
如果有 5 萬塊錢的預算,用來配一台個人電腦,你會怎麼選?
放在以前,你可能會把預算的大頭放在顯卡上——畢竟無論是「玩遊戲」還是「下班玩遊戲」,有個強悍的 GPU 總歸不是一件壞事。

▲ 圖|網絡
可如今,這個問題變得複雜起來。
以往在 CPU、GPU、主板、內存、硬盤、外設之間有序分佈的預算,突然被內存這頭「吞金巨獸」打亂。
這下無論計劃用電腦做什麼,你都會碰到顧此失彼的問題——
大內存、大顯存、大硬盤每個都不能缺,但每個都會讓錢包滴血。
而在內存亂潮中異軍突起的 Mac,恰恰就是上面那個問題的最佳解決方案。
迄今最強的 AI Mac
啱啱過去的春季發布會上,蘋果如期帶來了 M5 MacBook Pro 的升級版機型,以及配套的 M5 Pro 和 M5 Max 處理器。

作為 Apple Silicon 全面更新台積電 3nm N3P 工藝的結果,兩款新處理器在規格上的確沒有讓我們失望。
其中,M5 Pro 有 15+16 和 18+20 核兩種規模,均搭載了去年 M5 上的神經網絡加速器,也就是那個「蘋果版的 Tensor Core」。
▲ 圖|Apple
M5 Max 本次則有 18+32 和 18+40 核可選,以及 16 核神經網絡加速器。僅從處理器規模上看,M5 Pro 與 M5 Max 毫無疑問都是 GPU 優先的。
這種傾向也體現在了新處理器的微架構設計上。
目前,所有 M5 系列的處理器均換裝了 LPDDR5X 9600 統一內存,根據蘋果的介紹,M5 Pro 的最大內存帶寬為 307GB/s,M5 Max 則有 614GB/s:

▲ 圖|Apple
既然 M5 Pro 和 M5 Max 標配 18 核 CPU,那麼導致內存帶寬不同的原因大概率就在 GPU 規格上。
結合發布前的預測,這種差異側面說明了 M5 系列的內存控制器很有可能是設定在 GPU 核心簇上的。
這種策略和愛範兒去年參訪英特爾工廠時看到的 Panther Lake 架構心有靈犀:

這樣做的好處很明顯——將 GPU 與內存控制器靠近,可以非常有效地緩解內存數據的核間通訊的延遲,變相提升 GPU 效率。
而速度更快、VRAM 更大的 GPU 最擅長什麼呢?當然是本地 AI 應用了。
這也是本次蘋果在官網頁面上非常高頻提及「AI」的原因之一。
就拿愛範兒這台 14 寸 MacBook Pro 樣機來說,我們收到的是今年最頂規的 40 核 GPU M5 Max 版本,搭配 128GB 統一內存和 8TB 硬盤,一台超過 5.5 萬元的性能怪獸。

一般來說,當我們用 Windows PC 跑本地模型的時候,最大的瓶頸往往不是賣出天價的「主板內存」,而是顯卡內部的 VRAM 顯存。
而蘋果統一內存的最大優勢,就在於它可以被 GPU 直接調用。
比如我們這台 128GB M5 Max 評測機,理論上甚至可以為 GPU 提供接近 100GB 的顯存空間:

既然有了這麼充裕的內存,我們當然要按照蘋果宣傳的那樣,狠狠運行一下那些以前跑不了的大規模本地 AI 模型了。
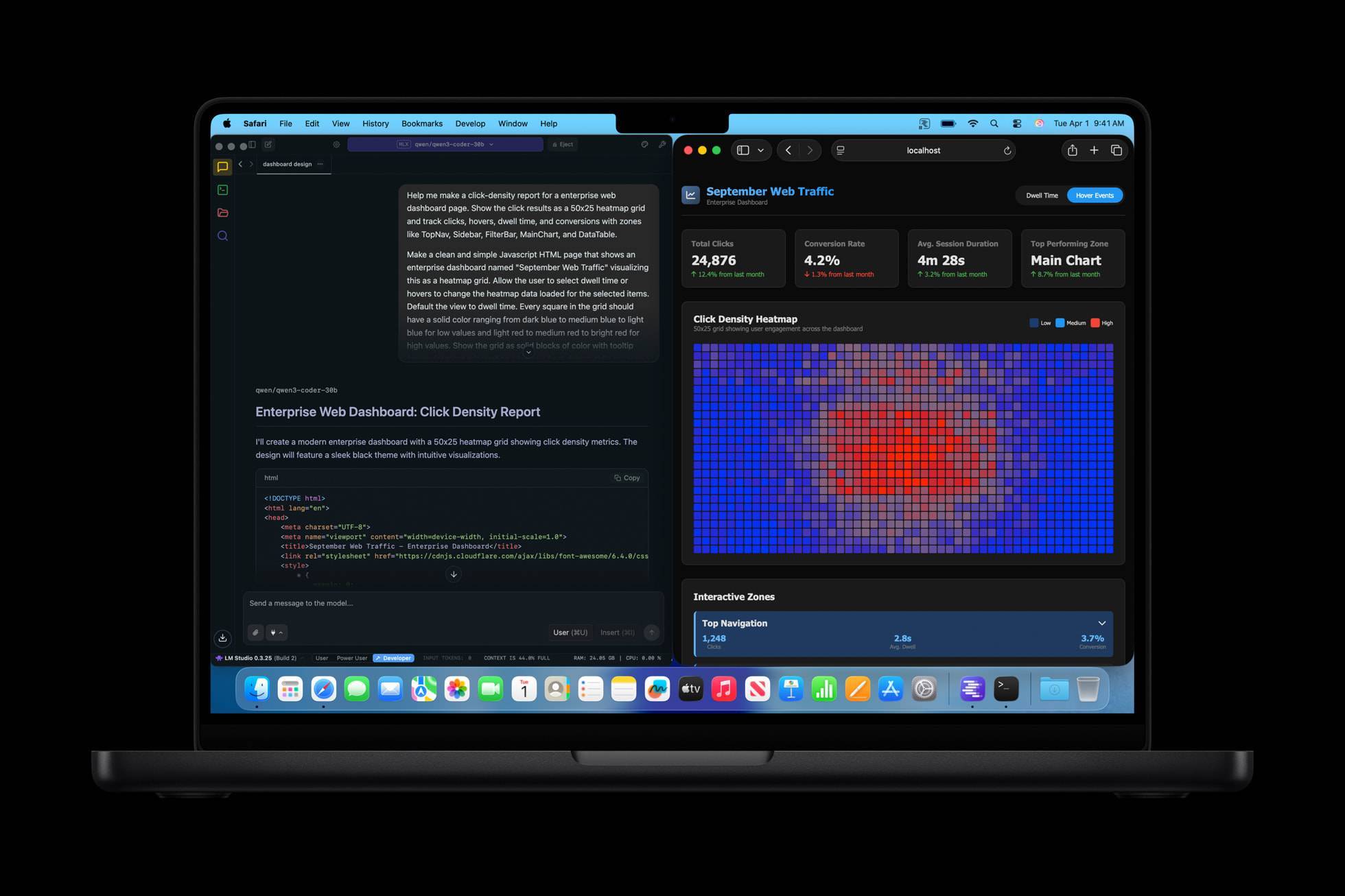
在 llmfit 中可以看到:一塊 128GB 的 M5 Max,對於所有不超過 125b 的模型都可以「順跑」(perfect)。
直到 220b 以上的 MiniMax M2.5、Qwen3 和 DeepSeek v2.5 等等,纔會變成「勉強能跑」(marginal):
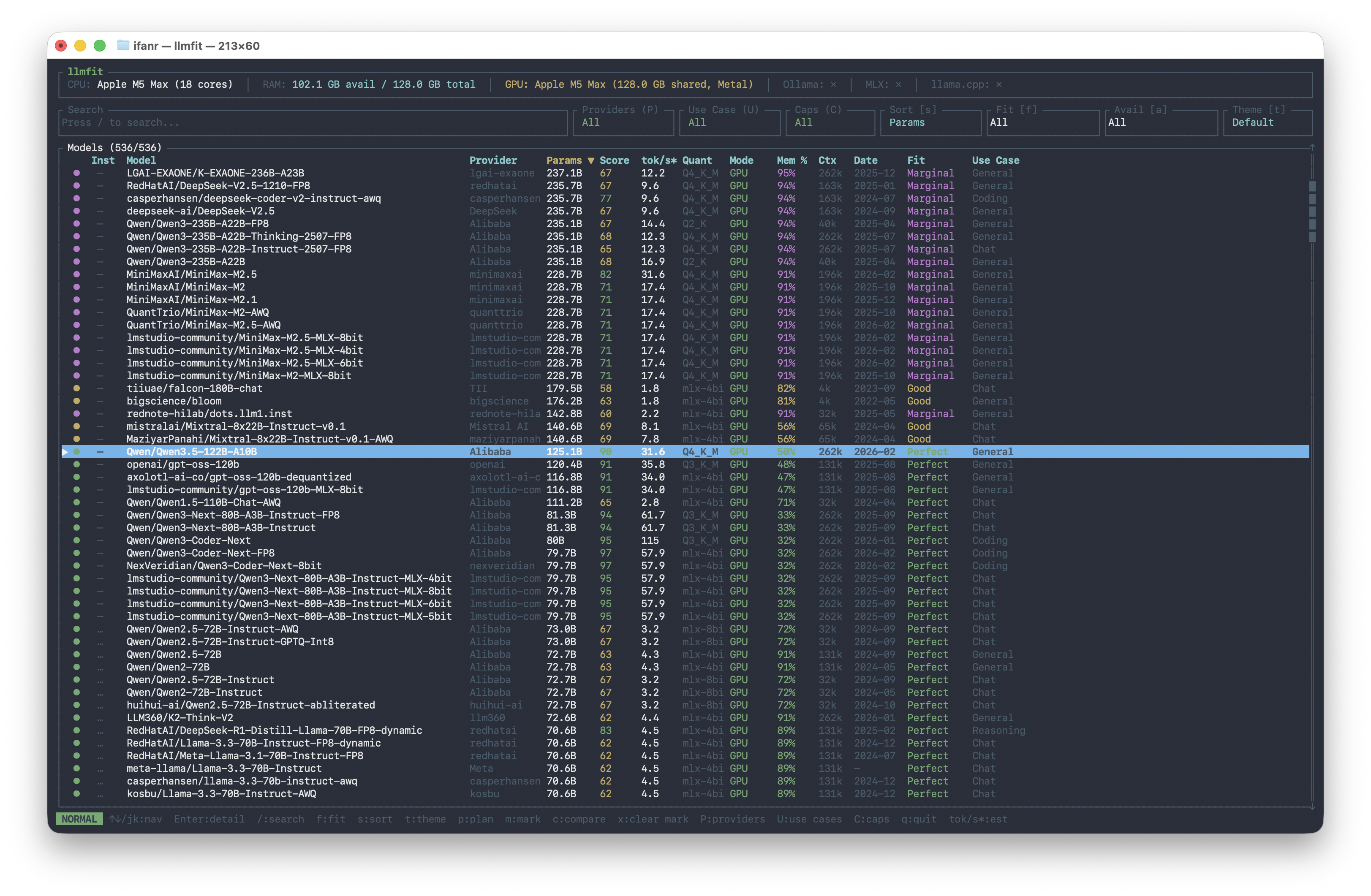
▲ M5 Max 128GB
相比之下,32GB 內存的 M1 Max 用 llmfit 查一下,最多也就只能跑一跑 2 或 4bit 量化 35b 左右的模型了:
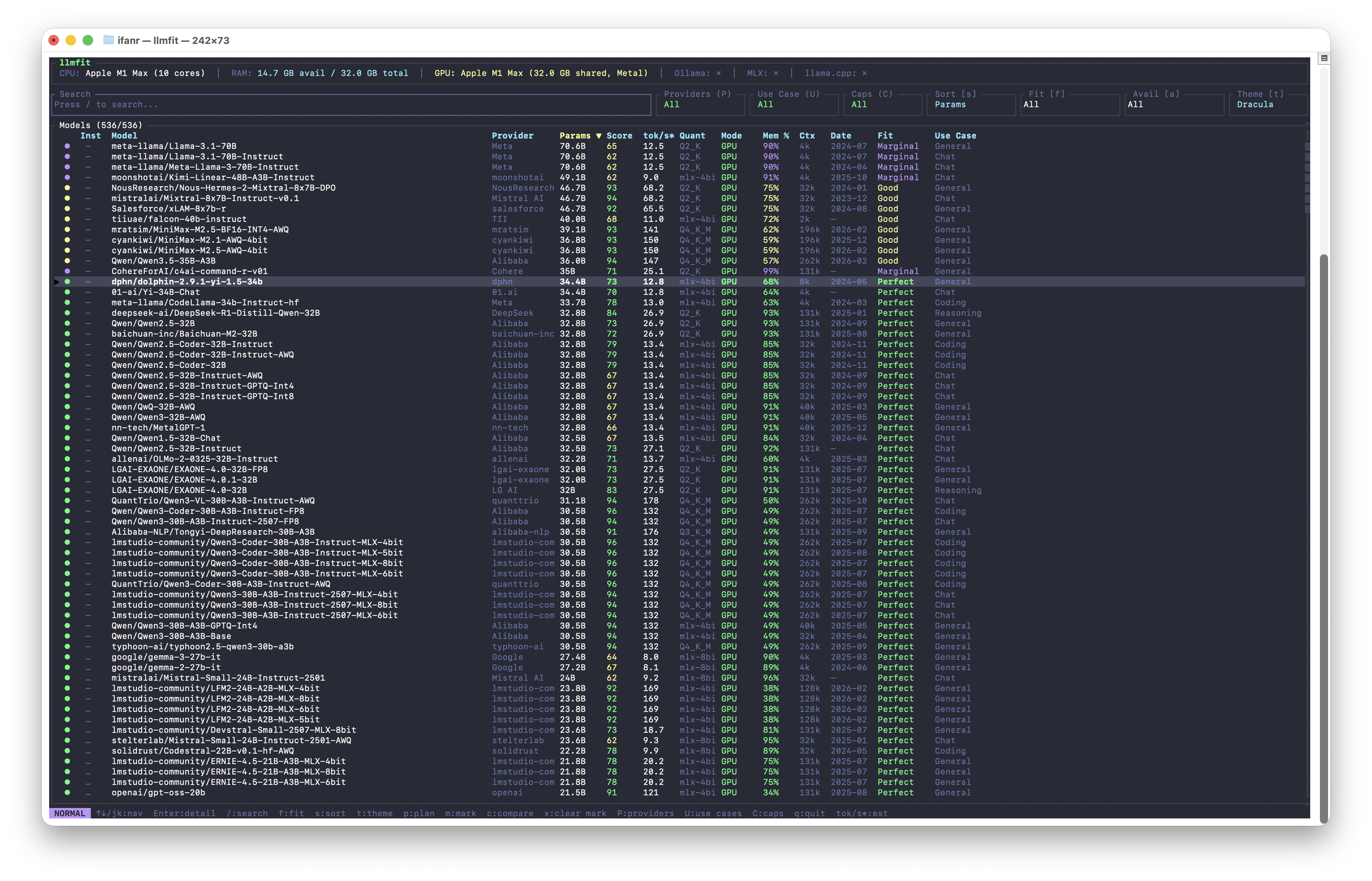
▲ M1 Max 32GB
考慮到部署的便捷程度,以及上下文理解的空間,我們選擇通過 LM Studio 測試 qwen3.5-35b-a3b,以及支持 MLX 的 qwen3-next-80b,兩者均為 8-bit 量化的 MoE 模型:
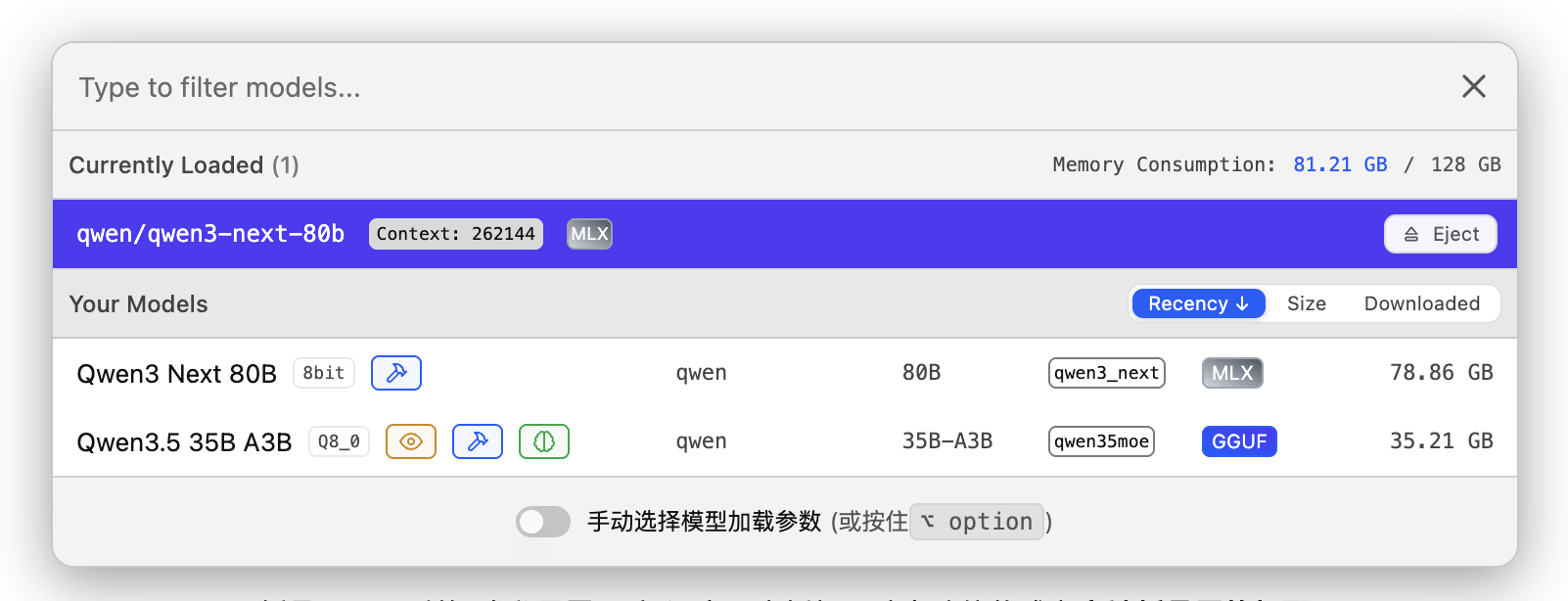
對於 qwen3.5-35b-a3b 這種「總量和推理數量都不大」的 MoE 模型來說,M5 Max 經常是還沒來得及熱起來就跑完了:
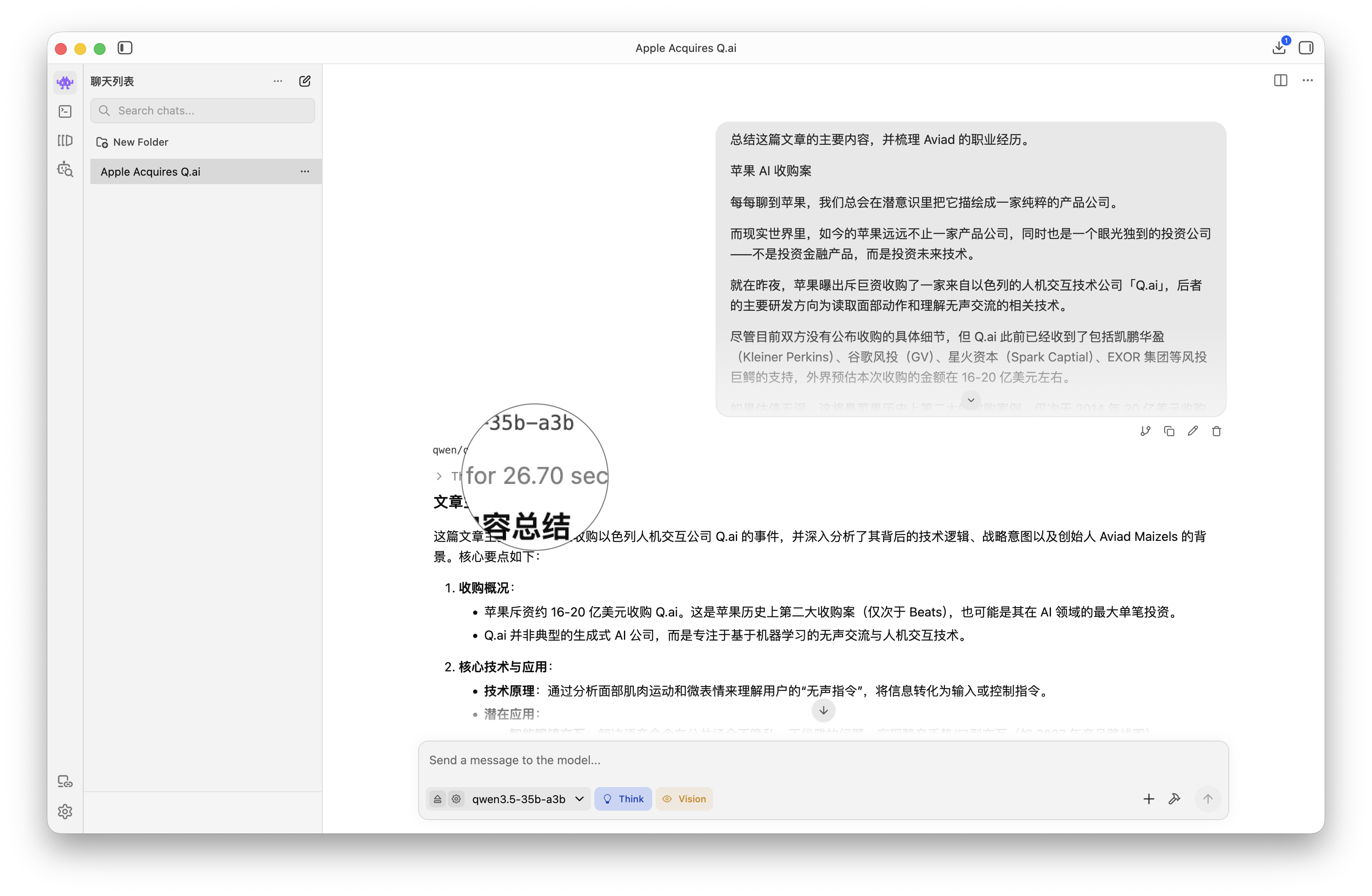
▲ qwen3.5-35b-a3b
即使面對接近 3000 字的原文材料,在手動拉滿模型 token 上限之後,M5 Max 在每一輪重寫和仿寫中的首詞元響應速度都在 1.7 秒左右,即 TTFT 約 1.7s、TPOT 約 65tps,累計思考和撰寫的字數近萬也沒有溢出。
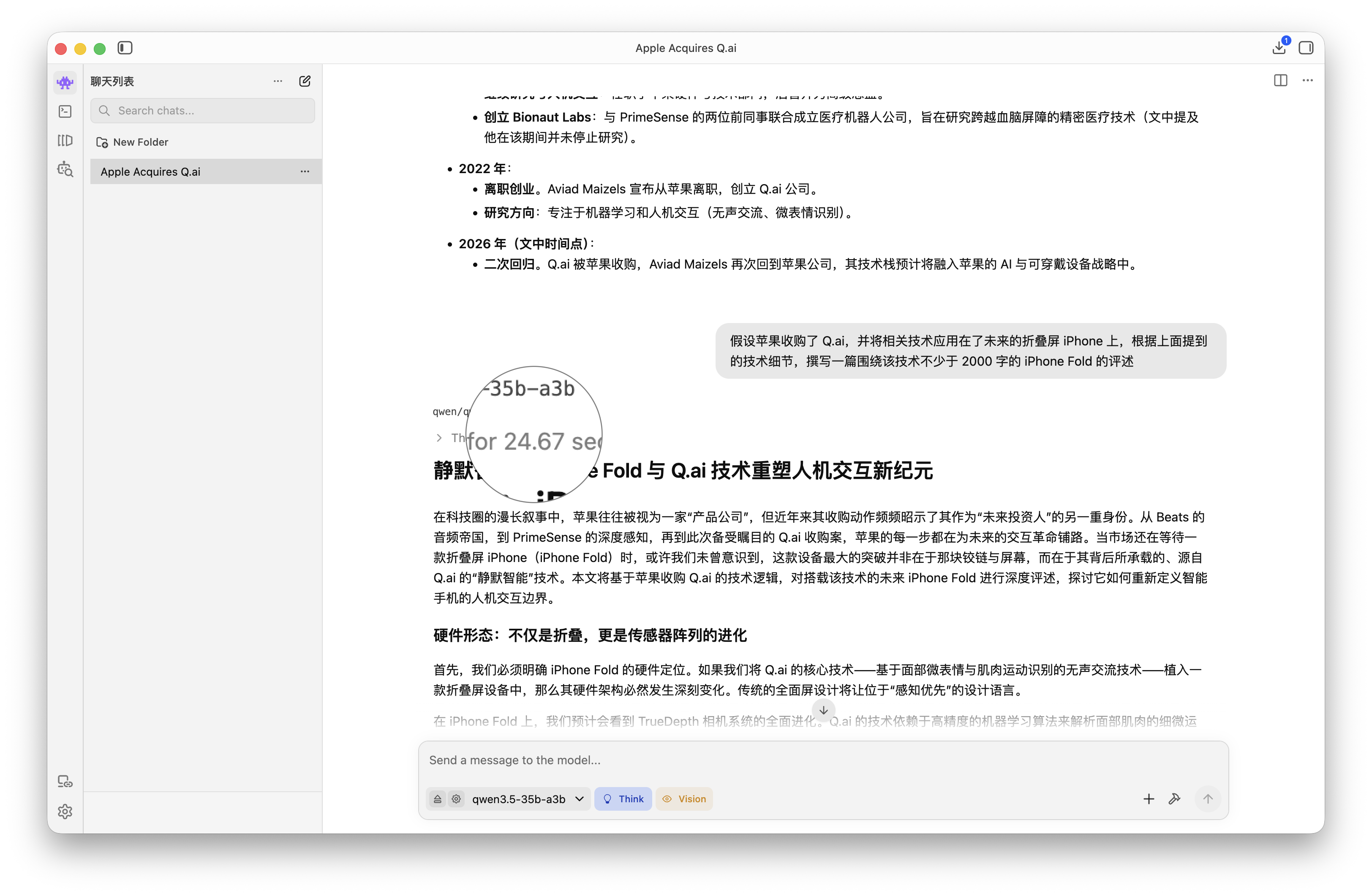
▲ qwen3.5-35b-a3b
而有 MLX 優化、8-bit 量化且參數量更大的 qwen3-next-80b 在 M5 Max 上更是如虎添翼。
雖然需要忽略內存警告手動加載接近 80GB 的模型,但是運行效果的確非同凡響:
在 qwen3.5-35b-a3b 中需要思考近 30 秒的相同提示詞,輸給 qwen3-next-80b 則是接近秒出,TTFT 約 3s、TPOT 約 72tps。
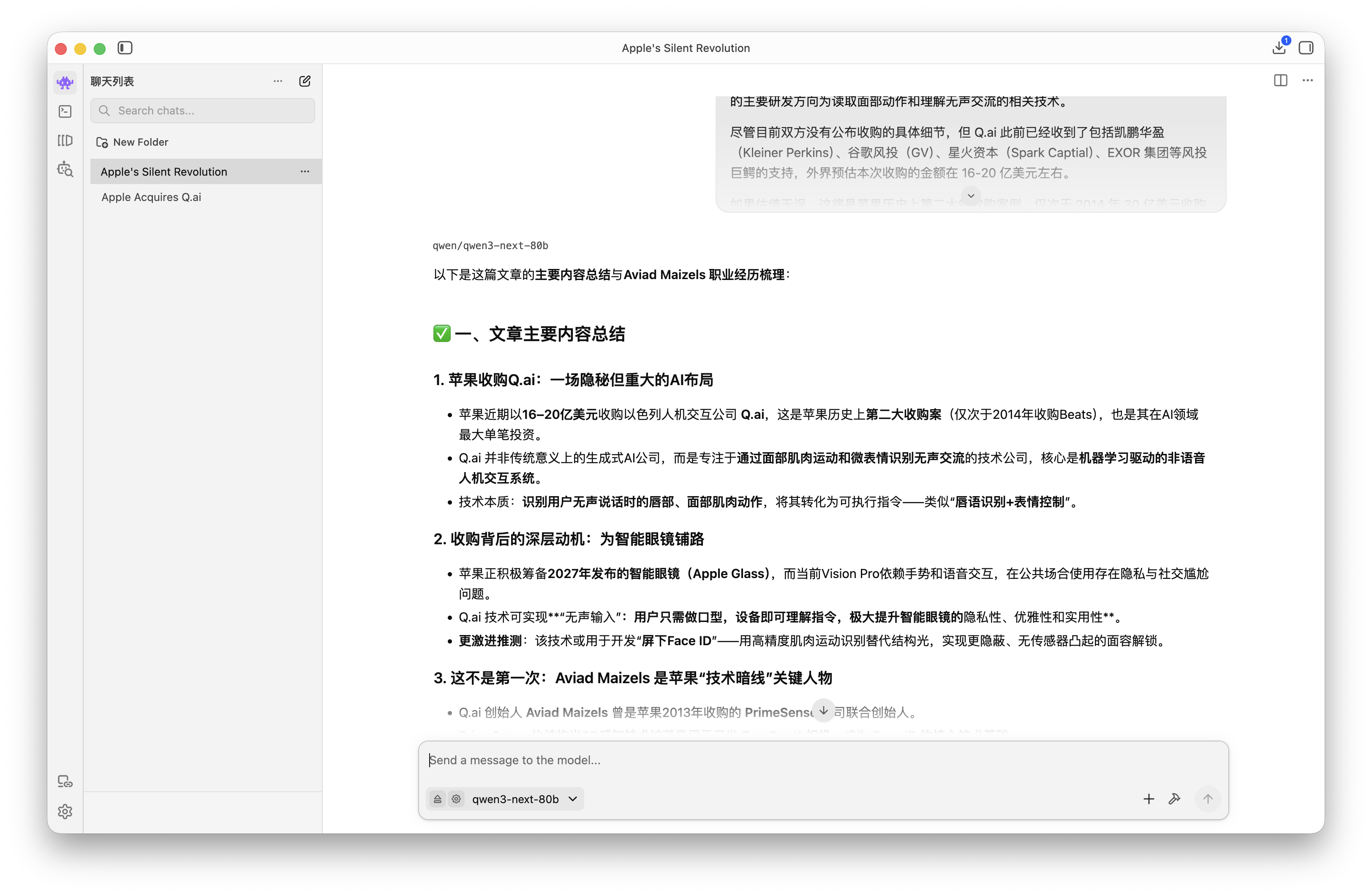
▲ qwen3-next-80b
這一方面是因為 80b 的參數相比 3b 活躍參數本來就夠大,更因為這是基於蘋果開源的 MLX 框架優化的版本,可以最大發揮出 Apple Silicon 的優勢。
除了 MoE 模型之外,M5 Max 面對類似 Llama 3.3 這樣的稠密模型的表現怎麼樣呢?

▲ 圖|Tom’s Guide
儘管 8-bit 量化的 Llama 3.3 70b 模型體積只有約 75GB,但 128k 上下文所需的巨大 KV cache 還是會溢出,導致 LM Studio 無法加載。
換成體積更小的 Llama 3.3 70b Q4_K_M 之後 M5 Max 終於可以正常加載了,執行上述提示詞後系統負載約為 95GB,生成速度 9.95 token/s:

換句話說,在面對類似規模的稠密模型的時候,還是需要更大內存的 M3 Ultra 上場。
不過我們本次在 M5 Max 上觀測到的最大佔用,反而不是稠密的 Llama 3.3,而是跑在 Msty Studio 裏面的 deepseeek-r1:
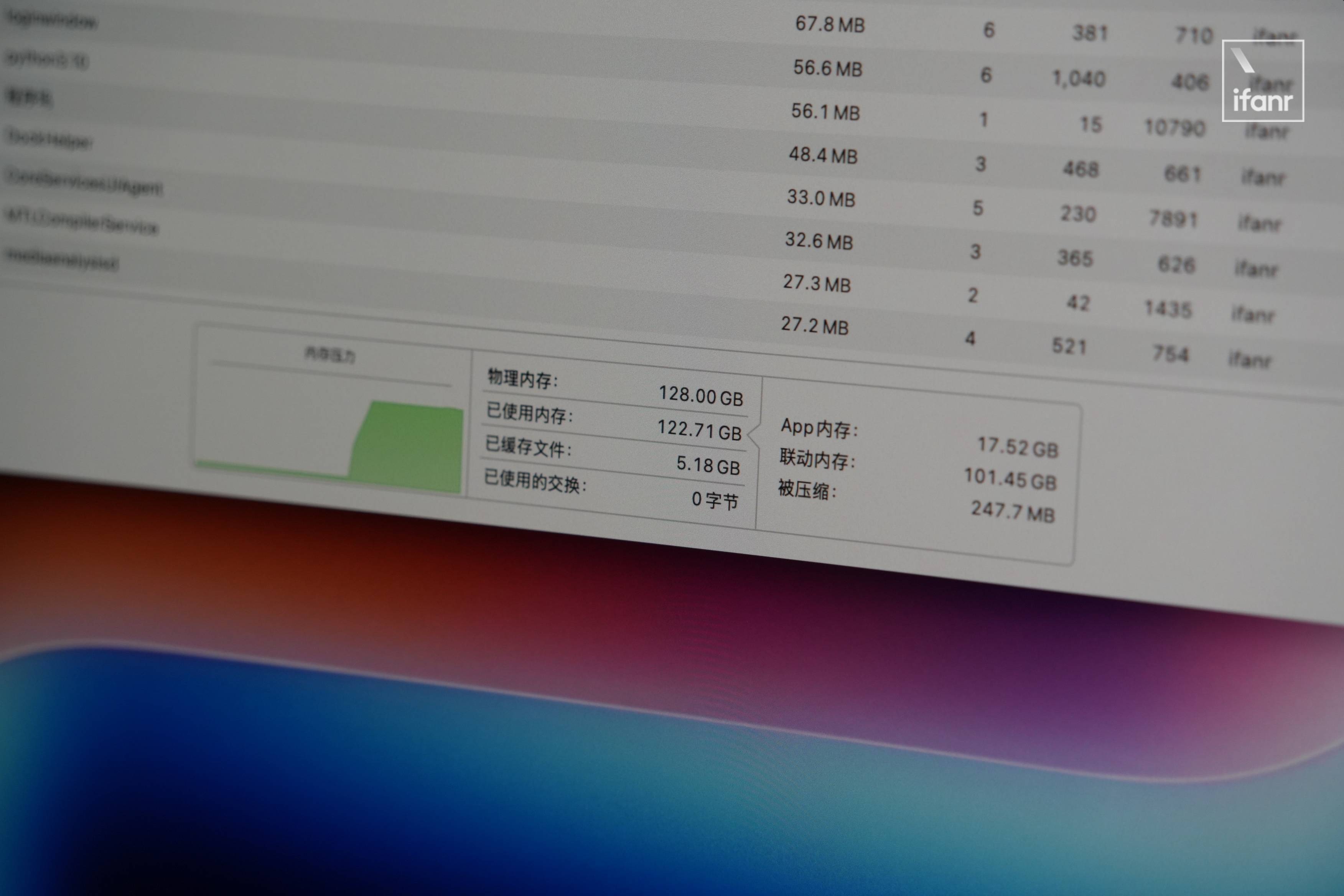
在 Msty Studio 中,我們加載了一個 75GB 的 deepseek-r1 70b-llama-distill-q8_0,花兩分鐘佔用 122GB 內存給你寫了首俳句:

▲ deepseek-r1 70b-llama-distill-q8_0
這還僅僅是本地語言類模型的成績,即使在一些傳統性能項目中,M5 Max 的表現同樣沒有讓我們失望。
在 Cinebench 2026 中,M5 Max 最高跑出了 GPU 79295 分的成績,相比 M4 Max 提升了超過 15%,和目前規模最大的 M3 Ultra 僅差 5% 左右。
▲ 連續烤機後下降到了 7.7 萬分左右
而這樣的成績放到遊戲中是什麼樣呢?
我們按照與去年評測標準版 M5 時相同的參數,重新在 M5 Max 上玩了一會《賽博朋克 2077》。
在使用默認「for this mac」預設時,M5 Max 可以穩定在 59 幀左右,相比標準版 M5 不僅預設分辨率更高、細節更多,幀率更是直接翻倍:

在手動優化一下設定(高細節 1.5K 光追 FSR MetalFX 超分和幀生成)之後,M5 Max 則可以在風扇拉滿的情況下穩定住密集場景 50~60 幀——

這個成績距離遊戲本當然差不少,但 2077 本來就是個非常龐大的遊戲,M5 Max 能夠在不插電的 14 寸機身裏面跑出這樣的效果,還是很讓人驚喜的。
至於其他體量更小、優化更好的遊戲,比如《控制:終極合輯》、《逃離鴨科夫》等等,只要不亂改設定,M5 Max 基本都可以穩住 60 幀一根線。
無論是 AI 工作流,還是打遊戲,這款 M5 Max 芯片的 MacBook Pro,是一隻毫無疑問的澎湃猛獸。
迄今最好的蘋果螢幕
除了 M5 Pro/Max 之外,今年春季發布會上的另一個「Pro 級」新品則是千呼萬喚始出來的新一代 Studio Display。
更具體一點說,是新款 Studio Display 和 Studio Display XDR。

在 Pro Display XDR 下架之後,Studio Display XDR 接過了它的衣鉢,憑藉着 24,999 的起售價成為了目前蘋果專業級顯示器的門面擔當。
而我們在上手 Studio Display XDR 之後的初體驗也和 Apple 活動現場一致:
螢幕面積縮小的影響並不明顯,反而是 ProMotion 從第一秒就抓住了我們的目光——
得益於一塊 2304 分區的 mini-LED 面板,以及 1000 尼特峯值 SDR 亮度、2000 尼特峯值 HDR 亮度,說它「不抓人眼球」是不可能的。

▲ mini-LED 的光暈現象只在非常極限的情況下可見
在「老生常談」的廣色域 HDR 內容創作之外,Studio Display XDR 當然也是影音娛樂的一把好手。
尤其是當你手頭有一些支持 HDR 效果的「歐美大片」的話,用 MacBook Pro 搭配 Studio Display XDR 的體驗,在目前的蘋果產品線中是無出其右的:

而相同的評價對於今年的新款 Studio Display 同樣適用。
實際上,除了 ProMotion、峯值亮度和充電功率之外,Studio Display 在螢幕面板素質方面,完全可以看齊新的 Studio Display XDR ——
畢竟蘋果事先打好了招呼:5K 120Hz 可不是隨便什麼處理器都能帶動的,如果你的 Mac 使用的是 M1 全系、M2 或 M3 標準版的話,插上 Studio Display XDR 最高只能以 60Hz 顯示。
這也符合我們拿到 Studio Display XDR 的體驗結果。
甚至如果你的 macOS 版本太老,即使插上顯示器能夠充電,也是無法輸出畫面的。

有意思的是,愛範兒在發布會現場和蘋果的工作人員交流時,他們提到:兩款顯示器都搭載了 iPhone 的 SoC 芯片。
而外媒 MacRumors 通過解包兩款新顯示器的固件更新代碼,發現蘋果分別為兩款新顯示器裝上了 A19 和 A19 Pro 處理器——

不出意料,這是為了 5K 畫面解碼、背光控制、Center Stage 攝像頭以及其他顯示器功能準備的。
但這也讓蘋果的「處理器笑話」越來越多了:
2026 年剛開頭,你就可以買到 M5 芯片的 iPad Pro、A18 Pro 芯片的 MacBook Neo,以及 A19 Pro 芯片的顯示器。
總的來說,今年的 Studio Display XDR 是一次非常及時的更新。
它最重要的意義,在於補全了蘋果專業級產品線中 ProMotion 的缺口,也是讓產品聯動的體驗更加無縫。

當蘋果開始談論 AI
這次的春季發布會上,蘋果除了改變之前的發布模式之外,也開始大大方方地談論起了 AI ——
這次的 AI 不是一鴿再鴿的 Apple Intelligence,也不是蘋果曾經反覆強調的 Machine Learning,就是簡單直白的通用人工智能。
而從目前的產品表現來看,當蘋果開始談論 AI,它確實是準備好了。
早在蘋果 2020 年轉向 Apple Silicon 與統一內存架構時,它大概率沒有想到如今的 AI 模型需求大爆發,以及隨之而來的內存危機。
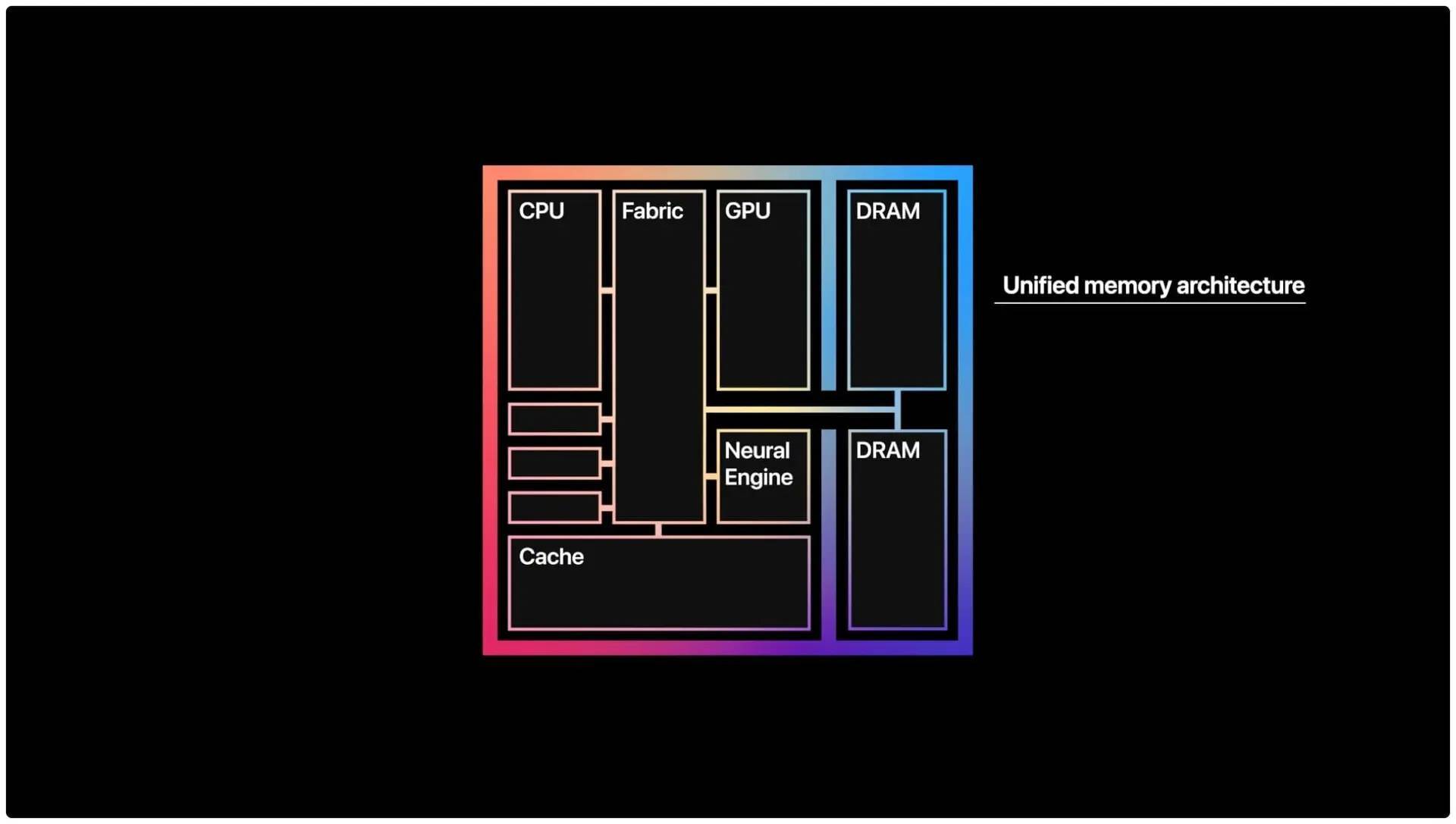
最直白的例子,莫過於這塊 M5 Max 上的 128GB 統一內存:
如果只看消費級 DDR5 6400 內存,想要買足 128GB 的確不是難事,所需開銷僅僅一萬元左右,但無論如何也達不到 614GB/s 的帶寬。
如果想要用顯卡湊夠 128GB 的 VRAM,在專業卡買不到的前提下,你需要買整整五塊 RTX 5090D,這還是忽略顯卡間通訊延遲之後的結果。
這種時候,有本地 AI 需求的小型企業團隊、個人開發者、AI 從業者等等就會陷入兩難的境地:
要麼用有限的預算,在搭建 PC 時將預算分割到內存、顯卡、CPU、硬盤等等上面,稀釋整體的計算性能。
要麼咬緊牙關加預算,投入幾十乃至上百萬元,進入自構服務器的領域。

▲ 圖|Servermall
這時,一台不到 6 萬元,自帶 128GB 高帶寬內存、頂級 HDR 螢幕和揚聲器,以及 8TB 硬盤的 MacBook Pro,反而變成了個人和工作室用戶的終極性價比之選。

甚至如果你用不到上面那些「外設」,或者本地 AI 需求不高的話,還可以退而求其次選擇 Mac Studio 或者 Mac mini ——
而後者已經在啱啱的「龍蝦潮」中迎來了一波自己的春天。

▲ 圖|Apple Must
雖然 Apple Intelligence 引人發笑,但 Apple Silicon 和統一內存在這個「大 AI 時代」的潛力,才只露出冰山一角。