降低這道門檻,讓機器人面對從未見過的物品時,仍然能做出合理決策。
這對機器人來說是一次範式級的改變。無論是家庭服務機器人、倉儲機器人、工廠協作機器人、餐飲零售機器人,還是專業級的巡檢、建築、醫療輔助手臂,世界模型都可能成為它們跨過智能門檻的那把鑰匙。
自動駕駛
大約從5年前開始,馬斯克就開始講L5要來了,但為什麼時至今天,L5級的自動駕駛依然沒有全面普及?背後原因之一就在於:系統雖然「看得見世界」,卻還難以真正預測世界。
我們現在常說的L2、L3自動駕駛,本質上依賴的仍然是「感知—預測—規劃」的分層體系:識別車、人、車道線、交通燈,再通過規劃系統給車輛下指令。
特斯拉更強調用大規模真實道路數據,通過端到端方式不斷逼近人類駕駛。而Waymo則長期在高度結構化的系統中,追求可驗證的安全性。但無論是哪種路線,都面臨一個共同的問題:它們對「現在」的感知已經很強,卻很難穩定地理解「接下來會發生什麼」。
再加上極端天氣、突發事故、不規範行人等長尾場景在真實道路中極其稀少,也成為制約自動駕駛規模化的關鍵瓶頸。
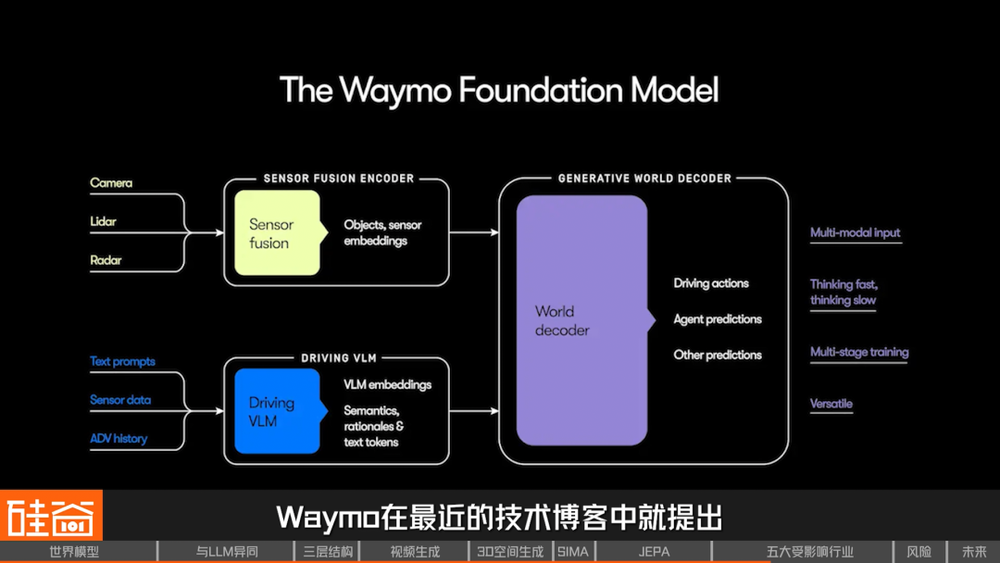
而這正是世界模型開始真正進入工程體系的地方。比如Waymo在最近的技術博客中提出,他們正在將自動駕駛系統的核心,構建為一個Foundation model(基礎模型),它採用了「分段式端到端」的架構,內部可以進行端到端訓練和反向傳播,同時又保留了對世界的結構化表達。這個模型不只是完成單一任務,而是學習「世界如何運轉」,它被要求輸出物體、語義屬性和道路結構等中間表徵,讓系統在出錯時,能夠定位問題出在世界理解的哪一層。
這些結構化世界信息,也支撐起更高質量的仿真系統:不僅還原場景,還能在不同假設下預測交通參與者的行為,並在內部同時推演大量可能的決策路徑,從中篩選出最安全、最穩定的一條。這不再只是「識別」,也不只是「反應」,而是讓自動駕駛系統開始具備一種接近人類駕駛的預判能力。
也正因為如此,世界模型被認為是推動自動駕駛從局部可用,走向可驗證、安全的大規模商業化落地的核心技術之一。
穿戴式設備
如今我們所熟知的可穿戴設備,本質上還是停留在記錄層面,看上去很智能,但實際上卻並不理解你周圍的環境。而世界模型會讓這一切發生質變:

一方面,它能讓設備真正讀懂你的3D世界,實時推斷空間結構、物體關係和潛在風險,把數字內容自然融合進現實環境。另一方面,它的預測和規劃能力,會讓可穿戴設備從工具變成你的「數字夥伴」。理解你在什麼環境、看什麼、可能要做什麼,比如提前提醒路面溼滑,在灶底1識別缺少的食材,甚至在你開口前就意識到你需要幫助。
從更長遠看,這不只是設備升級,更是一種新的「人機關係」,世界模型會讓可穿戴設備,從「信息終端」變成隨身的「世界理解引擎」,眼鏡、耳機、手錶,都可能進化為與你共同生活、共同行動的智能體。而這,也可能會是下一代計算平台的起點。
內容生成、遊戲與影視製作
如果說機器人、自動駕駛等「具身智能」是世界模型在現實世界的落地,內容相關的產業,就是世界模型在「想象世界」裏的爆發奇點。
如今我們已經看到視頻生成模型所帶來的一些震撼效果,而世界模型的到來,可以讓未來的內容創作只需要給一個世界觀、一個任務、一個初始狀態,模型就能自動「長出一個世界」。比如在影視行業,一個導演不需要去反覆搭景、重拍、做模型,只需要定義「這是一座被雨水淹沒的城市」,AI就能生成整個城市的狀態變化。
而在遊戲行業,世界模型帶來的改變更是顛覆性的。過去的遊戲世界需要一磚一瓦搭建,地形、天氣、物理引擎、NPC行為、任務鏈等等條件,我們都需要數百人團隊、花費幾年時間,才能做出一個開放世界。但世界模型意味着遊戲世界不需要「製作」,而可以自動生成和進化。一個設計師只需要設定規則、生態、衝突,AI就能生長出森林、河流、生物、文化、經濟系統,甚至NPC的性格、記憶和演化方向。

胡淵鳴(Meshy AI CEO):
大家以前玩的遊戲都是靜止的遊戲,所有的規則已經被寫好了,有一個遊戲設計師和遊戲程序員去實現這個規則就可以了。但是如果我們在遊戲場景當中有這種生成式AI技術,就可以實現遊戲是on the fly(即時)生成的。比如谷歌的Genie 3,按上下左右鍵,它可以on the fly(即時)生成下一秒的東西。
我們在做的事情就是,先用3D的模型,再自己做一個多模態的大模型,這個大模型可以先生成角色的外形,然後再給它加上人物邏輯,包括它的性格等等各種各樣的形式的邏輯。我們通過這條路徑也可以實現一個世界模型。
所以對於整個內容行業來說,世界模型帶來的不僅僅是製作效率的提升,而是一場敘事方式、創作方式、內容形式的全面重寫。
AI Agent
世界模型的到來,還會加速AI Agent的進化。當我們今天在聊AI Agent的時候,很多討論其實都集中在Agent能不能更聰明、規劃能力夠不夠強、工具調用做得好不好。但如果退一步看,會發現一個更底層的問題一直沒有被真正解決:Agent到底是在什麼環境裏學會「行動」的?
從強化學習的視角看,Agent的一切能力,都來自與環境的交互:執行動作,接收反饋。但真實世界太昂貴、太緩慢,也太危險,幾乎不可能支撐大規模試錯。
而世界模型解決的,正是「環境」本身的問題。它通過學習真實系統的數據,在模型內部構建一個可運行的世界,當Agent採取行動時,世界模型可以直接推演這個動作可能帶來的結果。這樣Agent就可以在世界模型中進行大規模訓練,如果這個世界足夠接近真實,在虛擬環境中學到的能力,就可以穩定遷移到現實系統中。

世界模型並不是讓Agent立刻變得更聰明,而是第一次為Agent提供了一個可訓練、可試錯、接近真實的「內在世界」。這層世界底座,纔是真正決定AI Agent能否走向現實世界的關鍵。
所以世界模型改變的不只是某一個行業、某一個產品、某一種形態,而是整套人與世界互動的方式。陳羽北在採訪中就談到,如果世界模型真的從根本上走通了,甚至有可能創造出一種新的文明。
陳羽北(加州大學戴維斯分校電子與計算機工程系助理教授):
如果你能實現World model(世界模型),已經包羅萬象,把這個世界所有的邏輯問題和規律都掌握了,而且不是簡單的外延,而是可以在比較根本的程度上產生泛化,產生數據、產生意識,產生到超越人類的程度。那在給予一定意識的情況下,這個模型似乎已經具備了建立一個新的文明的能力。
七、世界模型的潛在風險
當然,任何足以改變技術版圖的突破都會帶來新的風險。而世界模型的風險,不再只是「胡說八道」那麼簡單:
首先,是更隱蔽、也更危險的模型幻覺。無論哪條路線,世界模型本質上都是在給AI構建一個高度逼真的「夢境」,讓它在其中模擬和推演。但虛擬世界永遠無法完全覆蓋真實世界,始終存在Sim-to-Real Gap(虛實差異)。語言模型的幻覺是編造事實,視頻模型的幻覺是畫面錯誤。而世界模型的幻覺,出現在整個「世界結構」裏,比如誤判物體重量、高估動作可行性、低估碰撞後果,甚至構建了錯誤的因果關係。

這些問題不一定立刻被察覺,卻會直接影響智能體的決策與行動,進而導致機器人失常、自動駕駛偏離,甚至關鍵系統被系統性誤導。所以當世界模型出現幻覺,錯誤將是「系統級」的,這也是更難發現、更難對齊的風險。
其次,是世界模型帶來的權力集中問題。未來可能只有極少數機構具備構建和運行世界模型的能力,而成熟的世界模型,意味着前所未有的預測能力。對市場、社會行為、羣體反應的高精度推演,可能帶來新的信息壟斷,也可能被用於更高效的社會操控與商業操縱。
更重要的是,當世界模型越來越真實,虛擬與現實的邊界會越來越模糊,「自主智能體」的到來也加大了AI不受控的風險。

一旦AI真正理解並模擬世界,深度僞造與虛假場景將進入「超真實」階段,AR/VR世界可能與現實幾乎無差,甚至更具吸引力。與此同時,當越來越多真實系統開始依賴這些模型,現實世界本身,也可能反過來「對齊」模型的假設。而當世界模型變成決策底座,內部狀態難以審計、推理過程不可見,我們甚至很難判斷它究竟「理解」了什麼、在朝什麼方向演化,這也意味着,它所帶來的監管挑戰,將遠高於今天的大模型。
所以,世界模型潛力巨大,但帶來的風險也比我們過去面對的任何AI技術都更危險。它不只是內容層面的風險,而是會真的影響現實世界。
當AI不只是看世界、畫世界,而是開始在現實中推演、行動、做決定,我們需要從系統、對齊、倫理、監管所有層面重新討論這件事。
八、AI的下一段旅程
過去一、兩年,我們看到了AI在語言、圖像、視頻上的極速爆發,彷彿一夜之間,AI已經無所不能。但當你開始思考,AI是否真的理解世界,是否能預測未來,是否能像人類一樣在世界中行動?你會發現,現在的大模型其實還仍然停留在「表層智能」的階段。而世界模型,向我們提供了真正走向「深層智能」的可能。
它讓AI從「看到世界」走向「理解世界」,從「預測句子」走向「預測未來」,從「生成畫面」走向「在世界裏行動」。這不僅會改變機器人、製造業、自動駕駛、內容產業,也會改變我們和數字世界的關係,甚至改變我們對「智能」本身的理解。

當然,世界模型的道路還很長。它面臨巨大的技術挑戰,也伴隨新的風險。目前我們仍然不知道哪一條路線會最終勝出,但我們知道的是:當AI能夠真正理解世界、模擬世界、在世界裏試錯和行動時,它離「通用智能」,也就是我們一直在尋找的那個終極目標,又會近了一大步。而這,也許AI時代真正的拐點,而我們現在,正在見證它的開端。
最後,我們還想補充的是,因為世界模型本身還沒有一個被學界和產業完全統一的定義。所以這一期內容,並不是想給世界模型下一個「標準答案」,而是希望從我們的視角,為大家梳理出一個理解世界模型的框架。
不同團隊、不同方向的每一條路線背後,其實都牽涉到大量具體的技術細節、方法選擇,以及仍在快速演化的新嘗試。
本文來自微信公衆號:硅谷101,作者:張珺玥
本內容由作者授權發布,觀點僅代表作者本人,不代表虎嗅立場。如對本稿件有異議或投訴,請聯繫 tougao@huxiu.com。
End
想漲知識 關注虎嗅視頻號!